1. Modelo de red neuronal
Redes neuronales (Neural Networks) es un modelo matemático establecido mediante la simulación del sistema nervioso del cerebro humano desde la perspectiva de la microestructura y la función. Tiene la capacidad de simular el pensamiento del cerebro humano. El sexo, etc., es un método importante para simular Inteligencia humana. La red neuronal está formada por la interconexión de neuronas, las cuales pueden recibir y procesar información, y este procesamiento de información es principalmente procesado y realizado por la interacción entre neuronas, es decir, a través de los pesos de conexión entre neuronas. Las redes neuronales se han utilizado con mucho éxito en áreas como la inteligencia artificial, el control automático, la informática, el procesamiento de información y el reconocimiento de patrones.
De acuerdo con la estructura y las funciones básicas de las neuronas biológicas, se puede simplificar en la forma de la siguiente figura y la base del modelo de red neuronal: modelo matemático de neurona artificial:
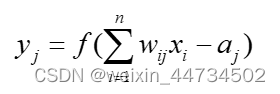
Entre ellos, representa la salida de la neurona j;
representa la entrada de la neurona i;
representa el peso de conexión entre neuronas;
representa el umbral de las neuronas;
es la función de transferencia de entrada a salida (también llamada función de activación).
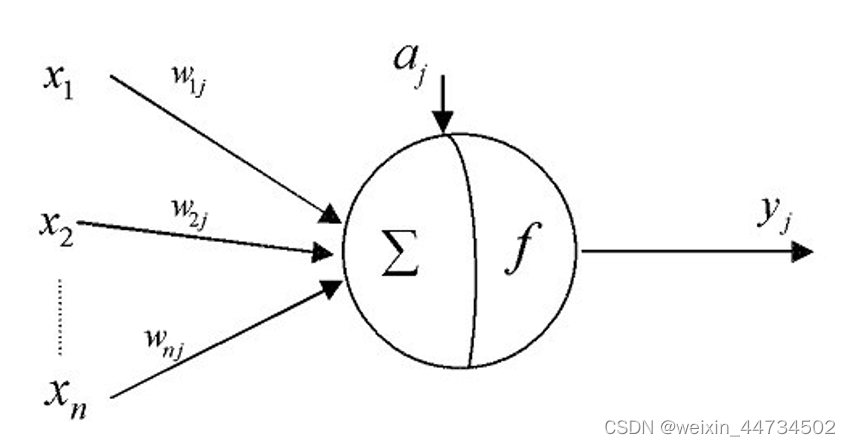
Sigmod es una función de activación común, que se usará con frecuencia en los siguientes ejemplos.
2. Algoritmo BP del modelo de red neuronal
2.1 Estructura de la Red y Modo de Trabajo
Además de las características de la unidad, la topología de la red también es una característica importante de NN. Hay dos tipos principales de NN en términos de métodos de conexión.
(i) Red de realimentación
Cada neurona recibe información de la capa anterior y la envía a la siguiente capa sin retroalimentación. Los nodos se dividen en dos categorías, unidades de entrada y unidades de cómputo, cada unidad de cómputo puede tener cualquier número de entradas, pero solo una salida (se puede acoplar a cualquier número de otros nodos como su entrada). Por lo general, la red feedforward se puede dividir en diferentes capas.La entrada de la capa i-th solo está conectada a la salida de la capa i-1th, y los nodos de entrada y salida están conectados al mundo exterior, mientras que otras capas intermedias están conectadas. llamadas capas ocultas.
(ii) Red de retroalimentación
Todos los nodos son unidades informáticas que también pueden aceptar entradas y salidas al mundo exterior. El proceso de trabajo de NN se divide principalmente en dos etapas: la primera etapa es el período de aprendizaje, en este momento el estado de cada unidad de cálculo permanece sin cambios y los pesos en cada conexión se pueden modificar a través del aprendizaje; la segunda etapa es el trabajo Período, en este momento El peso de cada conexión es fijo y el estado de la unidad informática cambia para lograr un cierto estado estable.
Desde la perspectiva del efecto, la red feedforward es principalmente un mapeo de funciones, que se puede utilizar para el reconocimiento de patrones y la aproximación de funciones. Existen dos tipos de redes de retroalimentación según la utilización de los puntos mínimos de la función de energía: el primer tipo es que todos los puntos mínimos de la función de energía funcionan, este tipo se usa principalmente como varias memorias asociativas; el segundo tipo solo usa el global En el punto mínimo, se utiliza principalmente para resolver problemas de optimización.
(iii) Algoritmo de retropropagación (Back-Propagation)
Para la modificación de los pesos en cada enlace mencionado en la red de retroalimentación, se utiliza principalmente el algoritmo de propagación hacia atrás (Back-Propagation), que también es la parte central del modelo de red neuronal BP de tres capas.
Esperamos que la salida correspondiente a las muestras de aprendizaje sea muy precisa, pero en realidad es imposible y solo podemos esperar que la salida real sea lo más cercana posible a la salida ideal. Para mayor claridad, denote la salida ideal correspondiente a la muestra s como , luego
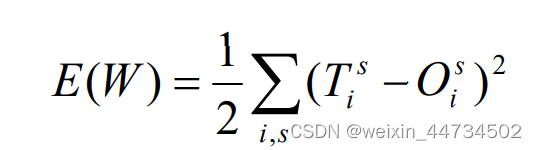
Mide la diferencia entre la salida real y la salida ideal bajo un conjunto dado de pesos Por lo tanto, el problema de encontrar un conjunto apropiado de pesos naturalmente se reduce a encontrar el valor apropiado de W para que E(W) pueda minimizarse. .
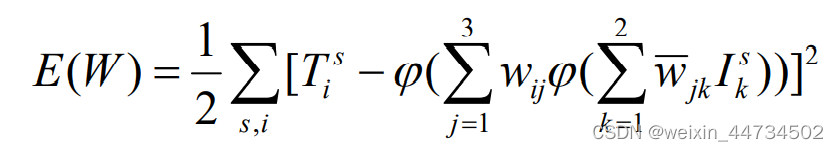
Es fácil saber que para cada variable o , esta es una función no lineal diferenciable continua, para obtener su punto mínimo y su valor mínimo, el método más conveniente es utilizar el método del descenso más pronunciado.
El método de descenso más pronunciado es un algoritmo iterativo. Para encontrar el mínimo (local) de E(W), comienza desde un punto inicial arbitrario y
calcula
la dirección del gradiente negativo -∇E (
) en el punto. Esta es la función en La dirección de la disminución más rápida en este punto; siempre que ∇E(
) ≠ 0, puede moverse una pequeña distancia a lo largo de esta dirección para llegar a un nuevo punto W1 = W0 −η∇E (
), η es un parámetro, siempre que η sea lo suficientemente pequeño, debe poder garantizar E( W1) < E (
). Repitiendo constantemente este proceso, se debe alcanzar un punto mínimo (local) de E. En esencia, de esto se trata el algoritmo BP
2.2 La topología de la red neuronal de BP se muestra en la figura.
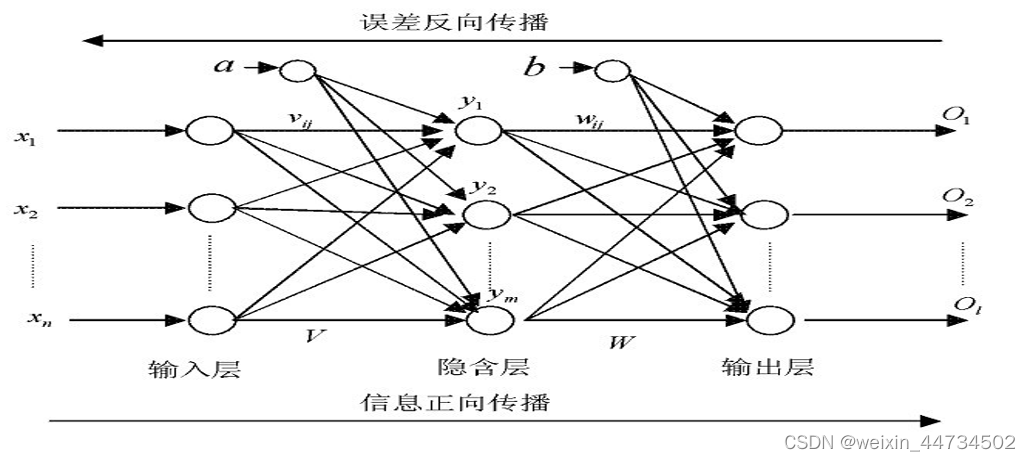
Entre ellos, está la entrada (real) de la red neuronal,
es la salida de la capa oculta, es decir, la entrada de la capa de salida, la
salida (real) de la red, a, b son los umbrales de la capa oculta Las neuronas de capa y capa de salida (nodos) respectivamente,
son los pesos de la capa de entrada a la capa oculta y de la capa oculta a la capa de salida, respectivamente. Es decir, en la red neuronal de BP que se muestra en la figura, el número de neuronas (nodos) en la capa de entrada es n, el número de neuronas (nodos) en la capa oculta es m, y el número de neuronas (nodos) ) en la capa de salida es l, esta estructura se denomina red neuronal BP de tres capas con estructura nml .
2.3 Algoritmo y proceso de aprendizaje de la red neuronal BP (tomando como ejemplo una red neuronal BP de tres capas)


3. Funciones comunes de la caja de herramientas de los algoritmos de redes neuronales de BP
3.1 newff——Función de configuración de parámetros de red neuronal BP
Función función: construir una red neuronal BP.
Forma de la función: net=newff(PR,[S1,S2,…,SN],{TF1,TF2,…,TFN},BTF,BLF,PF)
Entre ellos, PR: una matriz compuesta por datos muestrales, una matriz R×2-dimensional compuesta por el valor máximo y el valor mínimo;
Si: el número de nodos en la i- ésima capa, un total de N capas;
TFi: la función de transferencia del nodo de la i-ésima capa, incluida la función de transferencia lineal purelin; la función de transferencia de tipo S tangente tansig; la función de transferencia logarítmica de tipo S logsig. El valor predeterminado es "tansig";
BTF: función de entrenamiento, utilizada para ajustar los pesos y umbrales de la red, el valor predeterminado se basa en la función de entrenamiento trainlm del método de gradiente conjugado de Levenberg_Marquardt. Consulte la siguiente tabla para ver otros parámetros.
BLF: la función de aprendizaje de la red, incluida la regla de aprendizaje de BP learngd; la regla de aprendizaje de BP learngdm con el elemento de impulso. El valor predeterminado es 'learndm';
PF: La función de análisis de rendimiento de la red, incluida la función de análisis de rendimiento de error absoluto medio mae; la función de análisis de rendimiento de cuadrado medio mse. El valor predeterminado es "mse".
Generalmente, los primeros 4 parámetros se configuran durante el uso y los últimos 2 parámetros adoptan los parámetros predeterminados del sistema.
Ejemplo: net=newff([-1,1],[5,1],{'tansig','purelin'});
Entre ellos, [-1,1] indica el valor mínimo y máximo del vector de entrada, y también se puede usar minmax(p); [5,1] indica que la capa oculta es de 5 secciones y la capa de salida es 1 sección, tansig, distribución purelin indica la capa oculta y la función de transferencia de la capa de salida;
3.2 entrenar——Función de entrenamiento de red neuronal BP
Función función: use la función de entrenamiento para entrenar la red neuronal BP.
Forma de la función: [net,tr]=tren(NET,P,T)
NET: la red a entrenar, es decir, la red inicial creada por newff;
P: matriz de datos de entrada;
T: matriz de datos de salida esperada;
red: red entrenada;
tr: registro del proceso de formación.
Ejemplo:

3.3 sim——Función de predicción/simulación de red neuronal BP
Función función: use la red neuronal BP entrenada para predecir/simular la salida de la función.
Forma funcional: Y=sim(neto,x)
net: red neuronal BP entrenada;
x: datos de entrada;
Y: datos de predicción/simulación de red, es decir, la salida real de la red.
ejemplo
net=train(net,P,T); %Función de entrenamiento de red, net in train es la red inicial creada
Y=sim(net,P); %P es el vector de entrada, Y es el resultado de la simulación
plot(P,T,'-',P,Y,'o'); %T es la salida original, y dibuja el resultado original y el resultado de la simulación en un gráfico.
4. Pronóstico
4.1 Problema de clasificación
Ejemplo 1 Los biólogos intentan identificar dos tipos de mosquitos (Af y Apf), basándose en los datos de la longitud de las antenas y las alas. Los datos de 9 Af y 6 Apf se han medido de la siguiente manera: Af: (1,24, 1,27) Apf : (1.14,1.82), (1.18,1.96), (1.20,1.86), (1.26,2.00), (1.28,2.00), (1.30,1.96).
Ahora la pregunta es:
(i) Sobre la base de la información anterior, cómo desarrollar un método para distinguir correctamente entre los dos tipos de mosquitos.
(ii) Se identificaron tres especímenes con antenas y alas de (1,24, 1,80), (1,28, 1,84) y (1,40, 2,04) utilizando el método obtenido.
El problema anterior es representativo, y su característica es que se requiere formular un método de clasificación a partir de información conocida (datos de 9 ramas de Af y datos de 6 ramas de -353- Apf), y la categoría ya está dada (Af o Apf). En el futuro, nos referiremos a los conjuntos de datos de 9 Af y 6 Apf como muestras de aprendizaje.
Implementación de Matlab (he dado notas detalladas para cada paso aquí, no se harán otras instrucciones)
clear
p1=[1.24,1.27;1.36,1.74;1.38,1.64;1.38,1.82;1.38,1.90;
1.40,1.70;1.48,1.82;1.54,1.82;1.56,2.08]; %9支Af的触角和翅膀的长度存在p1中
p2=[1.14,1.82;1.18,1.96;1.20,1.86;1.26,2.00
1.28,2.00;1.30,1.96]; %6支APf的触角和翅膀的长度存在p2中
p=[p1;p2]'; %将p1和p2合成一个矩阵并取转置,得到2行15列的矩阵p,第一列表示触角,第二列表示翅膀
pr=minmax(p); %求出P两列的最小值和最大值存在pr中
goal=[ones(1,9),zeros(1,6);zeros(1,9),ones(1,6)]; %写出已经15支的输出矩阵,Af为(1.0),Apf为(0,1)
plot(p1(:,1),p1(:,2),'h',p2(:,1),p2(:,2),'o') %把Af的触角~翅膀,及Apf触角~翅膀散点图画在同一个图中
net=newff(pr,[3,2],{'logsig','logsig'}); %用newff函数创建一个神经网络,隐藏层为3节,输出层为2节,隐藏层和输出层的传递函数均为logsig
net.trainParam.show = 10; %两次显示直接的训练字数(没有时取NAN)
net.trainParam.lr = 0.05; %学习速率为0.05
net.trainParam.goal = 1e-10; %训练目标
net.trainParam.epochs = 50000; %最大训练次数
net = train(net,p,goal); %从输入p到输出goal用已创建的net训练
x=[1.24 1.80;1.28 1.84;1.40 2.04]'; %输入想要预测的三支的触角和翅膀数据
y0=sim(net,p) %已知P的仿真,这里p即作为训练数据又作为仿真数据
y=sim(net,x)%对未知类型的x中三支进行仿真预测Los tentáculos~alas de Af, y los tentáculos~alas de Apf están dibujados en la misma figura 1,
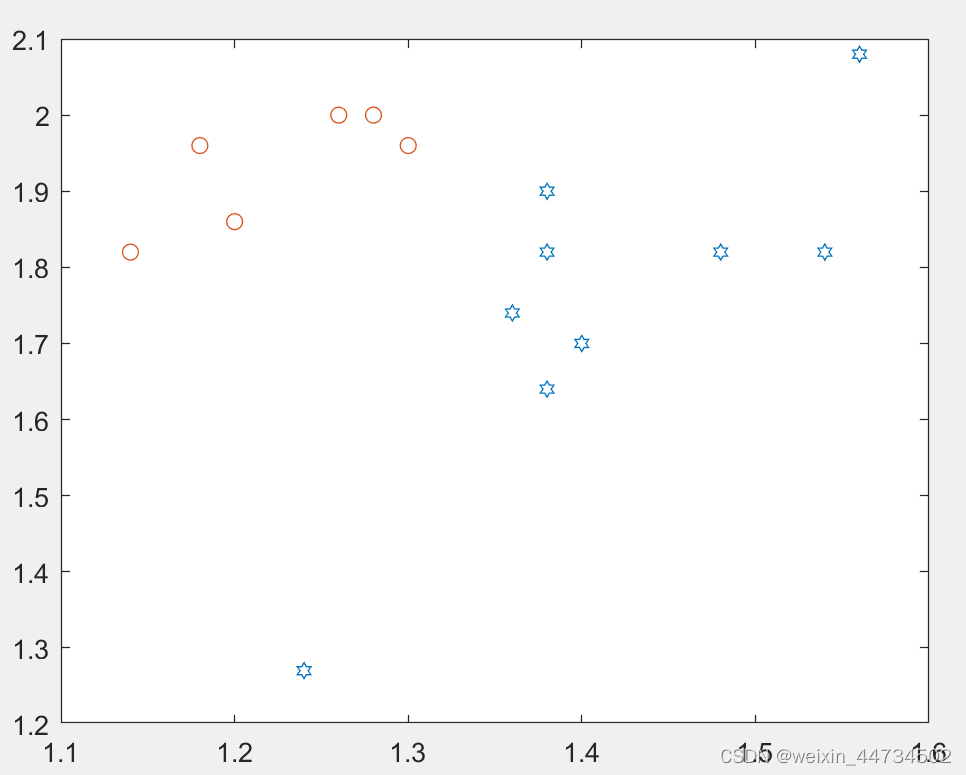
Figura 1
De hecho, podemos encontrar fácilmente que los datos de las alas de antena de los dos tipos de ácaros se distribuyen de manera diferente. Por supuesto, esto es solo un juicio intuitivo. Usaremos la red entrenada para la simulación aquí. lograr el mejor rendimiento de entrenamiento ( Figura 2).
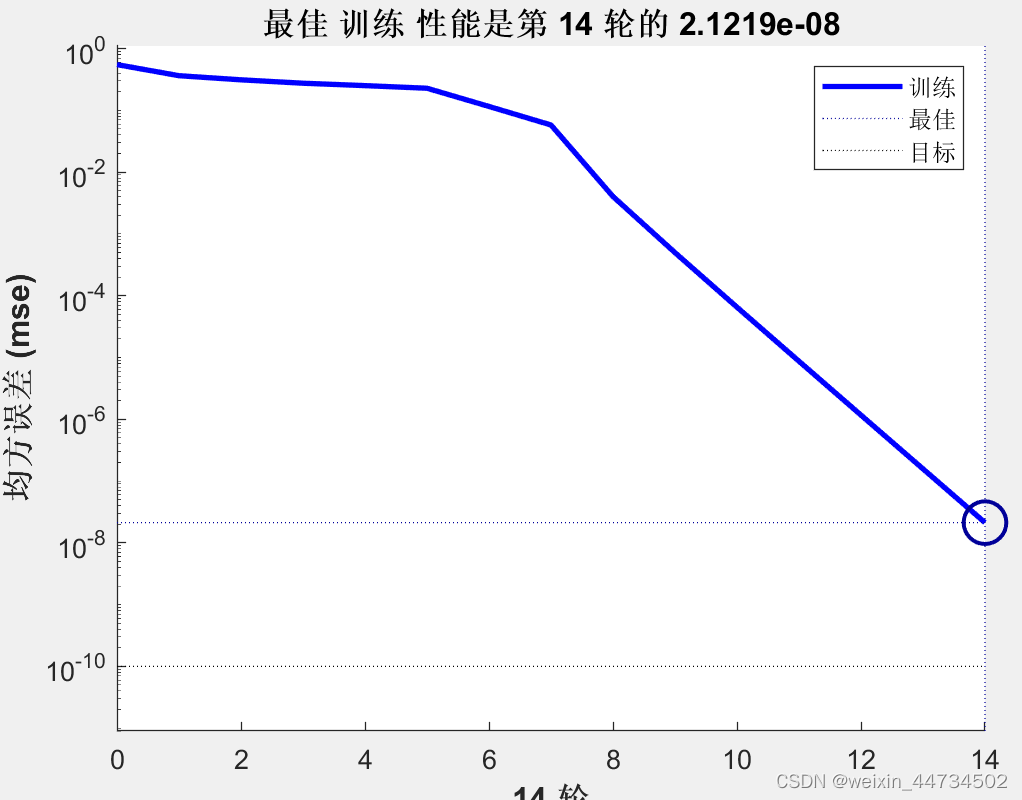
Figura 2
Usando la red entrenada para simular los datos conocidos de 15 ácaros, los resultados se muestran en la Tabla 1
| 1 | 2 | 3 | 5 | 5 | 6 | 7 | 8 | 9 |
| 0.9999 | 0.9999 | 0.9999 | 0.9999 | 0.9994 | 0.9999 | 1.0000 | 1.0000 | 1.0000 |
| 0.0001 | 0.0001 | 0.0000 | 0.0000 | 0.0001 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| 10 | 11 | 12 | 13 | 14 | 15 |
| 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0001 | 0.0005 |
| 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.9999 | 0.9994 |
tabla 1
Podemos encontrar que aunque los resultados de la simulación no son 100% iguales a los resultados objetivo, definitivamente cumplen con los estándares de clasificación.
Use la red entrenada para clasificar las tres muestras de (1.24, 1.80), (1.28, 1.84) y (1.40, 2.04), y los resultados se muestran en la Tabla 2
| 1 | 2 | 3 |
| 0.0001 | 0.0008 | 0.9503 |
| 0.9996 | 0.9974 | 0.0294 |
Tabla 2
Entonces (1.24,1.80), (1.28,1.84) pertenece a Apf, (1.40,2.04) pertenece a Af.
4.2 Problemas de mapeo no lineal
Una función importante de la red neuronal BP es el mapeo no lineal, que es muy adecuado para la aproximación de funciones, etc. Simplemente hablando, es para averiguar la relación entre dos conjuntos de datos.
Ejemplo 2 Se conocen el vector de entrada P y el vector objetivo T, y se establece una red de BP para averiguar la relación entre P y T. Se sabe que P= -1:0.1:1;
T=[-0,96 -0,577 -0,0729 0,377 0,641 0,66 0,461 0,1336 -0,201 -0,434 -0,5 -0,393 -0,1647 0,0988 0,3072 0,396 0,3449 0,1816 -0,0312 -0,321]];
Solución: El vector de entrada P y el vector de destino T son respectivamente:
>>P= -1:0.1:1;
>>T=[-0.96 -0.577 -0.0729 0.377 0.641 0.66 0.461 0.1336 -0.201 -0.434 -0.5 -0.393 -0.1647 0.0988 0.3072 0.396 0.3449 0.1816 -0.03103 -0.3];
Primero, use newff para crear una red neuronal BP, el código es:
>>net=newff([-1,1],[5,1],{'tansig','purelin'});
Entre ellos, [-1,1] representa los valores mínimo y máximo del vector de entrada P, que puede ser reemplazado por minmax(P). [5,1] significa que la capa oculta de la red tiene 5 neuronas, y la capa de salida tiene 1 neurona, es decir, la red neuronal BP es una red neuronal con una estructura 1-5-1. {'tansig','purelin'} significa que la función de transferencia de la capa oculta de la red es tansig, y la función de transferencia de la capa de salida es purelin. Dado que la función de entrenamiento no está configurada especialmente, la función de entrenamiento toma el valor predeterminado trainlm.
En segundo lugar, establezca los parámetros de entrenamiento y entrene la red. El código es:
>>net.trainParam.epochs=200; % de tiempos máximos de entrenamiento
>>net.trainParam.goal=0; % objetivo de entrenamiento
>>net.trainParam.show=50; %El número de tiempos de entrenamiento entre dos pantallas
>>net=train(net,P,T); %Función de entrenamiento de red, net in train es la red inicial creada
Finalmente, simule el entrenamiento entrenado para obtener el resultado de salida de la red Y, y dibuje un gráfico. El código es:
>> Y=sim(neto,P);
La implementación de Matlan es la siguiente
P= -1:0.1:1;
T=[-0.96 -0.577 -0.0729 0.377 0.641 0.66 0.461 0.1336 -0.201 -0.434 -0.5 -0.393 -0.1647 0.0988 0.3072 0.396 0.3449 0.1816 -0.0312 -0.2183 -0.3201];
net=newff([-1,1],[5,1],{'tansig','purelin'});
net.trainParam.epochs=200; %最大训练次数
net.trainParam.goal=0; %训练目标
net.trainParam.show=50; %两次显示之间的训练次数
net=train(net,P,T); %网络训练函数,train中的net为创建的初始网络
Y=sim(net,P)%用训练好的网络对P仿真
plot(P,T,'-',P,Y,'o')%把训练样本和仿真画在一个图中El mejor rendimiento de entrenamiento es la curva de error 2.7485e-06 en la época 61, como se muestra en la Fig. 3. Para una comprensión más intuitiva de la relación entre la salida de la red y el vector de destino, consulte la Figura 4.
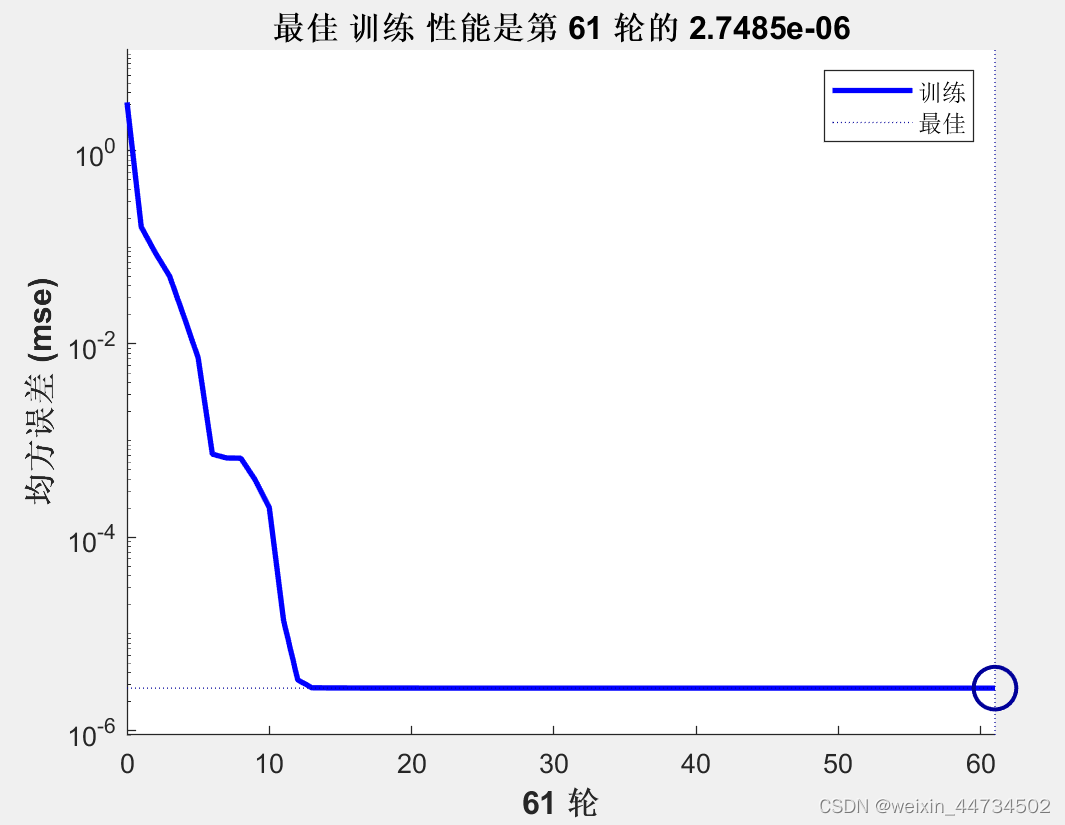
Figura 3 Curva de error de entrenamiento de la red neuronal BP
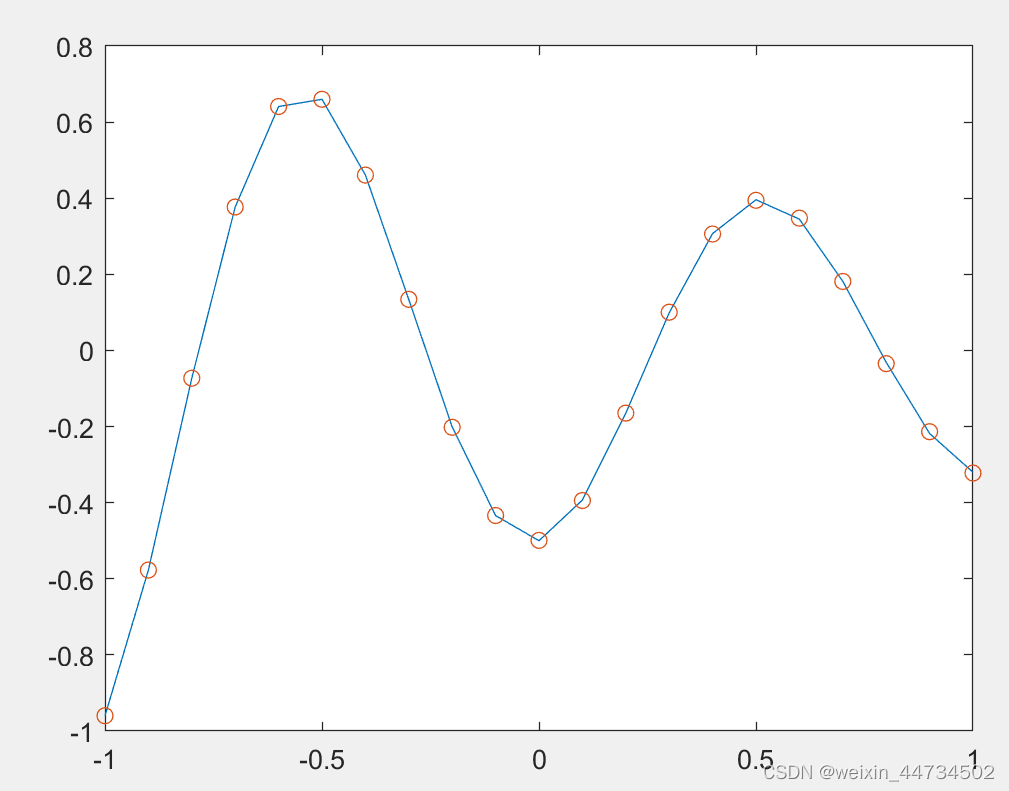
Figura 4 Diagrama de simulación de la red neuronal BP después del entrenamiento
Durante el entrenamiento de la red, el editor encontró algo muy interesante. La cantidad de tiempos de entrenamiento óptimos para la red es diferente cada vez. Esto se debe a que los resultados de la red neuronal son diferentes cada vez porque los pesos y umbrales inicializados son aleatorios. Es posible encontrar un resultado más ideal solo si los resultados son diferentes cada vez. Después de encontrar un resultado mejor, use el comando save filename net; para guardar la red, el resultado previsto no cambiará, y use el comando load filename net cuando vocación.
4.3 Problema de predicción
Ejemplo 3 Pronóstico del volumen de carga, use los datos del Anuario estadístico de China de 1990 a 2011 y use cinco indicadores que incluyen el producto nacional bruto, la producción bruta de energía, el volumen comercial de importación y exportación, las ventas minoristas totales de bienes de consumo social y la inversión total en activos fijos Los factores principales y el uso de la red neuronal BP para predecir la cantidad total de carga.
El monto total del flete y algunos datos de los principales factores de 1990 a 2011
| años |
flete total (10.000 toneladas) |
Producto Nacional Bruto (100 millones de yuanes) |
Valor bruto de producción de energía ( 10.000 toneladas ) |
Volumen de comercio de importación y exportación (100 millones de yuanes) |
Las ventas minoristas totales de bienes de consumo social |
Inversión total en activos fijos |
| 1990 |
970602 |
18718.3 |
103922 |
5560.1 |
8300.1 |
6955.81 |
| 1991 |
985793 |
21826.2 |
104844 |
7225.8 |
9415.6 |
9810.4 |
| 1992 |
1045899 |
26937.3 |
107256 |
9119.6 |
10993.7 |
12443.12 |
| 1993 |
1115902 |
35260 |
111059 |
11271 |
14270.4 |
14410.22 |
| 1994 |
1180396 |
48108.5 |
118729 |
20381.9 |
18622.9 |
17042.94 |
| 1995 |
1234938 |
59810.5 |
129034 |
23499.9 |
23613.8 |
20019.3 |
| 1996 |
1298421 |
70142.5 |
133032 |
24133.8 |
28360.2 |
22974 |
| 1997 |
1278218 |
78060.9 |
133460 |
26967.2 |
31252.9 |
24941.1 |
| 1998 |
1267427 |
83024.3 |
129834 |
26849.7 |
33378.1 |
28406.2 |
| 1999 |
1293008 |
88479.2 |
131935 |
29896.2 |
35647.9 |
29854.7 |
| 2000 |
1358682 |
98000.5 |
135048 |
39273.2 |
39105.7 |
32917.7 |
| 2001 |
1401786 |
108068.2 |
143875 |
42183.6 |
43055.4 |
37213.5 |
| 2002 |
1483447 |
119095.7 |
150656 |
51378.2 |
48135.9 |
43499.9 |
| 2003 |
1564492 |
134977 |
171906 |
70483.5 |
52516.3 |
55566.6 |
| 2004 |
1706412 |
159453.6 |
196648 |
95539.1 |
59501 |
70477.43 |
Solución: establecimiento del modelo: utilizar la red neuronal de BP para la predicción. Primero, determine la estructura de la red en función de los datos de entrada/salida. Y determine los datos de entrenamiento para entrenar la red, de modo que la red tenga capacidad predictiva. Luego, determine los datos de prueba para probar el rendimiento predictivo de la red. Finalmente, el volumen total de carga se pronostica con base en la red capacitada.
Dado que los datos de entrada en este ejemplo son de 5 dimensiones y la salida es de 1 dimensión, la estructura de la red neuronal de BP es 5-9-1. Es decir, la capa de entrada son los datos normalizados de cinco factores principales, incluidos el producto nacional bruto, la producción bruta de energía, el volumen comercial de importación y exportación, las ventas minoristas totales de bienes de consumo social y la inversión total en activos fijos, y la producción es el monto total del flete. La capa contenedora tiene 9 nodos (se puede ajustar según la situación). Y seleccione tansig como función de transferencia de capa oculta y la función lineal f(x)=x como función de transferencia de capa de salida.
Se sabe que hay 22 años de datos, y los datos de los primeros 20 años se utilizan como datos de entrenamiento para entrenar la red. Debido a la pequeña cantidad de datos, los datos de entrenamiento se utilizan como datos de prueba para determinar el rendimiento de predicción de la red y, finalmente, para predecir el volumen total de carga en 2010 y 2011.
Solución modelo: Según el principio de la red neuronal BP, se programa en Matlab.
(1) Procesamiento de datos: los datos de la tabla se almacenan en e4_3.xls. Llame a los datos de la misma manera que se indicó anteriormente para la asignación de datos y normalice los datos. El proceso de normalización de datos convierte todos los datos en números entre [0,1]. El propósito es eliminar la diferencia de magnitud entre los datos y evitar grandes errores de predicción de red debido a la gran diferencia en la magnitud de los datos de entrada y salida. Hay muchos métodos de normalización. En este ejemplo, se utiliza el método de normalización máximo y mínimo. La función de normalización utiliza la función mapminmax que viene con Matlab. Hay muchas formas de esta función, y los métodos comúnmente utilizados son los siguientes:
[x1,ps] = mapminmax(x)
Donde x son los datos a normalizar, x1 son los datos normalizados y ps es la estructura normalizada, que contiene información como el valor máximo, el valor mínimo y el valor promedio de los datos x. El método para desnormalizar los datos normalizados x1 es:
x = mapminmax('reversa',x1,ps)
Si es necesario utilizar la estructura ps normalizada de los datos x para normalizar los nuevos datos y, como los datos de prueba y los datos de predicción en la red neuronal, el método es el siguiente:
y1 = mapminmax('aplicar',y,ps)
Entre ellos, y1 son los datos normalizados de los datos y, y el método de procesamiento de desnormalización de y1 es el mismo que el anterior.
(2) Inicialización de la red neuronal de BP: según la estructura 5-9-1 de la red neuronal de BP, los pesos y umbrales de la red neuronal de BP se inicializan aleatoriamente.
(3) Entrenamiento de la red neuronal BP: use los datos de entrenamiento para entrenar la red neuronal BP y ajuste el peso y el umbral de la red de acuerdo con el error de predicción de la red.
(4) Prueba de red neuronal BP: prueba el rendimiento de predicción de la red neuronal BP con datos de prueba.
(5) Pronóstico de la red neuronal de BP: ingrese los factores principales en 2010 y 2011, y use la red entrenada para predecir la cantidad total de carga en estos dos años.
(6) Resultados de predicción: A partir de los resultados de los datos de prueba, el porcentaje de error máximo de la prueba de red neuronal BP es de aproximadamente 4 %. Los resultados de la prueba se muestran en la Figura 12-23. Se puede considerar que la red BP tiene buenos resultados. capacidad predictiva. Los resultados previstos de volumen de carga en 2010 y 2011 son 31.331.470.000 toneladas y 3.370.948 toneladas, respectivamente, y los porcentajes de error son 3,35% y 8,82%, que se acercan relativamente a los resultados reales.
La implementación de Matlab es la siguiente
clc;clear all %情况变量环境
[xdata,textdata]=xlsread('e4_3.xls'); %读取货运量数据
[n,m]=size(xdata);
Train_Num=20; %输入样本数量为20
Test_Num=Train_Num; %测试样本数量也是20
Sim_Num=2; %预测样本数量为6
%提取输入Input和输出Output数据
Input=[xdata(1:Train_Num,3) xdata(1:Train_Num,4) xdata(1:Train_Num,5) xdata(1:Train_Num,6) xdata(1:Train_Num,7)]';
Output=xdata(1:Train_Num,2)';
%%%数据归一化处理
[Inputn,In_ps]=mapminmax(Input,0,1); %输入数据归一化
[Outputn,Out_ps]=mapminmax(Output,0,1); %输出数据归一化
Train_Input=Inputn(:,1:Train_Num); %训练数据输入
Test_Input=Train_Input; %测试数据输入
Train_Output=Outputn(:,1:Train_Num); %训练数据输出
Test_Output=Train_Output; %测试数据输出
Input_Num=5; %输入节点个数
Hidd_Num=9; %中间层隐节点数量取9
Out_Num=1; %网络输出维度为1
MaxEpochs=50000; %最多训练次数为50000
lr=0.01; %学习速率为0.01
E0=0.45*10^(-2); %目标误差为0.45*10^(-2)
W1=0.5*rand(Hidd_Num,Input_Num)-0.1; %初始化输入层与隐含层之间的权值
B1=0.5*rand(Hidd_Num,1)-0.1; %初始化输入层与隐含层之间的阈值
W2=0.5*rand(Out_Num,Hidd_Num)-0.1; %初始化输出层与隐含层之间的权值
B2=0.5*rand(Out_Num,1)-0.1; %初始化输出层与隐含层之间的阈值
ErrHistory=[]; %给中间变量预先占据内存
for i=1:MaxEpochs
HiddenOut=logsig(W1*Train_Input+repmat(B1,1,Train_Num)); % 隐含层网络输出 9x5x5x20+9x20=9x20
NetworkOut=W2*HiddenOut+repmat(B2,1,Train_Num); % 输出层网络输出
Error=Train_Output-NetworkOut; % 实际输出与网络输出之差
SSE=sumsqr(Error) %能量函数(误差平方和)
ErrHistory=[ErrHistory SSE];
if SSE<E0,break, end %如果达到误差要求则跳出学习循环
% 以下是BP网络最核心的程序
% 它们是权值(阈值)依据能量函数负梯度下降原理所作的每一步动态调整量
Delta2=Error;
Delta1=W2'*Delta2.*HiddenOut.*(1-HiddenOut);
dW2=Delta2*HiddenOut';
dB2=Delta2*ones(Train_Num,1);
dW1=Delta1*Train_Input';
dB1=Delta1*ones(Train_Num,1);
%对输出层与隐含层之间的权值和阈值进行修正
W2=W2+lr*dW2;
B2=B2+lr*dB2;
%对输入层与隐含层之间的权值和阈值进行修正
W1=W1+lr*dW1;
B1=B1+lr*dB1;
end
HiddenOut=logsig(W1*Test_Input+repmat(B1,1,Test_Num)); % 隐含层输出最终结果
NetworkOut=W2*HiddenOut+repmat(B2,1,Test_Num); % 输出层输出最终结果
Test_Out=mapminmax('reverse',NetworkOut',Out_ps); % 还原网络输出层的结果,得到测试数据网络实际输出
Error=Test_Out-Output'; % 网络实际输出Test_Out与期望输出Output之间的误差
Error_bi=Error./Output'; % 网络实际输出与期望输出之间的误差比
%%%BP神经网络预测 输入为2010年和2011年主要因素
Sim_Input=[xdata(Train_Num+1:end,3) xdata(Train_Num+1:end,4) xdata(Train_Num+1:end,5) xdata(Train_Num+1:end,6) xdata(Train_Num+1:end,7)]';
Sim_Output=xdata(Train_Num+1:end,2)';
Sim_Input=mapminmax('apply',Sim_Input,In_ps);
HiddenOut=logsig(W1*Sim_Input+repmat(B1,1,Sim_Num)); % 隐含层输出最终结果
NetworkOut=W2*HiddenOut+repmat(B2,1,Sim_Num); % 输出层输出最终结果
Sim_Out=mapminmax('reverse',NetworkOut',Out_ps); % 还原网络输出层的结果
Error=Sim_Out-Sim_Output'; % 网络预测输出Sim_Out与期望输出Sim_Output之间的误差
baifenbi=Error./Sim_Output'; % 网络预测输出与期望输出之间的误差比
figure(1)
time1=1:Train_Num;
plot(time1+1989,Test_Out,'r-o',time1+1989,Output(1:Train_Num),'b--+')
legend('网络测试输出货运量','实际货运总量');
xlabel('年份');ylabel('货运总量/万吨');
% figure(2)
% time2=Train_Num+1:22;
% plot(time2+1989,Sim_Out,'r-o',time2+1989,Sim_Output,'b--+')
El mejor rendimiento de entrenamiento es 0.00099919 en la ronda 775 como se muestra en la Figura 5
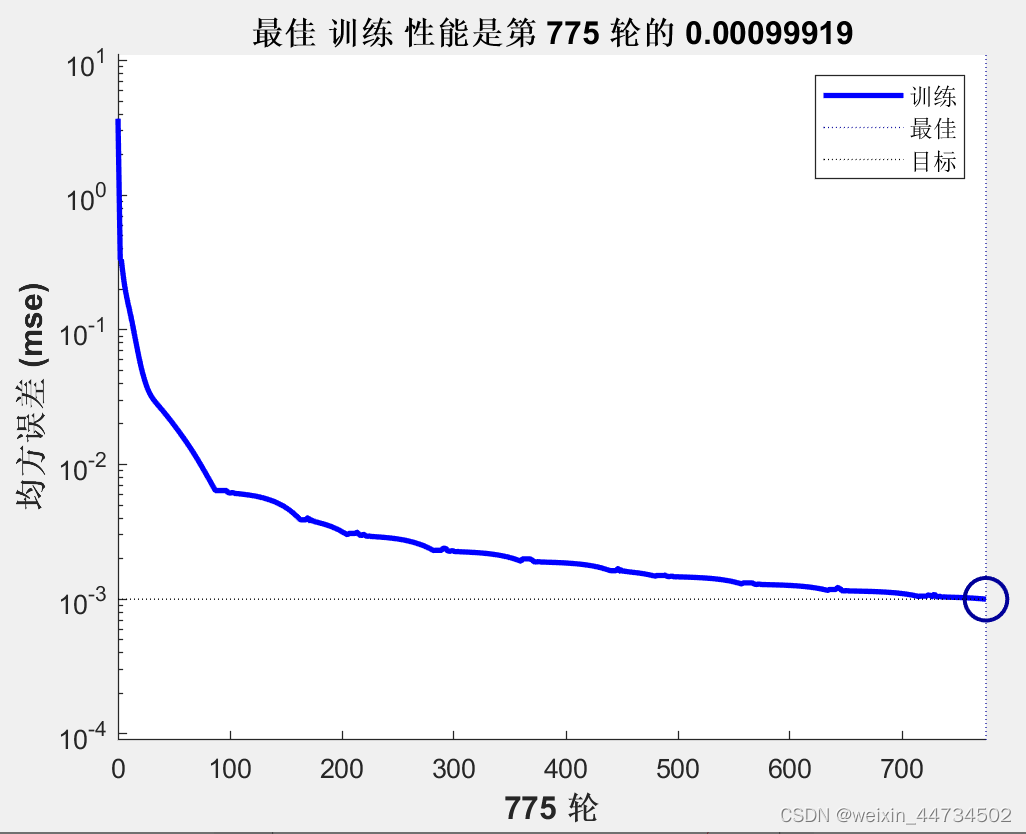
Figura 5
Los resultados de la prueba de la red neuronal de BP se muestran en la Figura 6
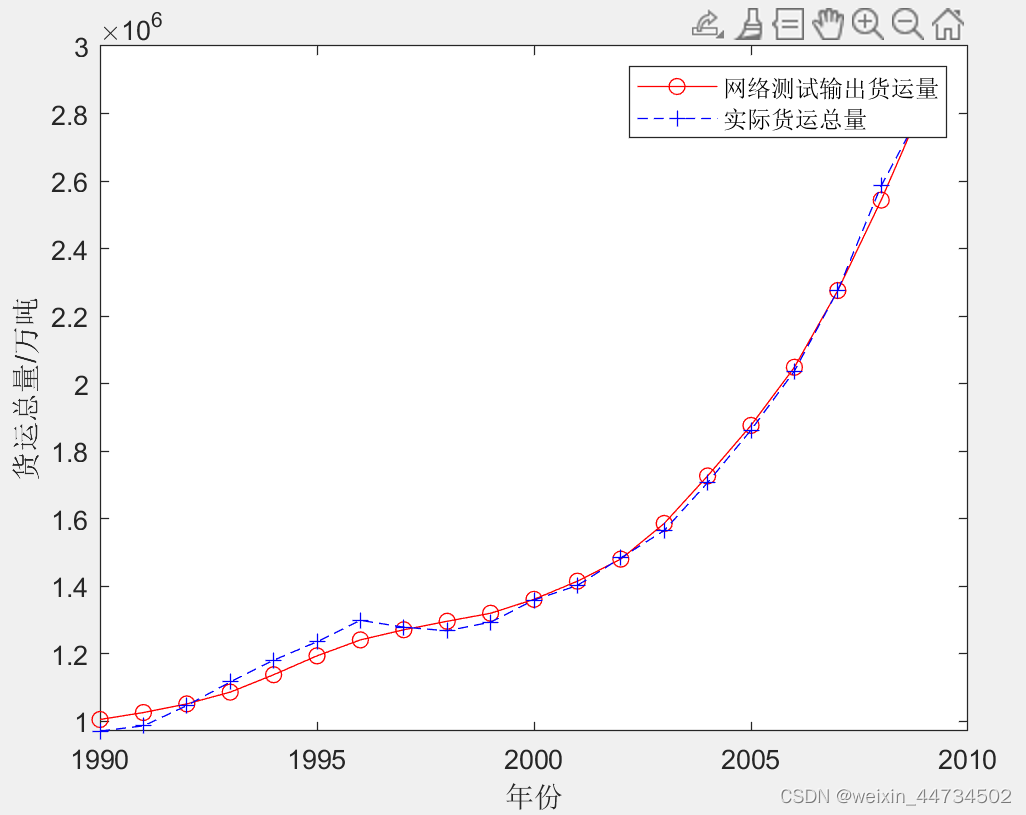
Figura 6
Los datos del volumen de carga pronosticado para 2010 y 2011 se muestran en la Figura 7, y la línea roja representa el valor pronosticado
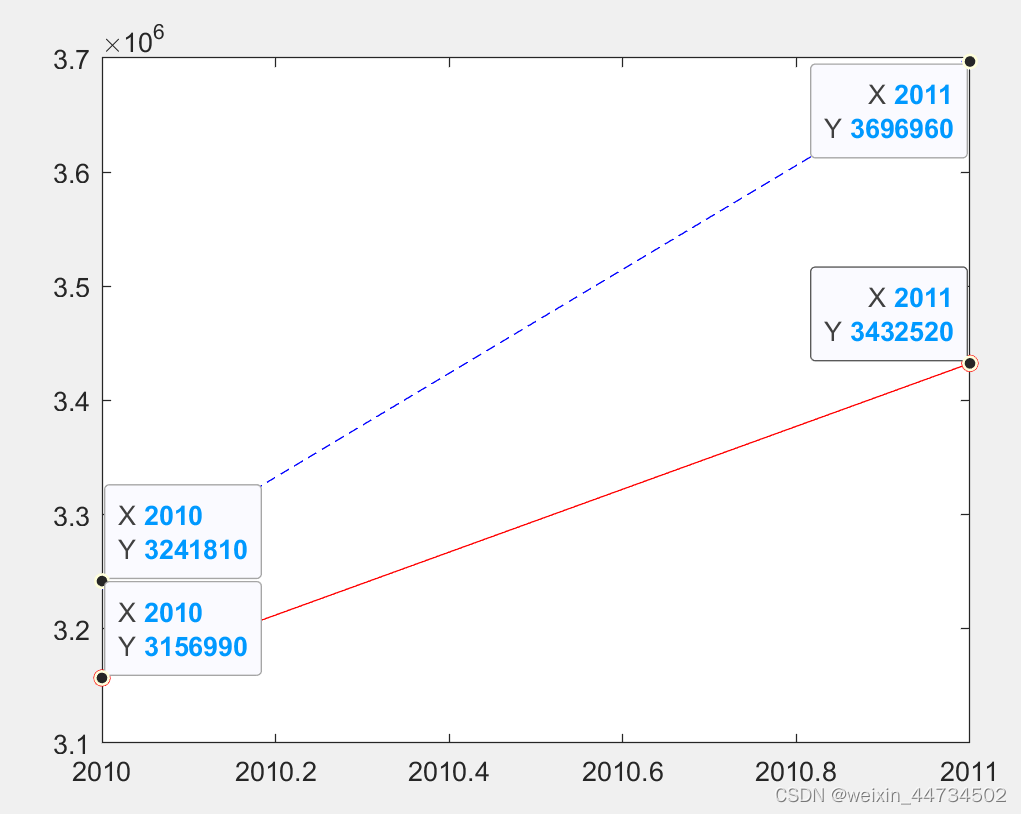
Figura 7
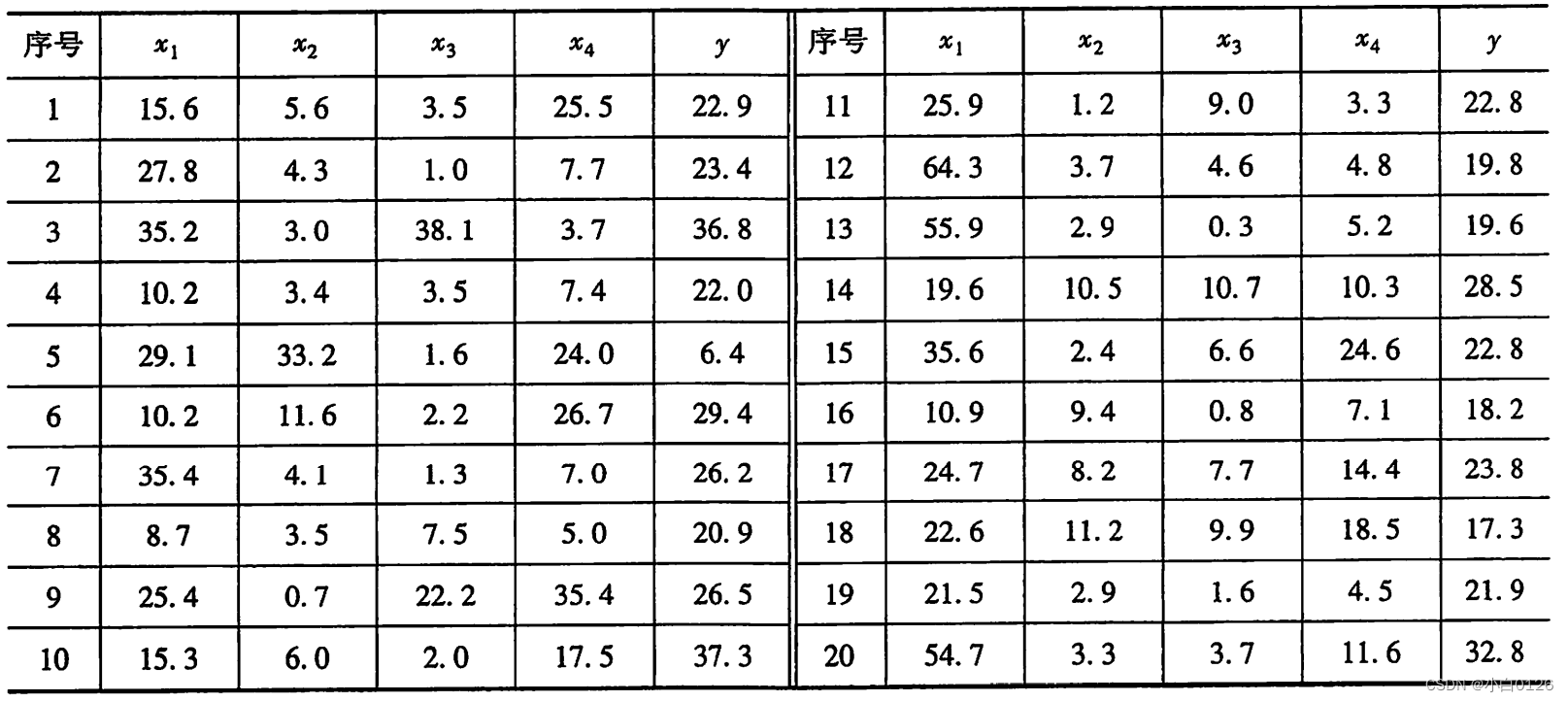
Ejemplo 4 Los datos de escorrentía existentes de un embalse determinado y los datos medidos correspondientes de cuatro predictores anteriores se muestran en la siguiente tabla. Los cuatro predictores son la precipitación total x1 del embalse en noviembre y diciembre del año anterior, y la precipitación de enero, Febrero y marzo del año en curso La precipitación x2,x3,x4. En este ejemplo, estos cuatro predictores se usan como entrada, y la escorrentía anual se usa como salida para formar una red con cuatro entradas y una salida. Los primeros 19 datos medidos se usan como un conjunto de muestras de entrenamiento, y los últimos datos medidos son utilizado como muestra de prueba de predicción.
entrenamiento en red
Es muy conveniente utilizar la caja de herramientas de red neuronal proporcionada por Matlab para realizar la función de la red neuronal artificial. Dado que hay cuatro variables independientes y una variable dependiente en el pronóstico de escorrentía anual, la cantidad de neuronas de entrada se toma como 4, la cantidad de neuronas de salida se toma como 1 y la cantidad de neuronas de la capa intermedia oculta, la red neuronal de BP necesita se basará en la experiencia Determinada, la red neuronal RBF se determinará de forma adaptativa durante el proceso de entrenamiento.
La red neuronal de BP tiene algunas desventajas, como una convergencia lenta, la red es fácil de caer al mínimo local y el proceso de aprendizaje a menudo oscila. Para la predicción de este caso, cuando el número de capas ocultas de la red neuronal de BP se establece en 4, los resultados del cálculo son relativamente estables.Cuando el número de capas ocultas se establece en otros valores, los resultados de ejecución son particularmente inestables y los resultados de cada ejecución varían mucho.
Usando la caja de herramientas de Matlab para obtener el vigésimo punto de muestra, el valor predicho de la red neuronal RBF es 26,7693 y el error relativo es 18,39 % El resultado de la predicción del modelo de red neuronal RBF es mejor que el del modelo de red neuronal BP.
El código de Matlab es el siguiente
clc, clear
a=load('l_4.txt'); %把表中的数据保存到文本文件l_4.txt
a=a'; %注意神经网络的数据格式,不要将转置关系搞错
P=a([1:4],[1:end-1]); [PN,PS1]=mapminmax(P); %自变量数据规格化到[-1,1]
T=a(5,[1:end-1]); [TN,PS2]=mapminmax(T); %因变量数据规格化到[-1,1]
net1=newrb(PN,TN) %训练RBF网络
x=a([1:4],end); xn=mapminmax('apply',x,PS1); %预测样本点自变量规格化
yn1=sim(net1,xn); y1=mapminmax('reverse',yn1,PS2) %求预测值,并把数据还原
delta1=abs(a(5,20)-y1)/a(5,20) %计算RBF网络预测的相对误差
net2=feedforwardnet(4); %初始化BP网络,隐含层的神经元取为4个(多次试验)
net2 = train(net2,PN,TN); %训练BP网络
yn2= net2(xn); y2=mapminmax('reverse',yn2,PS2) %求预测值,并把数据还原
l_4.txt
15.6 5.6 3.5 25.5 22.9
27.8 4.3 1.0 7.7 23.4
35.2 3.0 38.1 3.7 36.8
10.2 3.4 3.5 7.4 22.0
29.1 33.2 1.6 24.0 6.4
10.2 11.6 2.2 26.7 29.4
35.4 4.1 1.3 7.0 26.2
8.7 3.5 7.5 5.0 20.9
25.4 0.7 22.2 35.4 26.5
15.3 6.0 2.0 17.5 37.3
25.9 1.2 9.0 3.3 22.8
64.3 3.7 4.6 4.8 19.8
55.9 2.9 0.3 5.2 19.6
19.6 10.5 10.7 10.3 28.5
35.6 2.4 6.6 24.6 22.8
10.9 9.4 0.8 7.1 18.2
24.7 8.2 7.7 14.4 23.8
22.6 11.2 9.9 18.5 17.3
21.5 2.9 1.6 4.5 21.9
54.7 3.3 3.7 11.6 32.8
5. Ventajas y desventajas del modelo de red neuronal
La red neuronal de BP es relativamente madura tanto en la teoría como en el rendimiento de la red. Sus ventajas sobresalientes son su fuerte capacidad de mapeo no lineal y su estructura de red flexible. La cantidad de capas intermedias de la red y la cantidad de neuronas en cada capa se pueden establecer arbitrariamente según la situación específica, y el rendimiento también es diferente con la diferencia de la estructura. Sin embargo, la red neuronal de BP también tiene algunos defectos importantes, como se indica a continuación.
① La velocidad de aprendizaje es lenta Incluso para un problema simple, generalmente se necesitan cientos o incluso miles de veces de aprendizaje para converger.
②Es fácil caer en el mínimo local.
③ No existe una guía teórica correspondiente para la selección del número de capas de red y el número de neuronas.
④La capacidad de promoción de la red es limitada.