Incrustación de palabras
prefacio
Ya hemos aprendido sobre la red neuronal convolucional de CNN. En este artículo, aprenderemos sobre la codificación de vocabulario como Word Embedding.
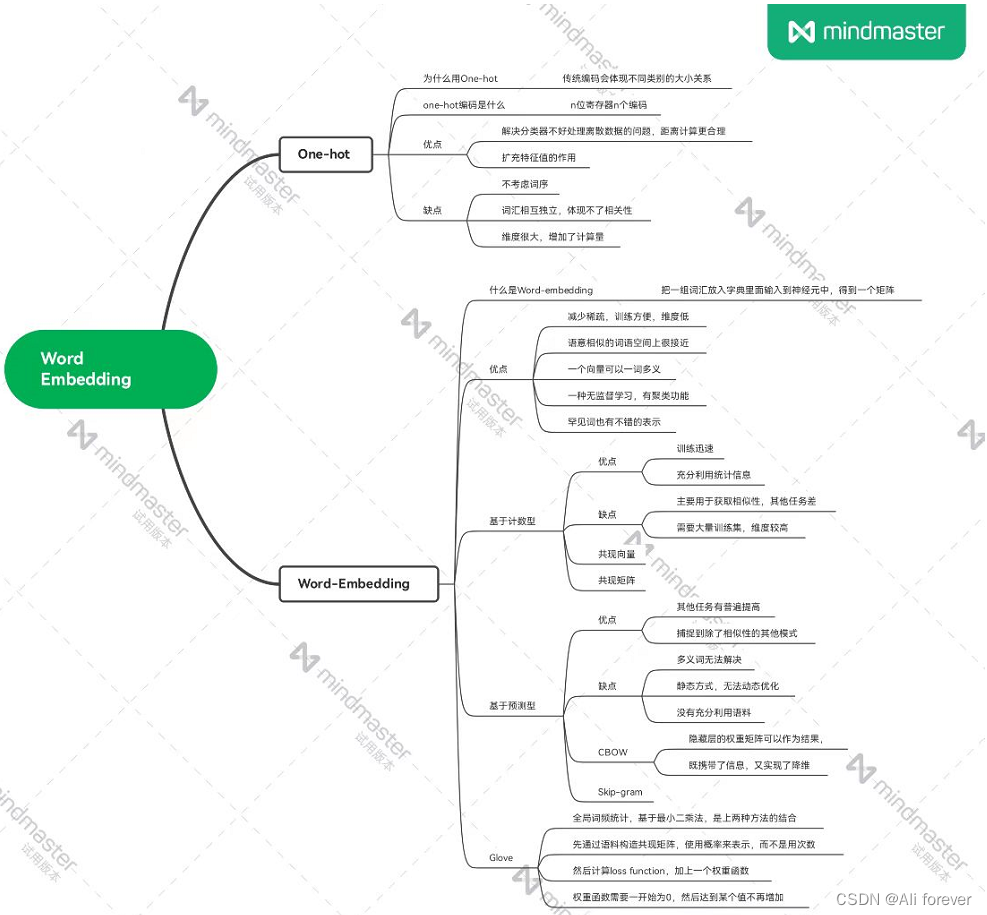
1. Codificación en caliente
1. ¿Por qué utilizar la codificación one-hot?
En primer lugar, tenemos que saber cómo es el método de codificación tradicional. La codificación tradicional se realiza contando el número de ocurrencias del tipo, es decir, el número de ocurrencias de la categoría A es m, y el número de ocurrencias de la categoría B es n, luego se codifican como m y n respectivamente. Esta codificación puede conducir a otras categorías al calcular el promedio ponderado, lo que reflejará la relación de tamaño de las diferentes categorías y el error será grande. Por lo tanto, debemos adoptar un nuevo método de codificación: codificación one-hot (codificación one-hot)
2. ¿Qué es la codificación one-hot?
Use registros de estado de N bits para codificar N estados, cada estado tiene su propio bit de registro independiente y, en cualquier momento, solo un bit es válido.

3. Ventajas y desventajas de la codificación one-hot
- ventaja:
- Se resolvió el problema de que el clasificador no manejaba bien los datos discretos. Usando la codificación one-hot, el valor de la característica discreta se extiende al espacio euclidiano, y un cierto valor de la característica discreta corresponde a un cierto punto en el espacio euclidiano. El uso de codificación one-hot para características discretas hará que el cálculo de la distancia entre características sea más razonable
- Hasta cierto punto, también desempeña el papel de funciones de expansión.
- defecto:
- Es un modelo de bolsa de palabras que no considera el orden entre palabras.
- Asume que las palabras son independientes entre sí y no pueden reflejar la similitud entre las palabras.
- La dimensión de codificación one-hot de cada palabra es el tamaño de todo el vocabulario. La dimensión es muy grande y la codificación es escasa, lo que aumentará el costo computacional.
Dos, incrustación de palabras (incrustación de palabras)
1. ¿Qué es la incrustación de palabras?
La palabra se considera como la unidad más pequeña, y una determinada palabra en el espacio de texto se mapea o incrusta en otro espacio vectorial numérico a través de un método determinado.
La entrada de Word Embedding es un conjunto de palabras que no se superponen en el texto original. Ponerlas en un diccionario, por ejemplo: ["gato", "comer", "manzana"], se puede usar como entrada.
La salida de Word Embedding es la representación vectorial de cada palabra, que se convierte en una matriz.

2. Ventajas de la incrustación de palabras:
- En comparación con el vector disperso de alta dimensión en caliente, la dimensión de incrustación es baja y el vector continuo es conveniente para el entrenamiento del modelo;
- Las palabras con semántica similar también serán similares en el espacio vectorial
- Un vector puede codificar polisemia (la ambigüedad debe manejarse por separado);
- Naturalmente, tiene el efecto de agrupamiento, que es una especie de aprendizaje no supervisado.
- Las palabras raras también pueden aprender representaciones decentes.

3. Incrustación de palabras basada en recuento
1. Ventajas y desventajas de Word Embedding basado en conteo
- ventaja:
- entrenando muy rápido
- Puede utilizar eficazmente la información estadística.
- defecto:
- Se utiliza principalmente para obtener similitud entre palabras (otras tareas funcionan mal)
- Dado un gran conjunto de datos, la importancia no es proporcional al peso.
2. Vector de co-ocurrencia (vector de co-ocurrencia)
Palabras similares tienden a tener contextos similares y podemos construir un conjunto de algoritmos para implementar la construcción de características basadas en el contexto.
Cuando establecemos el tamaño de la ventana de contexto en 2, y el rango es de dos palabras antes y después, entonces para la palabra tal, su ventana de contexto es la parte verde de abajo.

Porque Él no es perezoso. Él es inteligente. Él es inteligente.
Tomando la palabra Él como ejemplo, el número de palabras que co-ocurren con está en toda la ventana de contexto en el léxico es el número de está en la matriz de co-ocurrencia
Para este corpus, la matriz de co-ocurrencia debe ser:
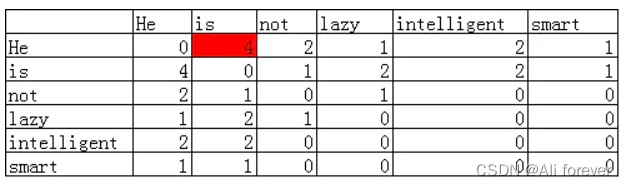
La mayor ventaja de la matriz de co-ocurrencia es que este método de representación retiene información semántica, por ejemplo, a través de esta representación, puede saber qué palabras están relativamente cerca y qué palabras están cerca está relativamente lejos.
4. Incrustación de palabras basada en predicción
1. Ventajas y desventajas de Word Embedding basado en predicciones:
- ventaja:
- Capacidad para mejorar en general en otras tareas.
- Capaz de capturar patrones complejos más allá de la similitud léxica
- defecto:
- Dado que las palabras y los vectores tienen una relación de uno a uno, el problema de las palabras polisémicas no se puede resolver.
- Word2vec es un método estático, aunque es versátil, no se puede optimizar dinámicamente para tareas específicas.
- No aprovechar al máximo todo el corpus y hay desperdicio
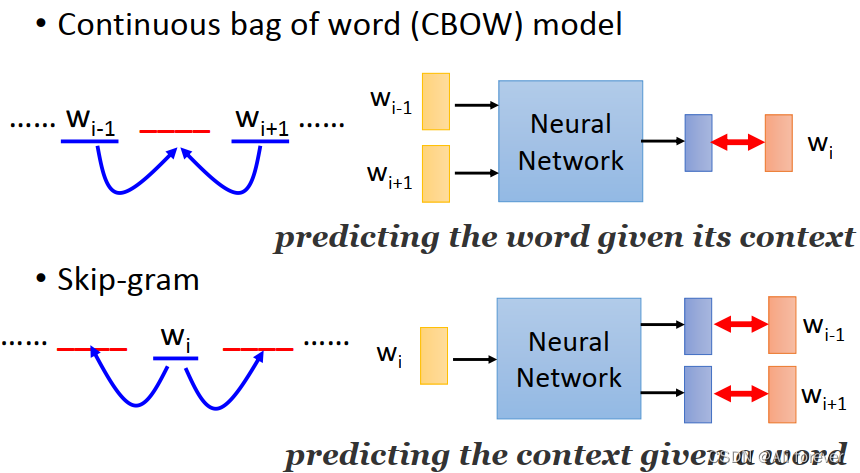
2.CBOW (sigue la bolsa de palabras)
Para este corpus, primero hacemos una codificación one-hot, y luego seleccionamos la ventana de contexto como 2, luego se genera un par de entrada y destino en el modelo

- Introduzca los dos vectores de cuatro dimensiones generados en la red neuronal y conecte la función de activación. La función de activación se encuentra entre la capa de entrada y la capa oculta, cada vector de entrada se multiplica por una matriz de dimensiones VxN, y los vectores obtenidos se promedian en cada dimensión para obtener el peso de la capa oculta. La capa oculta se multiplica por una matriz de dimensiones NxV para obtener el peso de la capa de salida;
- Dado que la dimensión de la capa oculta se establece en la dimensión de vector de palabra comprimida ideal. En el ejemplo, supongamos que queremos comprimir la dimensión original codificada en caliente original de 4 dimensiones a 2 dimensiones, luego N = 2;
- La capa de salida es una capa softmax que combina las probabilidades de salida. La llamada función de pérdida es la diferencia entre la salida y el objetivo (la diferencia entre el vector de dimensión V de la salida y el vector codificado en caliente del vector de entrada), y el propósito de la red neuronal es minimizar esta pérdida;
- Después de la optimización, el vector N-dimensional de la capa oculta se puede utilizar como resultado de Word-Embedding.
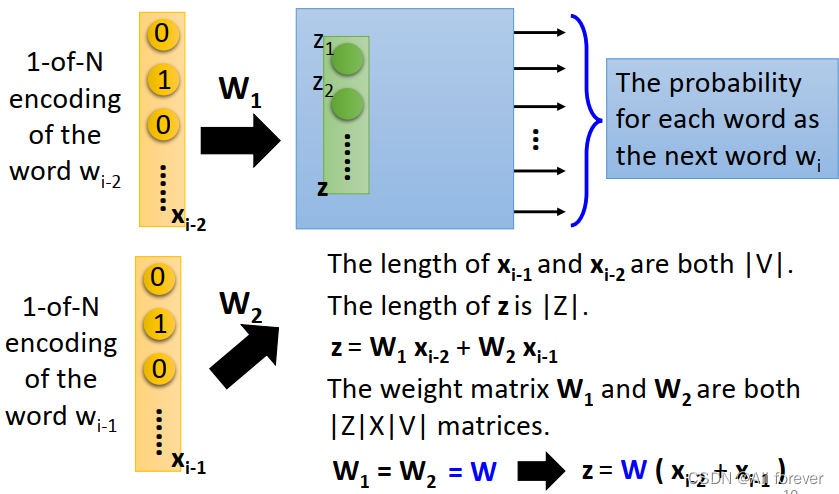
De esta forma se obtienen vectores de palabras densos que portan información de contexto y se comprimen.
3. Saltar – Gramo
Este método puede verse como una versión invertida de CBOW
5. Guante (Vectores globales para representación de palabras)
El algoritmo Glove es un algoritmo de regresión basado en estadísticas globales de frecuencia de palabras. No se basa en una red neuronal, sino en un método de regresión basado en el principio de mínimos cuadrados.
Combina las ventajas de los dos algoritmos anteriores y puede utilizar de manera efectiva la información estadística global.
Su proceso es el siguiente:
- Se construye una matriz de co-ocurrencia X de acuerdo al corpus , y se propone una función de decaimiento para calcular el peso, es decir, el peso del conteo total de las dos palabras que están más alejadas es menor.
- Para construir una relación aproximada entre el vector palabra (Word Vector) y la matriz de co-ocurrencia (Co-ocurrence Matrix), el autor del artículo propone la siguiente fórmula para expresar aproximadamente la relación entre los dos: wi T wj ˜ + bi T +
bj ˜ = log ( X ij ) w_i^T\~{w_j}+b_i^T+\~{b_j}=\log(X_{ij})wiTwj˜+biT+bj˜=lo g ( Xyo)
con T w_i^TwiTy wj ˜ \~{w_j}wj˜son vectores de palabras a resolver, bi T b_i^TbiTy bj ˜ \~{b_j}bj˜son parciales - Construye la LossFunction. La forma básica de esta función de pérdida es el MSE más simple, pero se agrega una función de peso sobre esta base,
J = ∑ i , j = 1 V f ( X ij ) ( wi T wj ˜ + bi T + bj ˜ − log ( X ij ) ) 2 J=\sum_{i,j=1}^Vf(X_{ij})(w_i^T\~{w_j}+b_i^T+\~{b_j}-\log(X_ {ij }))^2j=yo , j = 1∑Vf ( Xyo) ( wiTwj˜+biT+bj˜−lo g ( Xyo) )2
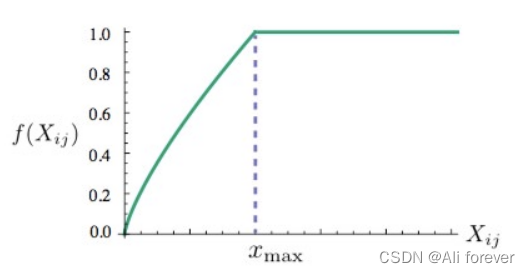
- El peso de estas palabras es mayor que el de las palabras que rara vez aparecen juntas, por lo que si esta función es una función no decreciente
- Pero no queremos que este peso sea demasiado grande (sobreponderado), y no debería aumentar después de alcanzar un cierto nivel;
- Si las dos palabras no aparecen juntas, no deberían participar en el cálculo de la función de pérdida, por lo que f ( 0 ) = 0 f(0)=0f ( 0 )=0
Resumir
Este artículo presenta Word Embedding. Espero que pueda obtener lo que desea de él. A continuación se adjunta un mapa mental para ayudarlo a recordar.