prefacio
Antes de entrar en materia, primero hablemos de algunas cosas conceptuales. En el proceso de desarrollo de software tradicional, generalmente adoptamos el proceso devops. Las etapas principales incluyen la aprobación del proyecto del producto, el análisis de los requisitos, el diseño del prototipo, el desarrollo de front-end, las pruebas, el lanzamiento continuo, la producción, la operación y el mantenimiento, etc. Entonces se introduce el concepto de mlops , es decir, modelo de desarrollo más rápido, modelo de implementación más rápido y asegurando la calidad del modelo Para lograr esto, se necesita una herramienta de modelo de implementación de administración unificada. La herramienta debe ser directamente utilizable por científicos de datos, con barreras lingüísticas mínimas y requisitos mínimos de implementación.
¿Qué significa eso? Déjeme darle un ejemplo para entender: Como el único científico de datos en la empresa, necesito ponerlo en producción después de entrenar el modelo. En este momento, necesito encontrar el producto para explicar la situación, y luego encontrar la plataforma (java) para discutir cómo implementar. De acuerdo con el método anterior, el propio autor necesita convertir directamente el modelo en código Java con la biblioteca m2cgen (solo se pueden usar una docena de modelos simples y no admite preprocesamiento), o exportar el modelo a un archivo pmml en el formato estándar pmml, y luego llamarlo a través de la biblioteca jpmml (más que m2cgen, admite la conversión directa de canalización, pero hay tantos errores y se puede encontrar un error por día ) . Los dos métodos anteriores requieren que tengas un cierto conocimiento de Java, y también pierdes mucho tiempo en encontrar errores que no te pertenecen, lo que resulta en una ralentización grave en el desarrollo de nuevos modelos.Aunque la ventaja es que no tienes que preocuparte por esto último, este método también es poco amigable para los programadores de Java, aumenta las tareas, prolonga el ciclo e incluso es propenso a errores durante la implementación (requiere mucha comunicación, después de todo, ellos no entienden).
Entonces creo que algunos veteranos han adivinado la forma correcta.Sí, es poner el modelo en la nube y usar el servicio API para llamarlo. Pero los problemas también siguen:
1. Ponlo en una gran nube que lo pague , como paddlepaddle y Huawei cloud. Los países extranjeros son más maduros en este sentido, pero creo que por cuestiones de privacidad y confidencialidad y de red, pocas personas lo elegirán. Y los principales fabricantes nacionales han desarrollado un conjunto de herramientas de implementación de tipo idiota para usted. ¿No es muy conveniente de administrar? No hay problema, tengo dinero y obstinación, pero no tengo dinero, y me es imposible solicitar a la empresa un proceso para cuidar mi negocio no rentable, creo que este método es más adecuado para esas medianas y grandes empresas con dinero.
2. Luego, inicie una implementación de servicio en el servidor localmente y escríbalo usted mismo utilizando la biblioteca de frascos de python que el 100% de ustedes buscará. El problema con este método es que usted mismo tiene que escribir una gran cantidad de código adicional, lo cual es engorroso e inconveniente de implementar. Necesita un servidor separado para implementar el entorno de python. Si acude a otras empresas para privatizar la implementación, ¿le resultará difícil instalar un entorno de python paso a paso? Entonces, desde mi punto de vista, esta es solo una solución temporal y no puede cumplir con mis requisitos para la implementación con un solo clic y la producción con un solo clic.
Entonces, después de hurgar en la biblioteca de implementación y producción de aprendizaje automático de github, finalmente vi una biblioteca de código abierto gratuita que satisface perfectamente mis necesidades y puede ejecutar incluso servidores basura: bentoml.
bentoml es muy versátil y básicamente admite marcos comunes, por lo que no hablaré de eso aquí. En resumen, es muy general y los modelos de aprendizaje profundo también se pueden implementar a través de él. A continuación, usaré el sklearn más simple para explicar.
Mientras explico la biblioteca bentoml, también compartiré mi propia solución de implementación.
Entonces el proceso es?
De hecho, lo más problemático en el proceso de búsqueda del despliegue del modelo de aprendizaje automático es que no tienes un concepto claro de qué hacer, qué es el servidor, cómo conectarme con mi modelo y cómo llamar a través de la API, y muchos artículos en Internet no hablan sobre el proceso específico .
El siguiente es un diagrama de flujo aproximado dibujado por mí mismo para comer:

Entonces, ¿cuál es el código?
El primero es la instalación, que todos deben entender.
pip install bentoml
Permítanme decirles que actualmente bentoml es compatible con python3.8 , aunque también se puede usar 3.9, pero si no está acostumbrado a win10 docker y desea ejecutar docker en un entorno de máquina virtual, asegúrese de mantener las versiones de cada paquete (python, sklearn, numpy, etc.) consistentes, de lo contrario, puede generar resultados inexactos de algunos modelos complejos (como stackingclassifier).
Luego está el primer paso , entrenar el modelo localmente a un nivel perfecto. Por supuesto, si solo quieres probar si se puede usar, se recomienda copiar el ejemplo:
from sklearn import svm
from sklearn import datasets
# Load training data
iris = datasets.load_iris()
X, y = iris.data, iris.target
# Model Training
clf = svm.SVC(gamma='scale')
clf.fit(X, y)
En este paso, escribí .ipynb en el diagrama de flujo porque personalmente me gusta usar Jupyterlab para ejecutar el modelo. Es un buen hábito copiar los códigos clave en el cuaderno y ejecutarlo durante el proceso de implementación. En resumen, debe asegurarse de que su código pueda ejecutarse sin problemas incluso como un archivo de secuencia de comandos en este paso.
El segundo paso es usar la biblioteca bentoml para empaquetar el modelo . Personalmente, no me gusta la estructura de empaque del sitio web oficial, que no favorece la operación y la comprensión. Aquí dividimos el cuerpo principal en dos partes: export.py y bento_service.py. export.py es el cuerpo principal, que cubre el entrenamiento y el empaquetado del modelo, y bento_service.py se importa a export.py como una clase para su uso. Debe colocarlos en el directorio específico del intérprete de python de conda para facilitar las operaciones posteriores de la línea de comandos .
detalles de la siguiente manera:
#export.py
import pandas as pd
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import StackingClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
from bento_service_json import IrisClassifier
from sklearn.decomposition import PCA
df_temp1 = pd.read_excel('temp1.xlsx')
df_temp2 = pd.read_excel('temp-e.xlsx')
le = preprocessing.LabelEncoder()
x = df_temp1.iloc[:,1:17]
y = le.fit_transform(df_temp1.iloc[:,17])
x1 = df_temp2.iloc[:,1:17]
y1 = le.fit_transform(df_temp2.iloc[:,17])
X_train, X_test, y_train, y_test = train_test_split(x, y,
train_size=0.8, test_size=0.2, random_state=42)
estimators = [
('GB', GradientBoostingClassifier(learning_rate=1.0, max_depth=8, max_features=0.35000000000000003, min_samples_leaf=9, min_samples_split=6, n_estimators=100, subsample=0.6500000000000001,random_state=42)),
('tree', DecisionTreeClassifier(criterion="gini", max_depth=9, min_samples_leaf=1, min_samples_split=2,random_state=42))
]
model = StackingClassifier(
estimators=estimators,stack_method='predict',final_estimator=KNeighborsClassifier(n_neighbors=3, p=2, weights="uniform")
)
model.fit(X_train,y_train) #模型1
X_train, X_test, y_train, y_test = train_test_split(x1, y1,
train_size=0.75, test_size=0.25, random_state=42)
clf=GaussianNB()
clf.fit(X_train,y_train) #模型2
# 从bento_service.py里面抽取的服务类
iris_classifier_service = IrisClassifier()
# 打包两个模型
iris_classifier_service.pack('StackingClassifier', model)
iris_classifier_service.pack('GaussianNB', clf)
# 保存到本地,路径可自己写
saved_path = iris_classifier_service.save()
Aunque el código es tan largo, de hecho, solo puso el código de entrenamiento del primer paso y agregó cuatro líneas de código de empaquetado al mismo tiempo. Además, para ampliar el conocimiento, usamos dos modelos aquí y los empaquetamos en un servicio al mismo tiempo.
#bento_service.py
import pandas as pd
import json
from bentoml import env, artifacts, api, BentoService
from bentoml.adapters import JsonInput
from bentoml.frameworks.sklearn import SklearnModelArtifact
@env(infer_pip_packages=True) #打包时自动寻找所有的依赖
@artifacts([SklearnModelArtifact('StackingClassifier'),SklearnModelArtifact("GaussianNB")])#定义的两个模型
class IrisClassifier(BentoService):
@api(input=JsonInput(), batch=False)#使用jsoninput,batch注意为false
def predict(self, parsed_json):
df = pd.read_json(parsed_json,orient='table')#将json转换为dataframe
data1 = df[["Aggression", "pressure", "anxiety", "suspect", "balance","confidence", "energy", "self-regulation", "inhibition", "neuroticism","deperession", "happiness", "fh_m", "fh_s","I","E"]]#选取特征列
result = pd.DataFrame([['StackingClassifier', self.artifacts.StackingClassifier.predict(data1),'HealthType=2'], ['GaussianNB', self.artifacts.GaussianNB.predict_proba(data1)[:, 0],'Probability']])
return json.loads(result.to_json(orient="records")) #按行导出json
bento_service.py es el núcleo. Si el error de código tiene un 90 % de probabilidad de provenir de esta área, estamos más preocupados por la entrada y la salida. Hay muchas maneras de ingresar. También puede usar la entrada del marco de datos directamente, pero aquí adoptamos un método json diferente del ejemplo para ampliar el conocimiento. El formato de entrada de json es el siguiente:
datain = '{"schema":{"fields":[{"name":"index","type":"integer"},{"name":"Aggression","type":"number"},{"name":"pressure","type":"number"},{"name":"anxiety","type":"number"},{"name":"suspect","type":"number"},{"name":"balance","type":"number"},{"name":"confidence","type":"number"},{"name":"energy","type":"number"},{"name":"self-regulation","type":"number"},{"name":"inhibition","type":"number"},{"name":"neuroticism","type":"number"},{"name":"deperession","type":"number"},{"name":"happiness","type":"number"},{"name":"I","type":"number"},{"name":"E","type":"number"},{"name":"fh_m","type":"number"},{"name":"fh_s","type":"number"},{"name":"Extroversion","type":"number"},{"name":"Stability","type":"number"}],"primaryKey":["index"],"pandas_version":"0.20.0"},"data":[{"index":100,"Aggression":46.58,"pressure":23.35,"anxiety":41.71,"suspect":37.76,"balance":64.67,"confidence":79.75,"energy":31.07,"self-regulation":72.71,"inhibition":23.41,"neuroticism":23.65,"deperession":25.13,"happiness":28.26,"I":28.99,"E":4.23,"fh_m":2.26,"fh_s":0.71,"Extroversion":0.36,"Stability":0.43}]}'
Al usar pd.read_json, el json pasado debe contener el esquema , de lo contrario, los pandas no sabrán qué tipo de datos usar para leer los datos que pasó. Aquí recomiendo Baidu json, copie y verifique que su formato json sea correcto. Si el json que pasa contiene muchas barras, significa que ha usado json.dumps. Debe usar el método json.loads para eliminar las barras antes de cargar.
El método de predicción central, qué parámetros desea devolver, ya sea un valor predicho o una probabilidad, puede definirlo y escribirlo usted mismo.
Después de preparar los dos archivos py, ingrese al tercer paso e inicie la línea de comando:
ingrese python export.py, y su script comenzará a ejecutarse.Si aparecen las siguientes palabras:

¡significa que el modelo se ha empaquetado correctamente! Ahora puedes iniciar tu servicio. Use el comando bentoml serve IrisClassifier:latest para iniciar su servicio recién generado, o cambie la última al número de versión del servicio que desea iniciar. Por ejemplo, en la imagen de arriba, es 20220110113101_2C47F4, que en realidad es año, mes, día, hora, minuto y segundo más seis números hexadecimales.

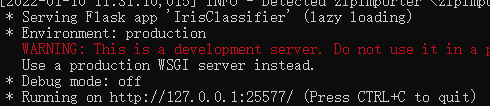
Ha obtenido la dirección IP de su servidor local, http://127.0.0.1:25577, el modelo se ha estado ejecutando en el servidor y luego se realiza la prueba de transferencia de parámetros locales:
import requests
response = requests.post("http://127.0.0.1:25577/predict", json=datain) #datain是你要传的json
print(response.text)
#[{"0": "StackingClassifier", "1": [1], "2": "HealthType=2"}, {"0": "GaussianNB", "1": [1.0], "2": "Probability"}]
Se devuelve el resultado (la línea de comando también puede ver lo que se devuelve), y yo mismo he definido tres campos, uno es el nombre del modelo, uno es el valor de probabilidad devuelto y el otro es el tipo de datos devuelto.
Después de hacer todo lo anterior, el siguiente paso es el cuarto paso para exportar:
aquí solo hablo de algunos problemas de la instalación de win10 docker:
1. Reserve al menos 10 G de espacio en disco C, docker en sí no es grande y su archivo vmdx es muy grande (tomo 7 G aquí).
2. Si desea que se ejecute docker_engine, debe instalar el entorno virtual del kernel de Linux (wsl2) o instalar Hyper-V. Hyper-V funciona más lento que wsl2, pero la instalación es más tonta. Si lo verifica en los programas y funciones de Windows, se instalará y reiniciará.

Así es como se ve después de tener éxito.
Después de asegurarse de que la ventana acoplable se puede ejecutar, ingrese en la línea de comando:
bentoml containerize IrisClassifier:latest -t iris-classifier
Bentoml colocará automáticamente en un contenedor su última versión del servicio como una imagen acoplable. Si usa un espejo, puede tirar, pero aquí elegimos una forma más simple que no requiere una red, es decir, guarde el espejo como un paquete tar:
docker save -o iris.tar
Este es el quinto paso, el último paso completado en su computadora, puede llevar mucho tiempo, el paquete tar generado tiene un tamaño de aproximadamente 1 G.
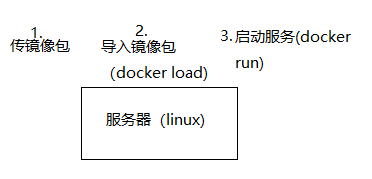
Después de completar, cargue iris.tar en el directorio raíz del servidor Linux y
use el siguiente comando en el shell del servidor Linux:
#centos没安装docker的先一键安装docker
#curl -sSL https://get.daocloud.io/docker | sh
#装载镜像
docker load -i iris.tar
#启动服务
docker run -p 5000:5000 iris-classifier:20220110113101_2C47F4
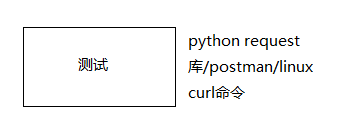
De esta forma, el servicio se ejecuta en el puerto 5000 del servidor Linux y los comandos postman y curl se pueden usar para pasar parámetros para la prueba.
Hasta ahora, hemos completado la producción y el despliegue de un ciclo modelo, y todavía hay muchos detalles. No los escribiré debido a limitaciones de espacio. Espero que pueda consultar el documento oficial: https://docs.bentoml.org/en/0.13-lts/quickstart.html Dirección oficial del proyecto: https://github.com/bentoml/BentoML ¡Esta es una biblioteca de código abierto muy concienzuda, y espero que más personas puedan
usarla
y
desarrollarla
!