Nivel 1: Realizar la propagación directa de la capa totalmente conectada
detalles de la misión
La tarea de este nivel: realizar la propagación directa de la capa totalmente conectada.
información relacionada
Para completar esta tarea, debe dominar:
- La estructura de la red neuronal;
- Definición de una capa completamente conectada.
Para conocer el contenido de esta capacitación, consulte el Capítulo 3.1-3.5 del libro "Introducción al aprendizaje profundo: teoría e implementación basadas en Python".
La estructura de la red neuronal.
En la capacitación anterior, aprendimos sobre perceptrones y perceptrones multicapa, y también aprendimos cómo construir perceptrones multicapa apilando perceptrones, para obtener modelos con capacidades expresivas más fuertes. En este ejercicio práctico vamos un paso más allá y aprendemos sobre la estructura de las redes neuronales. La red neuronal se forma apilando varias capas de redes neuronales. Diferentes capas pueden extraer de manera efectiva las características de los datos, realizar la extracción gradual de datos de entrada de características de bajo orden a características de alto orden y completar tareas de aprendizaje automático como clasificación y regresión. Un perceptrón multicapa ya es una red neuronal muy simple. Las redes neuronales comunes incluyen perceptrones multicapa, redes neuronales convolucionales y redes neuronales recurrentes. La siguiente figura muestra un modelo de red neuronal simple.
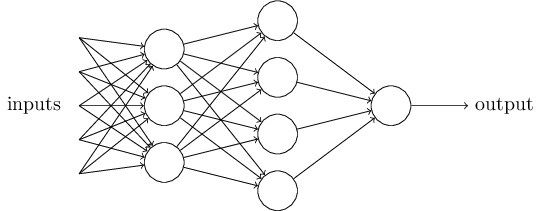
Figura 1 Red neuronal simple
La implementación de una red neuronal incluye dos partes: propagación hacia adelante y propagación hacia atrás. La propagación directa se utiliza tanto en el entrenamiento como en la predicción para calcular los resultados de la predicción y las funciones de pérdida del modelo de red. La retropropagación se usa para calcular el gradiente de los parámetros durante el proceso de entrenamiento, y el modelo de red se entrena usando el método de descenso de gradiente. En los próximos ejercicios, nos centraremos en la propagación hacia adelante del modelo de red neuronal y colocaremos la propagación hacia atrás en la introducción de capacitación posterior.
A partir de esta capacitación, la usará numpypara implementar un marco de aprendizaje profundo simple, incluida la propagación hacia adelante y hacia atrás de capas de redes neuronales comunes, así como los métodos básicos de capacitación de redes neuronales.
Definición de una capa completamente conectada
Volviendo al ejemplo anterior de implementación de puertas lógicas mediante un perceptrón, cada salida es una combinación lineal de todas las señales de entrada. Cada señal de entrada y salida se considera una neurona, luego la neurona de salida y la neurona de entrada se conectan entre sí. Esta capa de red se denomina capa completamente conectada.
Formalmente, una capa totalmente conectada con N neuronas de entrada y M neuronas de salida contiene dos conjuntos de parámetros: peso W∈RN×M y sesgo b∈RM, y su entrada puede considerarse como un vector x∈RN de dimensión N (columna). , en este momento el cálculo de la capa completamente conectada se puede expresar como:
y=xTW+b
A través de la capa totalmente conectada, las entidades de entrada se pueden transformar linealmente para obtener un nuevo conjunto de entidades.
Implementación de la capa completamente conectada
El entrenamiento tiene predefinida una FullyConnectedclase, y en el constructor de esta clase acepta los pesos Wy sesgos correspondientes b. El peso Wes un N×M numpy.ndarrayy el desplazamiento bes una longitud de M numpy.ndarray, donde N es el número de canales de entrada de la capa totalmente conectada y M es el número de canales de salida de la capa totalmente conectada.
En este ejercicio, debe implementar la función de pase hacia adelante forward(). forward()La entrada de la función xes una dimensión mayor o igual a 2 numpy.ndarray, y la forma es (B, dim1, dim2,..., dimk), donde B es el tamaño del lote, es decir, el número de datos . Primero, necesita xremodelar el , transformándolo en 2D con forma (B,N) numpy.ndarray. Al mismo tiempo, también se requiere la forma original del registro x, y se graba en formato original_x_shape. Finalmente devuelve el resultado de la transformación lineal.
requisitos de programación
De acuerdo con el indicador, agregue el código entre Begin y End en el editor de la derecha para realizar la propagación hacia adelante de la capa anterior completamente conectada.
instrucción de prueba
La plataforma probará el código que escriba. El método de prueba es: la plataforma generará aleatoriamente entradas x, pesos Wy sesgos b, y luego creará una instancia de la clase de acuerdo con su código de implementación FullyConnected, y luego usará la instancia para realizar cálculos de propagación hacia adelante. . Sus respuestas se compararán con las respuestas estándar. Porque el cálculo de números de punto flotante puede tener errores, siempre que el error entre su respuesta y la respuesta estándar no exceda 1e-5.
Ejemplo de entrada:
W:[[0.1, 0.2, 0.3],[0.4, 0.5, 0.6]]b:[0.1, 0.2, 0.3]x:[[1, 2],[3, 4]]
Entonces la neurona de salida correspondiente es:
[[1.0, 1.4, 1.8],[2.0, 2.8, 3.6]]
¡Comencemos tu misión, te deseo éxito!
Código de implementación:
importar numpy como np
clase totalmente conectado:
def __init__(self, W, b):
r''''
Inicialización de la capa completamente conectada.
Parámetro:
- W: numpy.array, (D_in, D_out)
- b: numpy.array, (D_out)
'''
self.W = W
self.b = b
self.x = Ninguno
self.original_x_shape = Ninguno
def adelante(auto, x):
r''''
El pase hacia adelante de la capa completamente conectada.
Parámetro:
- x: numpy.arreglo, (B, d1, d2, ..., dk)
Devolver:
- y: numpy.matriz, (B, M)
'''
########## Comenzar ##########
self.original_x_shape=x.forma
x=x.reforma(x.forma[0],-1)
self.x=x
out=np.dot(self.x,self.W)+self.b
regresar
########## Fin ##########
Captura de pantalla del código:

Nivel 2: implementar la propagación hacia adelante de funciones de activación comunes
detalles de la misión
La tarea de este nivel: realizar la propagación hacia adelante de las funciones de activación comunes.
información relacionada
Para completar esta tarea, debe dominar: la definición de funciones de activación comunes.
Para conocer el contenido de esta capacitación, consulte el Capítulo 3.1-3.5 del libro "Introducción al aprendizaje profundo: teoría e implementación basadas en Python".
El papel de la función de activación.
Consideremos primero una red neuronal que consta de dos capas completamente conectadas. Suponiendo que los pesos y las compensaciones de estas dos capas completamente conectadas son W1, b1 y W2, b2 respectivamente, y la entrada es x, entonces a partir de la fórmula de cálculo de la capa completamente conectada en el paso anterior, podemos obtener algunas conclusiones:
y=(x×W1+b1)×W2+b2=x×W1×W2+b1×W2+b2
Debido a que la multiplicación de matrices satisface la ley asociativa, sea W0=W1×W2, b0=b1×W2+b2, entonces las dos capas anteriores completamente conectadas se pueden escribir como:
y=x×W0+b0
Esto significa que apilar dos capas completamente conectadas equivale a una capa completamente conectada, por lo que este apilamiento no es válido y no puede mejorar la capacidad de ajuste del modelo. Para resolver este problema, cada capa suele ir seguida de una función de activación no lineal. Mediante la introducción de una función de activación no lineal, la capacidad de ajuste del modelo se puede mejorar en gran medida.
Mirando hacia atrás, cuando usamos el perceptrón para implementar puertas lógicas, usamos una función simbólica después de la transformación lineal, que en realidad es una función de activación. Es precisamente por el uso de funciones simbólicas que podemos implementar puertas XOR apilando perceptrones en perceptrones multicapa.
Definición de funciones de activación comunes
1. función de activación sigmoide
La función de activación sigmoidea es una función en forma de S que puede convertir cualquier rango de entrada en el rango de [0,1], y este rango es el mismo que el rango de probabilidad, por lo que la "probabilidad" se puede realizar con esto. Por otro lado, el gradiente de la función de activación sigmoidea es muy cercano a 0 cuando el valor absoluto de x es grande, lo que provocará el problema de la "desaparición del gradiente", dificultando la convergencia de la red. La expresión de su función es la siguiente:
sigmoide(x)=1/(1+e−x)
En la actualidad, los escenarios de aplicación de la función de activación sigmoidea incluyen principalmente dos tipos: el primero se usa para calcular la probabilidad, lo cual es consistente con la naturaleza de la función sigmoidea; el segundo se usa para calcular la atención, que se usa en la campos de la visión artificial y el procesamiento del lenguaje natural Técnicas de uso común, que se dejan para que los estudiantes interesados las aprendan por su cuenta.
2. Función de activación ReLU
La función de activación ReLU es actualmente la función de activación más utilizada en el aprendizaje profundo. Solo retiene la parte del tensor de entrada mayor que 0 y establece la parte menor que 0 a 0. A diferencia del sigmoide anterior, la función de activación de ReLU no sufre gradientes de desaparición. La expresión de su función es la siguiente:
ReLU(x)=max(0,x)
ReLU es la función de activación más utilizada actualmente en redes neuronales convolucionales, se caracteriza por un cálculo simple y no se verá afectada por el problema de desaparición de gradiente. Sin embargo, ReLU también tiene ciertos problemas, por ejemplo, la salida de ReLU no es negativa, por lo que el valor promedio de la salida de ReLU debe ser un número positivo, no 0. Esto puede tener algún impacto en la formación de la red. En respuesta a este problema, los investigadores también han propuesto métodos como LReLU y PReLU para mejorar, los estudiantes interesados pueden encontrar información relevante para el aprendizaje.
Implementación de funciones de activación comunes
Esta práctica de laboratorio espera que implemente la propagación hacia adelante de las funciones de activación de sigmoides y ReLU. El entrenamiento tiene predefinido una Sigmoidclase y una ReLUclase. En este ejercicio, debe implementar la función de pase hacia adelante forward(). forward()La entrada de la función xes una dimensión mayor o igual a 2 numpy.ndarrayy la forma es (B,d1,d2,...,dk), donde B es el tamaño del lote. Devuelve el valor de salida procesado por la función de activación.
requisitos de programación
De acuerdo con el mensaje, agregue el código entre Begin y End en el editor de la derecha para realizar la función de activación anterior.
Para la conveniencia de la retropropagación en el futuro, espero que:
- Al implementar sigmoid, registre los resultados de salida en
self.out; - Al implementar ReLU, los elementos menores a 0 se registran en forma de máscara
self.mask.
instrucción de prueba
La plataforma probará el código que escriba. El método de prueba es: la plataforma generará aleatoriamente xgradientes de entrada y salida , y luego creará una instancia de / class doutde acuerdo con su código de implementación , y luego usará esta instancia para realizar cálculos de propagación hacia adelante. Sus respuestas se compararán con las respuestas estándar. Porque el cálculo de números de punto flotante puede tener errores, siempre que el error entre su respuesta y la respuesta estándar no exceda 1e-5.SigmoidReLU
Ejemplo de entrada:
# 对于sigmoid激活函数:x:[[-1, 0, 1]]#对于ReLU激活函数:x:[[-1, 0, 1]]
Entonces la salida correspondiente es:
# 对于sigmoid激活函数:[[0.27, 0.50, 0.73]]#对于ReLU激活函数:[[0, 0, 1]]
Los resultados anteriores tienen errores de redondeo, que puede ignorar.
¡Comencemos tu misión, te deseo éxito!
Código de implementación:
importar numpy como np
clase sigmoide:
def __init__(uno mismo):
self.out = Ninguno
def adelante(auto, x):
r''''
Propagación hacia adelante de la función de activación sigmoidea.
Parámetro:
- x: numpy.arreglo, (B, d1, d2, ..., dk)
Devolver:
- y: numpy.arreglo, (B, d1, d2, ..., dk)
'''
########## Comenzar ##########
salida = 1. / (1. + np.exp(-x))
self.fuera = fuera
regresar
########## Fin ##########
clase ReLU:
def __init__(uno mismo):
self.mask = Ninguno
def adelante(auto, x):
r''''
Propagación directa de la función de activación de ReLU.
Parámetro:
- x: numpy.arreglo, (B, d1, d2, ..., dk)
Devolver:
- y: numpy.arreglo, (B, d1, d2, ..., dk)
'''
########## Comenzar ##########
self.máscara = (x <= 0)
fuera = x.copiar()
fuera[self.mask] = 0
regresar
########## Fin ##########
Captura de pantalla del código:

