Tabla de contenido

prefacio
Basado en la red neuronal recurrente, este proyecto construye un modelo RNN de múltiples capas. Al entrenar el conjunto de datos y ajustar el modelo y el conjunto de datos, se realiza la función de generar acrósticos y letras tibetanas.
En este proyecto, utilizamos una Red Neural Recurrente (RNN) como base del modelo. RNN es una red neuronal capaz de procesar datos de secuencias y sobresale en el procesamiento de datos de secuencias como texto y voz.
Construimos un modelo RNN de varias capas, lo que significa que apilamos varias capas de RNN para mejorar el poder expresivo del modelo. El modelo RNN multicapa puede capturar mejor la relación compleja y la información contextual en los datos.
Al entrenar el conjunto de datos, permitimos que el modelo aprenda diferentes tipos de acrósticos y letras. Después de ajustar el modelo y el conjunto de datos, mejoramos aún más la calidad y la diversidad de los acrósticos y las letras generados.
En última instancia, nuestro modelo puede aceptar acrósticos ingresados por el usuario y generar acrósticos con los acrósticos correspondientes, o letras completas basadas en los comienzos de letras proporcionados por el usuario. A través de este proyecto, podemos crear trabajos de texto creativos y emocionales, brindando más experiencia artística y diversión a los usuarios.
diseño general
Esta parte incluye el diagrama de estructura general del sistema y el diagrama de flujo del sistema.
Diagrama de estructura general del sistema
La estructura general del sistema se muestra en las siguientes dos figuras.
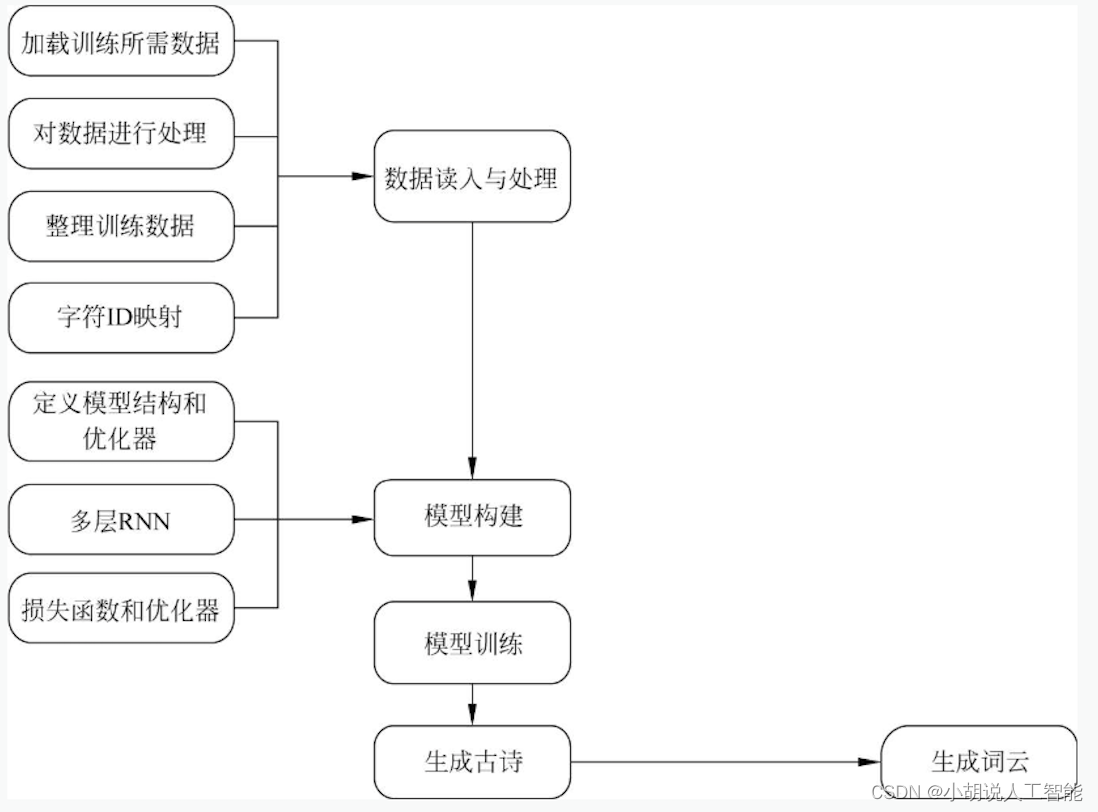
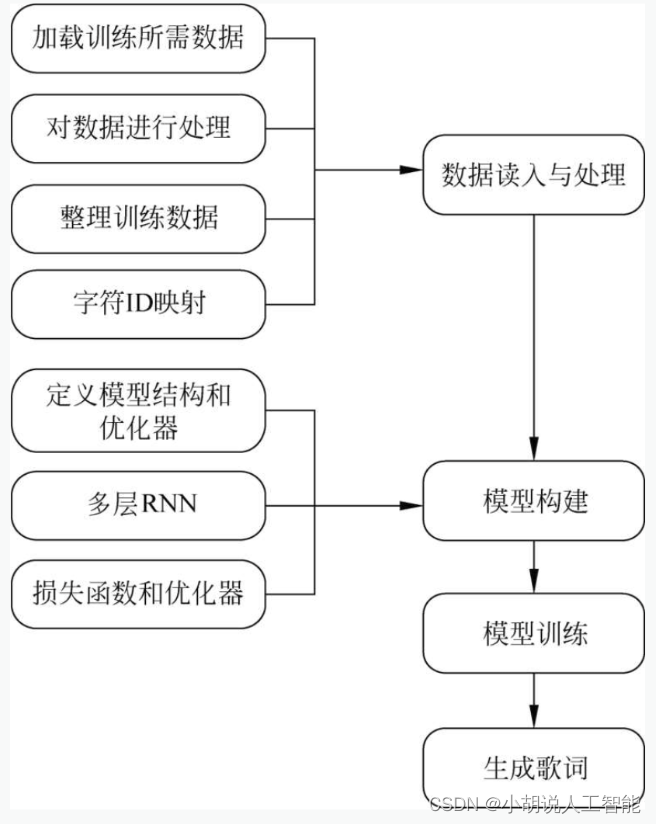
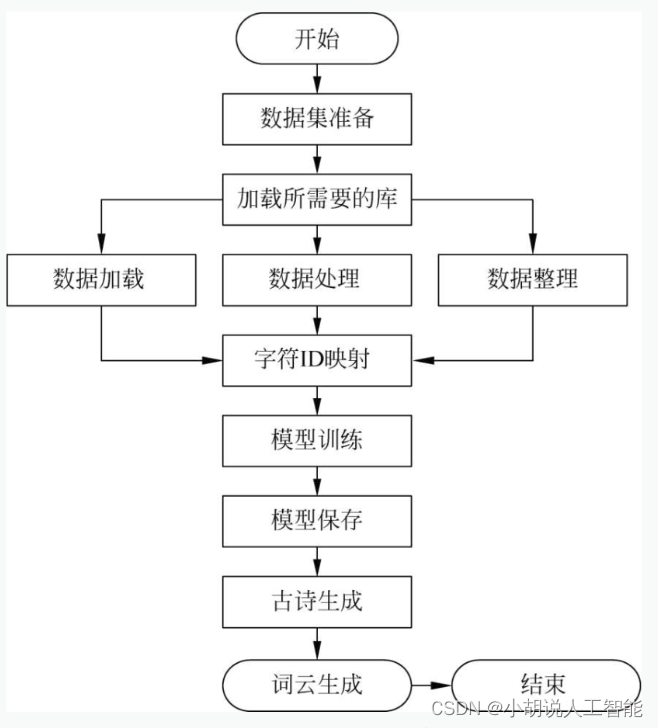
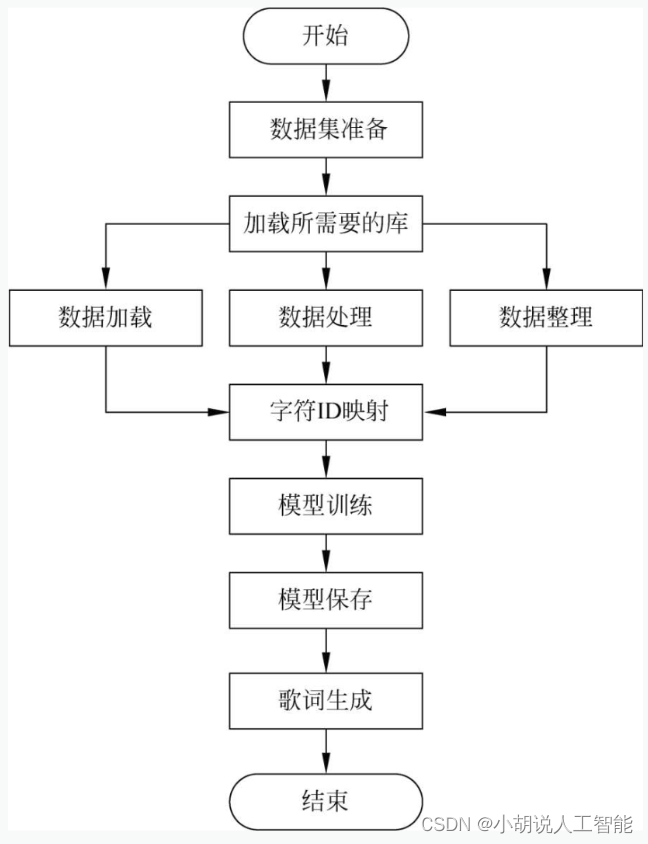
Diagrama de flujo del sistema
El flujo del sistema se muestra en las siguientes dos figuras.
entorno operativo
Esta sección incluye el entorno Python, el entorno Tensorflow y el entorno Pycharm.
Entorno de Python
Basado en Python 3.7.3, está desarrollado en el entorno PyCharm.
Entorno de flujo de tensor
Abra Anaconda Prompt e ingrese la imagen del almacén de Tsinghua:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config -set show_channel_urls yes
Cree un entorno de Python 3.7 llamado TensorFlow. En este momento, hay un problema de coincidencia entre la versión de Python y la versión posterior de TensorFlow. En este paso, elija Python3.x.
conda create -n tensorflow python==3.7
Si es necesario confirmar, presione la tecla Y.
Active el entorno TensorFlow en Anaconda Prompt:
conda activate tensorflow
Instale la versión de CPU de TensorFlow:
pip install -upgrade --ignore -installed tensorflow
Instalado.
Entorno PyCharm
El IDE es PyCharm, cualquier versión está bien.
implementación del módulo
Este proyecto consta de dos partes: generación de poemas antiguos y generación de letras. La generación de poemas antiguos consiste en el preprocesamiento de datos, la construcción de modelos, el entrenamiento y el guardado de modelos, el uso del modelo para generar poemas antiguos, la generación de poemas acrósticos tibetanos y la visualización de módulos con nubes de palabras. Las funciones y los códigos relacionados de cada módulo se presentan a continuación.
Generación de poemas antiguos
1. Preprocesamiento de datos
Esta parte incluye la carga de bibliotecas y datos necesarios, el procesamiento de datos y la organización de datos de entrenamiento. La dirección de descarga es https://github.com/chinese-poetry/chinese-poetry .
1) Cargar biblioteca y datos
El código correspondiente es el siguiente:
import tensorflow as tf
import numpy as np
import glob
import json
from collections import Counter
from tqdm import tqdm
from snownlp import SnowNLP #主要做繁体字转简体字
poets = []
paths = glob.glob('chinese-poetry/json/poet.*.json') #加载数据
El estilo específico de entrenamiento de datos de poesía antigua se muestra en la siguiente figura.
2) Procesamiento de datos
El código correspondiente es el siguiente:
for path in paths: #对每一个json文件
data = open(path, 'r').read() #将它读取
data = json.loads(data) #将字符串加载成字典
for item in data: #对每一项
content = ''.join(item['paragraphs']) #将正文取出拼接到一起
if len(content) >= 24 and len(content) <= 32: #取长度合适的诗
content = SnowNLP(content)
poets.append('[' + content.han + ']') #如果是繁体转为简体
poets.sort(key=lambda x: len(x)) #按照诗的长度排序
3) Organizar datos
El código correspondiente es el siguiente:
batch_size = 64
X_data = []
Y_data = []
for b in range(len(poets) // batch_size): #分批次
start = b * batch_size #开始位置
end = b * batch_size + batch_size #结束位置
batch = [[char2id[c] for c in poets[i]] for i in range(start, end)]
#两层循环每首诗的每个字转换成序列再迭代
maxlen = max(map(len, batch))#当前最长的诗为多少字
X_batch = np.full((batch_size, maxlen - 1), 0, np.int32) #用零进行填充
Y_batch = np.full((batch_size, maxlen - 1), 0, np.int32) #用零进行填充
for i in range(batch_size):
X_batch[i, :len(batch[i]) - 1] = batch[i][:-1] #每首诗最后一个字不要
Y_batch[i, :len(batch[i]) - 1] = batch[i][1:] #每首诗第一个字不要
X_data.append(X_batch)
Y_data.append(Y_batch)
#整理字符与ID之间的映射
chars = []
for item in poets:
chars += [c for c in item]
chars = sorted(Counter(chars).items(), key=lambda x:x[1], reverse=True)
print('共%d个不同的字' % len(chars))
print(chars[:10])
#空位为了特殊字符
chars = [c[0] for c in chars]#对于每一个字
char2id = {
c: i + 1 for i, c in enumerate(chars)} #构造字符与ID的映射
id2char = {
i + 1: c for i, c in enumerate(chars)} #构造ID与字符的映射
2. Construcción de modelos
Después de cargar los datos en el modelo, es necesario definir la estructura del modelo, usar RNN multicapa, definir la función de pérdida y el optimizador.
1) Definir la estructura del modelo y el optimizador
El código correspondiente es el siguiente:
hidden_size = 256 #隐藏层大小
num_layer = 2
embedding_size = 256
#进行占位
X = tf.placeholder(tf.int32, [batch_size, None])
Y = tf.placeholder(tf.int32, [batch_size, None])
learning_rate = tf.Variable(0.0, trainable=False) #定义学习率,不可训练
2) Usar RNN multicapa
El código correspondiente es el siguiente:
cell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.BasicLSTMCell(hidden_size, state_is_tuple=True) for i in range(num_layer)],
state_is_tuple=True)
initial_state = cell.zero_state(batch_size, tf.float32) #全零初始状态
embeddings = tf.Variable(tf.random_uniform([len(char2id) + 1, embedding_size], -1.0, 1.0))
embedded = tf.nn.embedding_lookup(embeddings, X) #得到嵌入后的结果
outputs, last_states = tf.nn.dynamic_rnn(cell, embedded, initial_state=initial_state)
outputs = tf.reshape(outputs, [-1, hidden_size]) #改变形状
logits = tf.layers.dense(outputs, units=len(char2id) + 1)
logits = tf.reshape(logits, [batch_size, -1, len(char2id) + 1])
probs = tf.nn.softmax(logits) #得到概率
3) Definir función de pérdida y optimizador
El código correspondiente es el siguiente:
loss = tf.reduce_mean(tf.contrib.seq2seq.sequence_loss(logits, Y, tf.ones_like(Y, dtype=tf.float32))) #求出损失
params = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(loss, params), 5)
#进行梯度截断操作
optimizer = tf.train.AdamOptimizer(learning_rate).apply_gradients(zip(grads, params))
#得到优化器
3. Entrenamiento y almacenamiento de modelos
Después de definir la arquitectura del modelo y compilarlo, entrene el modelo a través del conjunto de entrenamiento para hacer que el modelo genere poemas antiguos. Aquí el modelo se ajusta y se guarda usando los conjuntos de entrenamiento y prueba.
1) Entrenamiento modelo
El código correspondiente es el siguiente:
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for epoch in range(50):
sess.run(tf.assign(learning_rate, 0.002 * (0.97 ** epoch))) #指数衰减
data_index = np.arange(len(X_data))
np.random.shuffle(data_index) #每一轮迭代数据打乱
X_data = [X_data[i] for i in data_index]
Y_data = [Y_data[i] for i in data_index]
losses = []
for i in tqdm(range(len(X_data))):
ls_, _ = sess.run([loss, optimizer],feed_dict={
X: X_data[i],Y: Y_data[i]})
losses.append(ls_)
2) Guardar el modelo
El código correspondiente es el siguiente:
saver = tf.train.Saver()
saver.save(sess, './poet_generation_tensorflow')
import pickle
with open('dictionary.pkl', 'wb') as fw:
pickle.dump([char2id, id2char], fw) #保存成一个pickle文件
Después de guardar el modelo, se puede reutilizar o trasplantar a otros entornos.
4. Usa el modelo para generar poemas antiguos
Esta parte incluye la carga de recursos, la redefinición de la red, el uso de RNN multicapa, la definición de funciones de pérdida y optimizadores y la generación de poemas antiguos.
1) Cargar recursos
El código correspondiente es el siguiente:
import tensorflow as tf
import numpy as np
import pickle
#加载模型
with open('dictionary.pkl', 'rb') as fr:
[char2id, id2char] = pickle.load(fr)
2) Redefinir la red
El código correspondiente es el siguiente:
batch_size = 1
hidden_size = 256 #隐藏层大小
num_layer = 2
embedding_size = 256
#占位操作
X = tf.placeholder(tf.int32, [batch_size, None])
Y = tf.placeholder(tf.int32, [batch_size, None])
learning_rate = tf.Variable(0.0, trainable=False)
3) Uso de RNN multicapa
El código correspondiente es el siguiente:
cell = tf.nn.rnn_cell.MultiRNNCell(
[tf.nn.rnn_cell.BasicLSTMCell(hidden_size, state_is_tuple=True) for i in range(num_layer)],
state_is_tuple=True)
initial_state = cell.zero_state(batch_size, tf.float32) #初始化
embeddings = tf.Variable(tf.random_uniform([len(char2id) + 1, embedding_size], -1.0, 1.0))
embedded = tf.nn.embedding_lookup(embeddings, X)
outputs, last_states = tf.nn.dynamic_rnn(cell, embedded, initial_state=initial_state)
outputs = tf.reshape(outputs, [-1, hidden_size])
logits = tf.layers.dense(outputs, units=len(char2id) + 1)
probs = tf.nn.softmax(logits) #得到概率
targets = tf.reshape(Y, [-1])
4) Definir función de pérdida y optimizador
El código correspondiente es el siguiente:
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=targets))
params = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(loss, params), 5)
optimizer = tf.train.AdamOptimizer(learning_rate).apply_gradients(zip(grads, params))
sess = tf.Session()
sess.run(tf.global_variables_initializer())#得到初始状态
saver = tf.train.Saver()
saver.restore(sess, tf.train.latest_checkpoint('./'))
5) Genera poemas antiguos
El código correspondiente es el siguiente:
def generate():
states_ = sess.run(initial_state)
gen = ''
c = '['
while c != ']'
gen += c
x = np.zeros((batch_size, 1))
x[:, 0] = char2id[c]
probs_, states_ = sess.run([probs, last_states], feed_dict={
X: x, initial_state: states_}) #得到状态与概率
probs_ = np.squeeze(probs_) #去掉维度
pos = int(np.searchsorted(np.cumsum(probs_), np.random.rand() * np.sum(probs_))) #根据概率分布产生一个整数
c = id2char[pos]
return gen[1:]
5. Genera acrósticos
El código correspondiente es el siguiente:
def generate_with_head(head):
states_ = sess.run(initial_state)
gen = ''
c = '['
i = 0
while c != ']':
gen += c
x = np.zeros((batch_size, 1))
x[:, 0] = char2id[c]
probs_, states_ = sess.run([probs, last_states], feed_dict={
X: x, initial_state: states_})
probs_ = np.squeeze(probs_)
pos = int(np.searchsorted(np.cumsum(probs_), np.random.rand() * np.sum(probs_)))
if (c=='[' or c == '。' or c == ',') and i<len(head):
#判断为第一个字的条件
c = head[i]
i += 1
else:
c = id2char[pos]
return gen[1:]
#将结果写入文件中
f=open('guhshiwordcloud.txt','w',encoding='utf-8')
f.write(generate())
f.write(generate_with_head('天地玄黄'))
f.write(generate_with_head('宇宙洪荒'))
f.write(generate_with_head('寒来暑往'))
f.close()
6. Muestra los poemas antiguos generados con la nube de palabras.
Esta parte incluye cargar la biblioteca requerida, abrir el archivo de poema antiguo generado, extraer palabras clave y pesos, generar objetos, generar los colores requeridos a partir de imágenes, mostrar nubes de palabras y guardar imágenes.
1) Cargue las bibliotecas requeridas
Las operaciones relacionadas son las siguientes:
from wordcloud import WordCloud, ImageColorGenerator
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import jieba.analyse
2) Abra el archivo de poema antiguo generado
Las operaciones relacionadas son las siguientes:
text = open('guhshiwordcloud.txt','r', encoding='UTF-8').read()
3) Extraer palabras clave y pesos
Las operaciones relacionadas son las siguientes:
freq = jieba.analyse.extract_tags(text, topK=200, withWeight=True)
#权重控制关键词在词云里面的大小
print(freq[:20])#打印前20个
freq = {
i[0]: i[1] for i in freq} #转成字典
4) Generar objetos
Las operaciones relacionadas son las siguientes:
mask = np.array(Image.open("color_mask.png")) #以图片为参考
wc = WordCloud(mask=mask, font_path='Hiragino.ttf', mode='RGBA', background_color=None).generate_from_frequencies(freq)
5) Genere el color requerido de la imagen
Las operaciones relacionadas son las siguientes:
image_colors = ImageColorGenerator(mask)
wc.recolor(color_func=image_colors)
6) Mostrar nube de palabras
Las operaciones relacionadas son las siguientes:
plt.imshow(wc, interpolation='bilinear') #设定插值形式
plt.axis("off") #无坐标轴
plt.show()
7) Guarda la imagen
Las operaciones relacionadas son las siguientes:
wc.to_file('gushiwordcloud.png')
Generación lírica
Esta parte incluye el preprocesamiento de datos, la creación de modelos, el entrenamiento y el guardado de modelos y la producción de letras. Las funciones y los códigos relacionados de cada módulo se presentan a continuación.
1. Preprocesamiento de datos
Las operaciones relacionadas son las siguientes:
#首先加载相应的库
from keras.models import Sequential
from keras.layers import Dense, LSTM, Embedding
from keras.callbacks import LambdaCallback
import numpy as np
import random
import sys
import pickle
sentences = []
#读取训练所需数据并进行预处理
with open('../lyrics.txt', 'r', encoding='utf8') as fr: #读取歌词文件
lines = fr.readlines() #一行一行读取
for line in lines:
line = line.strip() #去掉空格字符
count = 0
for c in line:
if (c >= 'a' and c <= 'z') or (c >= 'A' and c <= 'Z'):
count += 1 #统计英文字符个数
if count / len(line) < 0.1: #进行筛选
sentences.append(line)
#整理字符和ID之间的映射
chars = {
}
for sentence in sentences:
for c in sentence:
chars[c] = chars.get(c, 0) + 1
chars = sorted(chars.items(), key=lambda x:x[1], reverse=True)
chars = [char[0] for char in chars]
vocab_size = len(chars)
char2id = {
c: i for i, c in enumerate(chars)}
id2char = {
i: c for i, c in enumerate(chars)}
with open('dictionary.pkl', 'wb') as fw:
pickle.dump([char2id, id2char], fw)
2. Construcción de modelos
Las operaciones relacionadas son las siguientes:
maxlen = 10
step = 3
embed_size = 128
hidden_size = 128
vocab_size = len(chars)
batch_size = 64
epochs = 20
X_data = []
Y_data = []
for sentence in sentences:
for i in range(0, len(sentence) - maxlen, step): #每次平移3
#根据前面的字来预测后面一个字
X_data.append([char2id[c] for c in sentence[i: i + maxlen]])
y = np.zeros(vocab_size, dtype=np.bool)
y[char2id[sentence[i + maxlen]]] = 1
Y_data.append(y)
X_data = np.array(X_data)
Y_data = np.array(Y_data)
print(X_data.shape, Y_data.shape)
#定义序列模型
model = Sequential()
model.add(Embedding(input_dim=vocab_size, output_dim=embed_size, input_length=maxlen))
model.add(LSTM(hidden_size, input_shape=(maxlen, embed_size)))
model.add(Dense(vocab_size, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
#定义序列样本生成函数
def sample(preds, diversity=1.0):
preds = np.asarray(preds).astype('float64')
preds = np.log(preds + 1e-10) / diversity #取对数
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas) #取最大的值拿到生成的字
#定义每轮训练后的回调函数
def on_epoch_end(epoch, logs):
print('-' * 30)
print('Epoch', epoch)
index = random.randint(0, len(sentences)) #随机选取一句
for diversity in [0.2, 0.5, 1.0]:
print('----- diversity:', diversity)
sentence = sentences[index][:maxlen] #随机选一首歌把前十个字取出
print('----- Generating with seed: ' + sentence)
sys.stdout.write(sentence)
for i in range(400):
x_pred = np.zeros((1, maxlen))
for t, char in enumerate(sentence):
x_pred[0, t] = char2id[char] #把x相应位置的值改为ID
preds = model.predict(x_pred, verbose=0)[0]
next_index = sample(preds, diversity)
next_char = id2char[next_index] #把下一个字拿出来
sentence = sentence[1:] + next_char
sys.stdout.write(next_char)
sys.stdout.flush()
3. Modelo de formación y ahorro
Las operaciones relacionadas son las siguientes:
model.fit(X_data, Y_data, batch_size=batch_size, epochs=epochs, callbacks=[LambdaCallback(on_epoch_end=on_epoch_end)])
model.save('song.h5')
4. Generar letras
El siguiente código usa el modelo generado previamente para generar letras y necesita proporcionar una letra inicial:
#导入所需要的库
from keras.models import load_model
import numpy as np
import pickle
import sys
maxlen = 10
model = load_model('song.h5') #加载使用上一段代码生成的模型
with open('dictionary.pkl', 'rb') as fr: #打开.pkl文件
[char2id, id2char] = pickle.load(fr)
#定义序列样本生成函数
def sample(preds, diversity=1.0):
preds = np.asarray(preds).astype('float64')
preds = np.log(preds + 1e-10) / diversity #使用对数
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas) #最大的概率
#提供一句起始歌词
sentence = '天地玄黄宇宙洪荒'
sentence = sentence[:maxlen] #不能超过最大长度
diversity = 1.0
print('----- Generating with seed: ' + sentence)
print('----- diversity:', diversity)
sys.stdout.write(sentence)
for i in range(400): #迭代400次
x_pred = np.zeros((1, maxlen)) #初始化为0
for t, char in enumerate(sentence):
x_pred[0, t] = char2id[char]
preds = model.predict(x_pred, verbose=0)[0]
next_index = sample(preds, diversity)
next_char = id2char[next_index] #把下一个字拿出来
sentence = sentence[1:] + next_char
sys.stdout.write(next_char)
sys.stdout.flush()
Prueba del sistema
Esta parte incluye dos partes: generar poemas antiguos y poemas acrósticos, y generar letras.
1. Genera poemas antiguos y poemas acrósticos
Esta sección incluye modelos de entrenamiento para la generación de poemas antiguos, poemas antiguos, poemas acrósticos y nubes de palabras.
1) Entrenamiento del modelo generado por poemas antiguos
El modelo se guarda en el archivo correspondiente para su posterior codificación para generar poemas antiguos y poemas acrósticos, como se muestra en la figura.
2) Generar poemas antiguos
Use el código anterior para entrenar y guardar el modelo para generar cuatro oraciones de versos de siete caracteres, como se muestra en la figura.

3) Generar acrósticos
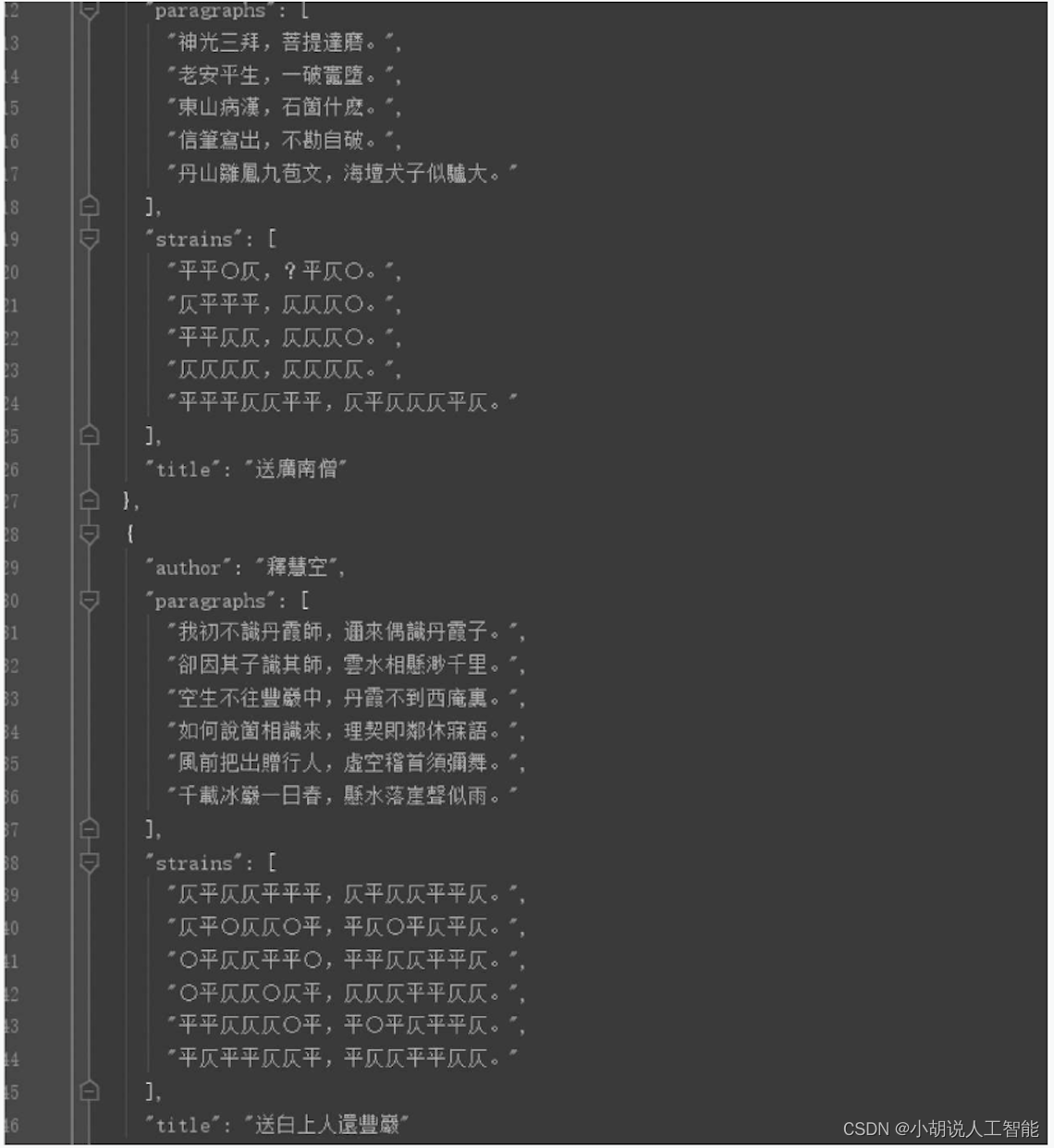
Use el código anterior para entrenar y guardar el modelo para generar poemas acrósticos tibetanos e ingrese "Heaven and Earth Xuanhuang", el resultado se muestra en la figura.

Ingrese "universo prehistórico", el resultado se muestra en la figura.

Ingrese "frío a verano", el resultado se muestra en la figura.

4) Generar nube de palabras
Genere un poema antiguo ordinario y tres poemas acrósticos y guárdelos en un archivo para generar una nube de palabras, como se muestra en la Figura 1-4.




2. Generar letras
El modelo se guarda en el archivo correspondiente para su uso posterior. El modelo de generación de entrenamiento se muestra en la Figura 5, y el resultado de generar letras se muestra en la Figura 6.


Descarga del código fuente del proyecto
Consulte la página de descarga de recursos de mi blog para obtener más información.
Descarga de otra información
Si desea continuar aprendiendo sobre rutas de aprendizaje y sistemas de conocimiento relacionados con la inteligencia artificial, bienvenido a leer mi otro blog " Pesado | Ruta de aprendizaje de conocimiento básico de aprendizaje de inteligencia artificial completa, todos los materiales se pueden descargar directamente desde el disco de la red sin pagar atención a las rutinas "
Este blog se refiere a la conocida plataforma de código abierto de Github, la plataforma de tecnología de IA y expertos en campos relacionados: Datawhale, ApacheCN, AI Youdao y Dr. Huang Haiguang, etc. Hay alrededor de 100G de materiales relacionados, y espero ayuda a todos tus amigos.