Red neuronal multicapa
Para superar las limitaciones de la red neuronal de una sola capa, la red neuronal evolucionó gradualmente hacia una estructura de múltiples capas. Sin embargo, para el entrenamiento de redes neuronales multicapa, la regla delta [ análisis de redes neuronales (capa única) ] que mencioné en el artículo anterior no es válida, porque esta regla de aprendizaje no especifica cómo calcular el error de la capa oculta. Hasta unas décadas después, alguien propuso el algoritmo de retropropagación, que es una regla de aprendizaje representativa de las redes neuronales multicapa, por lo que este artículo se centra principalmente en el algoritmo BP. (La programación involucrada en el artículo no proporciona el código, puede intentar programarlo usted mismo, si realmente no puede, puede ver el código MATLAB del recurso que publiqué )
1. Algoritmo de retropropagación
En el algoritmo de retropropagación, el error de salida se mueve hacia atrás desde la capa de salida capa por capa hasta que alcanza la capa oculta adyacente a la capa de entrada, por lo que estipula las reglas de cálculo de error de la capa oculta. Para facilitar la comprensión, se ofrece un ejemplo sencillo para ilustrar este algoritmo.
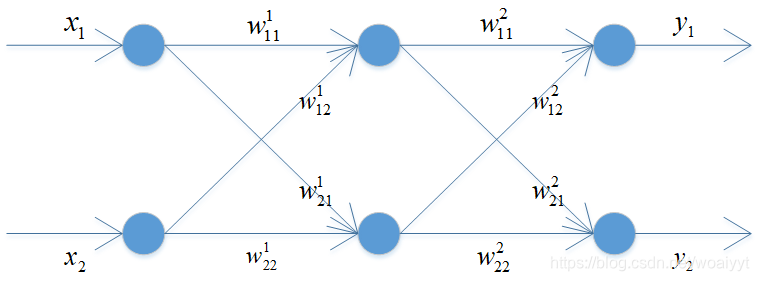
El proceso de cálculo desde los datos de entrada hasta el valor de salida del nodo de salida puede referirse a la red neuronal de una sola capa que escribí [ Análisis de la red neuronal (capa única) ]. Después de obtener la salida de la red neuronal, el siguiente paso es el núcleo del cálculo del error del algoritmo de retropropagación. Para el error del nodo de salida, la regla delta generalizada todavía se usa para el cálculo, entonces, ¿cómo calcular el error de salida de la capa oculta? De hecho, también es un cálculo de regla delta generalizado. Lo único que debe entenderse es el cálculo de la retropropagación, y también hay una simetría matemática aquí, es decir, la matriz de cálculo del error de retropropagación es en realidad la transposición de la matriz de peso en la propagación hacia adelante. Comprenda mejor el error de cálculo de la propagación hacia atrás. Escriba una ecuación aquí. El
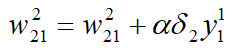
primer término en el lado derecho de la ecuación es uno de los valores de peso. Preste atención a la comprensión de los subíndices y subíndices. El segundo término en el lado derecho de la ecuación utiliza el segundo nodo de salida. El error está relacionado con la salida del primer nodo de capa oculta. ¿Por qué estas dos flechas están relacionadas con los pesos utilizados? Preste atención a la relación entre subíndices y subíndices. Esta ecuación equivale a calcular cada capa por capa a través del error de la capa de salida. El error de la capa oculta, no importa cuántas capas ocultas haya, es similar en pensamiento. A continuación, se muestra un resumen del proceso de formación:
- Inicializar pesos con valores apropiados
- Obtenga la entrada y la salida estándar de los datos de entrenamiento. Después de obtener la salida de la red neuronal, compárela con la salida estándar para calcular el error y δ \ delta del nodo de salidavalor δ
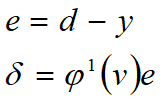
- Nodo de salida de retropropagación δ \ deltaδ valor, calcula elδ \ delta delnodo de capa adyacentevalor δ

- Repita el paso 3 hasta que la capa oculta al lado de la capa de entrada
- Ajustar el peso
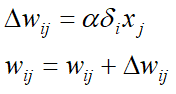
- Repita los pasos 2 a 5 para cada punto de datos de entrenamiento.
- Repita los pasos 2 a 6 hasta que la red neuronal esté debidamente entrenada.
2. Implementar el algoritmo de retropropagación
Considere cuatro puntos de datos, cada punto de datos consta de cuatro datos, respectivamente
[0 0 1 0]
[0 1 1 1]
[1 0 1 1]
[1 1 1 0]
Los últimos datos de cada punto de datos son salida estándar y se ingresan los primeros tres datos. Considere una red neuronal de este tipo, que consta de una capa de entrada compuesta por tres entradas, una capa oculta compuesta por cuatro nodos y una capa de salida compuesta por una salida. La función Sigmoid se utiliza como función de activación y se implementa mediante el método SGD. El problema es en realidad la operación lógica XOR. Después de escribir el algoritmo, pruébelo y entrene la red neuronal 10,000 veces. El resultado final es
[0.0060 0.9888 0.9891 0.0134]'
Se puede ver que es casi igual a la salida estándar, por lo que resuelve perfectamente las limitaciones de la red neuronal monocapa.
3. Función de costos y reglas de aprendizaje
La función de costo es un concepto matemático relacionado con la teoría de la optimización, que es muy fácil de entender. El aprendizaje supervisado de la red neuronal es un proceso de ajuste de pesos para reducir los errores de entrenamiento. La medición del error de la red neuronal es la función de costo. Cuanto mayor es el error de la red neuronal, mayor es el valor de la función de costo, que es una correlación positiva. En el aprendizaje supervisado por redes neuronales, hay dos formas principales de función de costo:
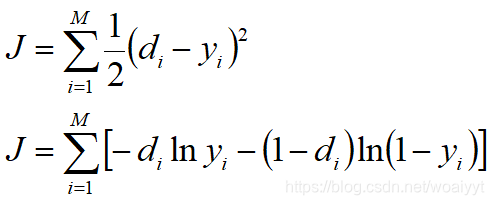
entre ellas, di d_iDyoEs salida estándar, yi y_iyyoEs la salida del nodo de salida, MMM es el número de nodos de salida. La primera forma de función de costo es fácil de entender, es decir, la mitad de la suma de cuadrados del error, simétrica con respecto al eje y, cuanto mayor es la diferencia entre los dos valores, mayor es el valor de la función de costo. La mayoría de las redes neuronales de investigación temprana utilizan esta función de costo para derivar reglas de aprendizaje. Ahora mire la función de costo de la segunda forma. La fórmula entre corchetes se llama función de entropía cruzada. También está correlacionada positivamente con el error, pero la mayor diferencia entre esta y la primera forma es que crece geométricamente. es más sensible a los errores, por lo que muchas personas ahora usan las reglas de aprendizaje derivadas de la función de entropía cruzada. A continuación, presentaremos en detalle los pasos del algoritmo de retropropagación impulsado por entropía cruzada:
-
Inicializar pesos con valores apropiados
-
Obtenga la entrada y la salida estándar de los datos de entrenamiento. Después de obtener la salida de la red neuronal, compárela con la salida estándar para calcular el error y δ \ delta del nodo de salidavalor δ
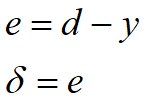
-
Nodo de salida de retropropagación δ \ deltaδ valor, calcula elδ \ delta delnodo de capa adyacentevalor δ
-
Repita el paso 3 hasta que la capa oculta al lado de la capa de entrada
-
Ajustar el peso
-
Repita los pasos 2 a 5 para cada punto de datos de entrenamiento.
-
Repita los pasos 2 a 6 hasta que la red neuronal esté debidamente entrenada.
La diferencia entre este y los pasos introducidos en la primera sección es solo el δ \ delta del nodo de salidaEl cálculo del valor δ , aunque la diferencia es insignificante en la superficie, contiene el principal problema de la función de costo basada en la teoría de optimización. La mayoría de los métodos de entrenamiento de redes neuronales de aprendizaje profundo utilizan reglas de aprendizaje impulsadas por la entropía cruzada. la capa de salida y la capa oculta utilizan diferentes fórmulas de cálculo delta.
4. Darse cuenta de la función de entropía cruzada
El modelo considerado en esta sección es exactamente el mismo que en la sección 2, y el método de programación es casi el mismo que en la sección 2. La única diferencia es la fórmula de cálculo delta del nodo de salida. La red neuronal se entrena 10.000 veces y el resultado final es
[0.00003 0.9999 0.9998 0.00036]'
De acuerdo con la salida estándar.
5. Comparación de los dos
Debido a que lo que se muestra en la segunda sección es en realidad una regla de aprendizaje impulsada por la primera forma de función de costo, que es la suma de los cuadrados de error, la comparación entre los dos es en realidad una comparación de las reglas de aprendizaje impulsadas por la suma de los cuadrados de error. y la unidad de entropía cruzada. El efecto se muestra en la figura.
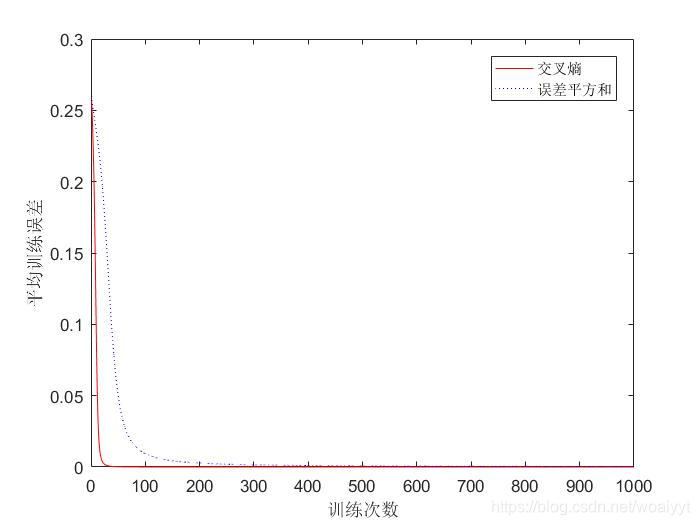
Se puede ver que las reglas de aprendizaje impulsadas por la entropía cruzada pueden reducir los errores a una velocidad más rápida, con mayor eficiencia y mejores efectos de aprendizaje.