多层感知机(MLP,Multilayer Perceptron)También llamado 人工神经网络(ANN,Artificial Neural Network), además de las capas de entrada y salida, puede haber múltiples capas ocultas en el medio.
Directorio de artículos
1.1 Capa oculta
Supere las limitaciones de los modelos lineales agregando una o más capas ocultas a la red, lo que le permite manejar tipos más generales de relaciones funcionales, la implementación más simple es apilar muchas capas completamente conectadas. Cada capa da salida a las capas superiores hasta que se genera la salida final.
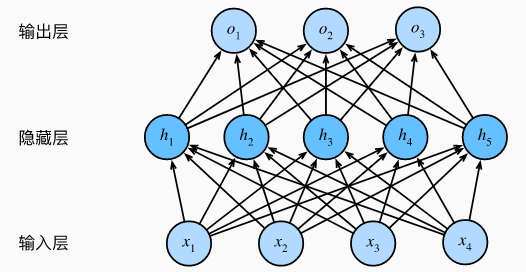
Un perceptrón multicapa de una sola capa oculta con 5 unidades ocultas, la capa de entrada no implica ningún cálculo, por lo que usar esta red para generar la salida solo necesita implementar el cálculo de la capa oculta y la capa de salida. Por lo tanto, el número de capas en este perceptrón multicapa es 2. Tenga en cuenta que ambas capas están completamente conectadas. Cada entrada afecta a cada neurona de la capa oculta, y cada neurona de la capa oculta afecta a cada neurona de la capa de salida.
Para realizar el potencial de la arquitectura multicapa, necesitamos un elemento clave adicional: aplicar una no linealidad a cada unidad oculta después de una transformación afín, 激活函数(activation function)la salida de la función de activación se llama 活性值(activations). En general, con una función de activación, ya no es posible degenerar nuestro perceptrón multicapa en un modelo lineal.
1.2 Función de activación
激活函数(activation function)Al determinar si las neuronas deben activarse calculando una suma ponderada y agregando un sesgo, transforman la señal de entrada en una operación diferenciable de salida., la mayoría de las funciones de activación son no lineales. Dado que las funciones de activación son la base del aprendizaje profundo, a continuación se presentan brevemente algunas funciones de activación comunes.
1.2.1 Función ReLU
La función de activación más popular se 修正线性单元(Rectified linear unit,ReLU)debe a que es simple de implementar y se desempeña bien en varias tareas de predicción. ReLU proporciona una transformación no lineal muy simple. Dado un elemento x, la función ReLU se define como el valor máximo de ese elemento con 0:
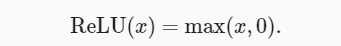
En términos sencillos, la función ReLU mantiene solo los elementos positivos y descarta todos los elementos negativos al establecer el valor de actividad correspondiente en 0. Para obtener una sensación intuitiva, podemos dibujar un gráfico de la función. Como puede ver en la figura, la función de activación es lineal por partes.
%matplotlib inline
import torch
from d2l import torch as d2l
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.relu(x)
d2l.plot(x.detach(), y.detach(), 'x', 'relu(x)', figsize=(5, 2.5))
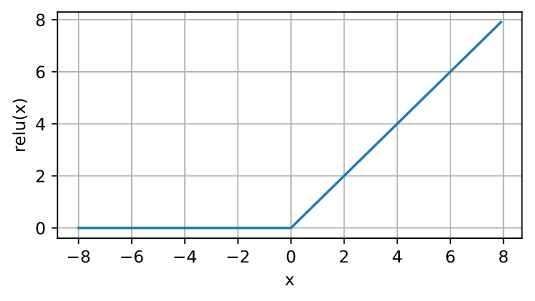
Cuando la entrada es negativa, la derivada de la función ReLU es 0, y cuando la entrada es positiva, la derivada de la función ReLU es 1.Tenga en cuenta que cuando el valor de entrada es exactamente igual a 0, la función ReLU no es diferenciable. A continuación se muestra la derivada de la función ReLU.
y.backward(torch.ones_like(x), retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of relu', figsize=(5, 2.5))
La razón para usar ReLU es que realiza la derivación particularmente bien: deja que el parámetro desaparezca o deja que el parámetro pase. Esto hace que la optimización funcione mejor y ReLU alivia el problema del gradiente de fuga que afectaba a las redes neuronales anteriores.
1.2.2 función sigmoidea
Para una entrada cuyo dominio está en R, la función sigmoidea transforma la entrada en una salida en el intervalo (0, 1). Por lo tanto, un sigmoide a menudo se llama 挤压函数(squashing function): comprime cualquier entrada en el rango (-inf, inf) a algún valor en el intervalo (0, 1):
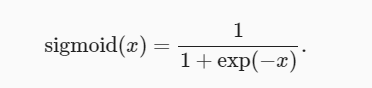
En las primeras redes neuronales, los científicos estaban interesados en neuronas biológicas ” o “no disparadas” . Por lo tanto, los pioneros en este campo se remontan a McCulloch y Pitts, los inventores de las neuronas artificiales, que se centraron en la unidad de umbral. Una unidad de umbral toma el valor 0 cuando su entrada está por debajo de un determinado umbral y el valor 1 cuando su entrada supera el umbral.
La función sigmoidea fue una elección natural cuando las personas se enfocaron en el aprendizaje basado en gradientes porque es una aproximación de unidad de umbral suave y diferenciable.
y = torch.sigmoid(x)
d2l.plot(x.detach(), y.detach(), 'x', 'sigmoid(x)', figsize=(5, 2.5))
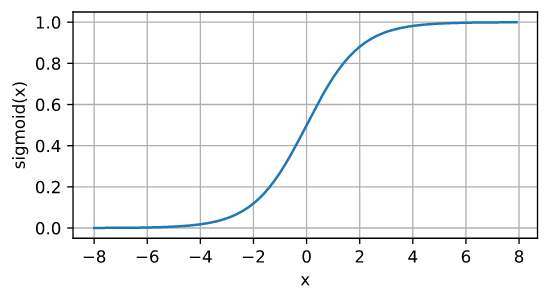
La derivada de la función sigmoidea es la siguiente fórmula: A
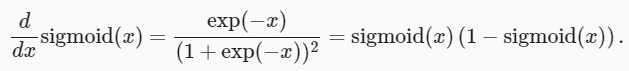
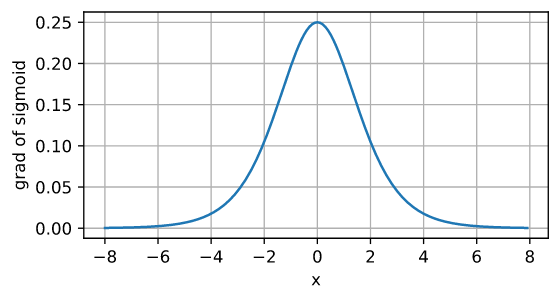
continuación se muestra la gráfica de la derivada de la función sigmoidea. Tenga en cuenta que cuando la entrada es 0, la derivada de la función sigmoidea alcanza un valor máximo de 0,25; mientras que la entrada está más alejada de 0 en cualquier dirección, la derivada está más cerca de 0.
# 清除以前的梯度
x.grad.data.zero_()
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of sigmoid', figsize=(5, 2.5))
1.2.3 función tanh
Similar a la función sigmoidea, la función tanh (tangente hiperbólica) también puede comprimir su entrada al intervalo (-1, 1). La fórmula para la función tanh es la siguiente:
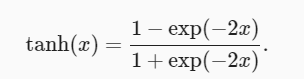
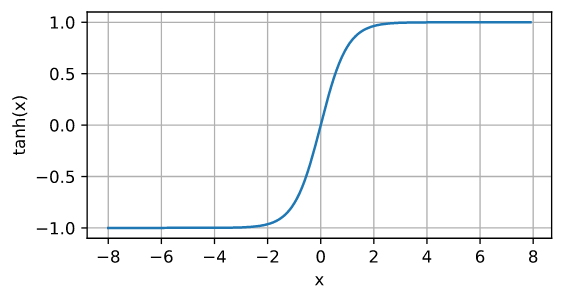
A continuación dibujamos la función tanh. Tenga en cuenta que la función tanh se aproxima a una transformación lineal cuando la entrada es alrededor de 0.La forma de la función es similar a la función sigmoidea, excepto que la función tanh es simétrica con respecto al origen del sistema de coordenadas.。
y = torch.tanh(x)
d2l.plot(x.detach(), y.detach(), 'x', 'tanh(x)', figsize=(5, 2.5))
La derivada de la función tanh es:
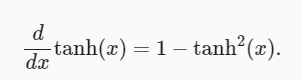
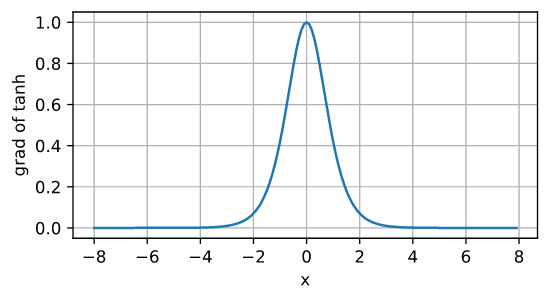
a medida que la entrada se acerca a 0, la derivada de la función tanh se acerca al valor máximo de 1. Similar a lo que vimos en la imagen de la función sigmoidea, cuanto más lejos esté la entrada del punto 0 en cualquier dirección, más cerca estará la derivada de 0.
# 清除以前的梯度
x.grad.data.zero_()
y.backward(torch.ones_like(x),retain_graph=True)
d2l.plot(x.detach(), x.grad, 'x', 'grad of tanh', figsize=(5, 2.5))
1.3 Implementación concisa
import torch
from torch import nn
from d2l import torch as d2l
npx.set_np()
En comparación con la implementación ordenada de la regresión softmax, la única diferencia es que agregamos 2 capas completamente conectadas (anteriormente solo agregamos 1 capa completamente conectada). La primera capa es la capa oculta, que contiene 256 unidades ocultas y utiliza la función de activación de ReLU. La segunda capa es la capa de salida.
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights);
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss()
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
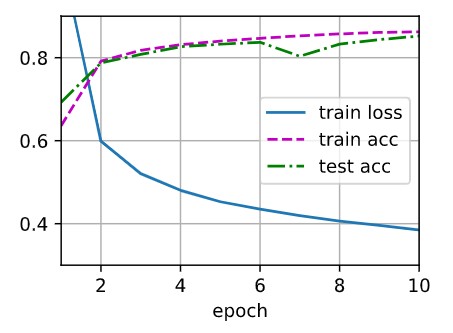
Para el mismo problema de clasificación, la implementación del perceptrón multicapa es la misma que la implementación de la regresión softmax, pero la implementación del perceptrón multicapa agrega una capa oculta con una función de activación.