guide
GPT-4 has demonstrated remarkable performance on natural language processing (NLP) tasks, including challenging mathematical reasoning. However, most of the existing open source models are only pre-trained on large-scale Internet data and are not optimized for mathematics-related content. This paper introduces a method called WizardMath: to enhance the ability of Llama-2 in mathematical reasoning by applying the method of "reinforcement learning from Evol-Instruct feedback (RLEIF)" to the field of mathematics. The method is extensively experimented on two mathematical reasoning benchmarks (GSM8k and MATH), and the experiments show that WizardMath has a significant advantage over all other open source LLMs. In addition, the author's model even surpasses ChatGPT-3.5, Claude Instant-1, PaLM-2 and Minerva on GSM8k, and also beats Text-davinci-002, PaLM-1 and GPT-3 on MATH.
introduction
ChatGPT is extensively pre-trained on large-scale Internet data, and further fine-tuned with specific instruction data and methods, so it achieves excellent zero-shot capabilities in various benchmarks. Subsequently, Meta's series of Llama models triggered an open source revolution and stimulated the release of MPT8, Falcon, StarCoder, Alpaca, Vicuna, and WizardLM, among others.
However, these open-source models still encounter difficulties in situations that require complex multi-step quantitative reasoning, such as solving difficult mathematical and scientific problems. "Chain-of-thought" (CoT) proposes better-designed hints to generate stepwise solutions, which can lead to improved performance. "Self-Consistency" has also achieved remarkable performance on many inference benchmarks, which generate multiple possible answers from a model and select the correct answer based on a majority vote.
Recent studies have shown that process supervision using reinforcement learning is significantly better than outcome supervision for solving challenging mathematical problems.
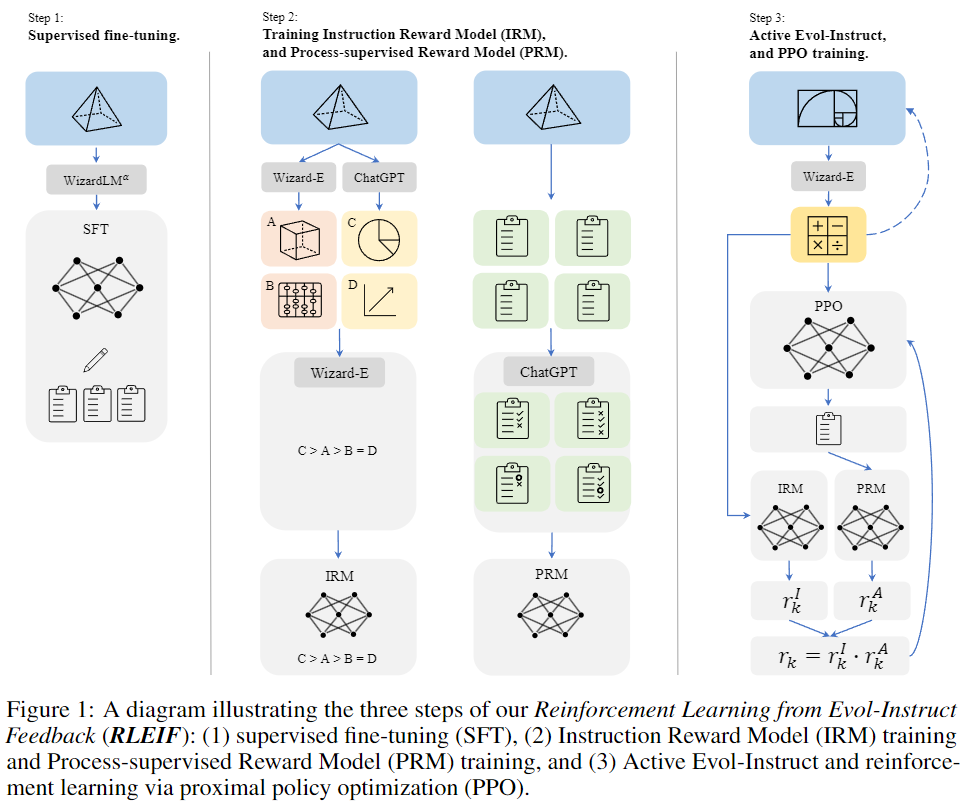
Inspired by Evol-Instruct and process-supervised reinforcement learning, this paper introduces a new method named RLEIF "Reinforcement Learning from Evol-Instruct Feedback (RLEIF)" to improve the ability of LLMs in logical reasoning from data. As shown in Figure 1 above:
- The method firstly generates various math instruction data through math-specific Evol-Instruct.
- We then train an instruction reward model IRM and a process supervision reward model PRM, where the former represents the quality of evolutionary instructions and the latter provides feedback for each step of the solution.
- Finally, PPO reinforcement learning is performed through IRM and PRM.
In order to verify the ability of mathematical logical reasoning, the author conducted experiments on two mathematical reasoning benchmarks (GSM8k and MATH). The results show that: WizardMath in this paper performs well on all other open source LLMs, reaching the SOTA level.
The main contributions of this paper are as follows:
- Introduced the WizardMath model, which enhances the capabilities of the open-source pre-trained large-scale language model Llama-2 in mathematical reasoning.
- A new method, Reinforcement Learning from Evol-Instruct Feedback (RLEIF), is proposed to improve the inference performance of LLM by combining Evol-Instruct and reinforcement learning.
- On the GSM8k and MATH test benchmarks, WizardMath significantly surpasses all other open source LLMs in all aspects, including Llama-2 70B, Llama-1 65B, Falcon-40B, MPT-30B8, Baichuan-13B Chat9 and ChatGLM2 12B.
- On GSM8k, WizardMath significantly surpasses various major closed-source LLMs such as GPT-3.5, Claude Instant, PaLM-2, PaLM-1, and Minerva in pass@1.
method
This paper proposes a method named RLEIF that integrates Evol-Instruct and reinforcement process supervision methods for evolving GSM8k and MATH data, and then fine-tunes the pre-trained LLama-2 model with the evolved data and reward model.
As shown in Figure 1, our method consists of three steps:
Supervised fine-tuning(SFT)
Inheriting the method of InstructGPT, we first use supervised instruction-response instruction pairs to fine-tune the base model, which contains:
- The 15k answers from GSM8k and MATH were regenerated using an alpha version of the WizardLM 70B model to generate solutions in a process-by-procedure manner, and then find the correct answer, using these data to fine-tune the underlying Llama model.
- In order to enhance the model's ability to follow diverse instructions, this paper also samples 1.5k open-domain dialogues from WizardLM's training data, and then merges them with the above mathematical corpus as the final supervised fine-tuning training data.
Evol-Instruct principles for math
Inspired by the Evol-Instruct method proposed by WizardLM and its effective application on WizardCoder, this study attempts to enhance pretrained LLMs by crafting mathematical instructions with different complexity and diversity. Specifically, we adapt Evol-Instruct to a new paradigm, consisting of two evolution lines:
- Downward evolution: The instruction is enhanced by making the problem easier. For example: i) changing a difficult problem to a less difficult one, or ii) generating a new easier problem from a different topic.
- Upward Evolution: Evolved from the original Evol-Instruct method. Deepen and generate more difficult problems by i) adding more constraints, ii) reification, iii) adding reasoning, etc.
Reinforcement Learning from Evol-Instruct Feedback (RLEIF)
Inspired by InstructGPT and PRMs, the authors train two reward models to predict the quality of the instruction and the correctness of each step in the answer, respectively:
-
Instruction Reward Model (IRM): This model aims to judge the quality of evolutionary instructions from three aspects: i) definition, ii) precision, and iii) completeness. To generate the ranking list training data for IRM, for each instruction, the authors first use ChatGPT and Wizard-E 4 to generate 2 4 evolved instructions respectively. Then use Wizard-E to rank the quality of these 48 instructions.
-
Process Supervised Reward Model (PRM): Since there were no powerful open-source LLMs for mathematical reasoning prior to this work, there was no easy way to support highly accurate process supervision. Therefore, the authors rely on ChatGPT to provide process supervision and ask it to evaluate the correctness of each step in the solution generated by our model.
-
Reinforcement Learning PPO Training. The author increased the data size from 15k to 96k through 8 rounds of evolution of the original mathematical instructions (GSM8k + MATH). They use IRM and PRM to generate instruction reward (rI) and answer reward (rA). These two rewards are then multiplied together as the final reward r = rI · rA.
experiment
This article mainly evaluates WizardMath on two benchmarks GSM8k and MATH. The GSM8k dataset contains approximately 7500 training data and 1319 test data, mainly covering mathematics problems in elementary school, each problem includes basic arithmetic operations (addition, subtraction, multiplication and division), and usually requires 2 to 8 steps to solve .
The MATH dataset collects math problems from famous math competitions such as AMC 10, AMC 12, and AIME. It contains 7500 training data sets and 5000 challenging test data sets covering seven academic areas: Elementary Algebra, Algebra, Number Theory, Counting and Probability, Geometry, Intermediate Algebra, and Pre-Calculus. In addition, the questions are classified into five difficulty levels, where "1" indicates a relatively low level of difficulty and "5" indicates the highest level.
Index evaluation
::: block-1

On the pass@1 evaluation index in the GSM8k benchmark test, the WizardMath model proposed in this paper is currently in the top five, slightly better than some closed-source models, and to a large extent surpassed all open-source models.
:::
::: block-1


Comparison of pass@1 results on GSM8k and MATH. To ensure a fair and consistent evaluation, this paper reports the scores of all models under the greedy decoding and CoT settings, and reports the improvement between WizardMath and baseline models with similar parameter sizes. It can be found that: WizardMath uses a larger B number, and the effect is significantly improved. The accuracy of the WizardMath-70B model is comparable to some SOTA closed-source LLMs.
:::
sample display
The figure below shows the different Response results of WizardMath models at different parameter levels for the same Input:
sample 1



sample 2


