Reprint public number | Expertise

Knowledge plays a vital role in artificial intelligence. Recently, the widespread success of pretrained language models (PLMs) has drawn significant attention to how knowledge is acquired, maintained, updated, and used by language models . Despite the huge amount of related research, there is still a lack of a unified view of how knowledge circulates in language models throughout learning, tuning, and application, which may prevent us from further understanding the current progress or realizing the connection between existing limitations. . This paper re-examines PLM as a knowledge-based system by dividing the knowledge lifecycle in PLM into five key periods and investigating how knowledge is cycled as it is constructed, maintained, and used. In this paper, we systematically review existing research on various stages of the knowledge life cycle, summarize the main challenges and limitations currently faced, and discuss future development directions.
https://www.zhuanzhi.ai/paper/3eda52f060c0913316b9ae9c375835f5
Fundamentally, AI is the science of knowledge—how to represent knowledge and how to acquire and use it.
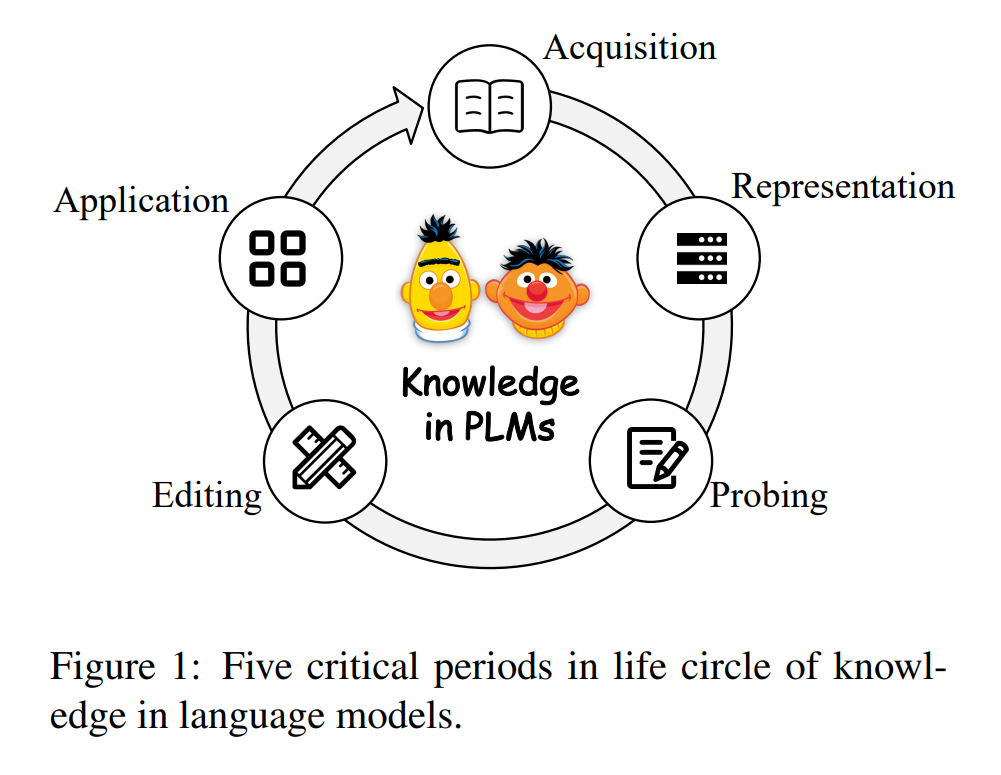
Knowledge is the key to high intelligence. How models acquire, store, understand and apply knowledge has always been an important research topic in the field of machine intelligence. In recent years, the pre-trained language model (PLM) has developed rapidly. With self-supervised pre-training on large-scale unlabeled corpora, PLM has shown strong generalization and transfer capabilities across different tasks/datasets/settings, thus achieving remarkable success in natural language processing (Devlin et al. , 2019; Liu et al., 2019c; Raffel et al., 2020; Radford et al., 2019b; Brown et al., 2020; Lewis et al., 2020a).
The success of pre-trained language models has drawn significant attention to the nature of their implicit knowledge. There have been many studies focusing on how pre-trained language models acquire, maintain and use knowledge. Along these lines of thought, many new research directions have been explored. For example, knowledge injection works to infuse explicit structured knowledge into PLMs (Sun et al., 2019; Zhang et al., 2019; Sachan et al., 2021). Knowledge detection aims to assess the type and amount of knowledge stored in the parameters of PLMs (Petroni et al., 2019; Lin et al., 2019; Hewitt and Manning, 2019). Knowledge editing, on the other hand, focuses on revising incorrect or undesirable knowledge acquired by PLMs (Zhu et al., 2020; De Cao et al., 2021; Mitchell et al., 2021).
Despite the abundance of related research, current research mainly focuses on a specific stage of the knowledge process in PLMs, thus lacking a unified view of how knowledge circulates throughout the model learning, tuning, and application stages. This lack of comprehensive research makes it difficult for us to better understand the connection between different knowledge-based tasks, find the correlation between different periods in the knowledge life cycle in PLMs, and make it difficult to use missing links and tasks to study knowledge in PLMs, it is also difficult to explore the deficiencies and limitations of existing research. For example, while many studies have attempted to evaluate knowledge in language models that have been pretrained, few studies have devoted to investigating why PLMs can learn from plain text without any knowledge supervision, and how PLMs Represent or store this knowledge. Meanwhile, many researchers have attempted to explicitly inject various structural knowledge into PLMs, but few studies have proposed to help PLMs better acquire specific types of knowledge from plain text by mining the underlying knowledge acquisition mechanism. Therefore, related research may over-focus on several directions without comprehensively understanding, maintaining, and controlling the knowledge in PLMs, thereby limiting improvement and further application.
This paper systematically reviews knowledge-related research in pre-trained language models from a knowledge engineering perspective. Inspired by research in cognitive science (Zimbardo and Ruch, 1975; and knowledge engineering (Studer et al., 1998; Schreiber et al., 2000), we treat pretrained language models as knowledge-based systems and study the The life cycle of how to obtain, maintain and use the pre-training model (Studer et al., 1998; Schreiber et al., 2000). Specifically, we divide the knowledge life cycle in the pre-training language model into the following five key period, as shown in Figure 1:
-
Knowledge acquisition refers to the process of language model learning various knowledge from text or other knowledge sources.
Knowledge representation studies the intrinsic mechanisms of how different types of knowledge are transformed, encoded and distributed in PLM parameters.
Knowledge probing , which aims to assess the current situation where PLM contains different types of knowledge.
Knowledge Editing , attempts to edit or delete the knowledge contained in the language model.
Knowledge application , which tries to extract or utilize knowledge from pre-trained language models for practical application.
For each period, we review existing research, summarize major challenges and limitations, and discuss future directions. Based on a unified perspective, we are able to understand and exploit the strong connections between different time periods, rather than treating them as independent tasks. For example, understanding the knowledge representation mechanism of PLMs helps researchers design better knowledge acquisition goals and knowledge editing strategies. Proposing reliable knowledge detection methods can help us find suitable applications of PLM and gain insight into its limitations, thereby promoting improvement. Through the review, comprehensively summarize the progress, challenges and limitations of current research, help researchers better understand the whole field from a new perspective, and explain how to better standardize, represent and apply language models in the future from a unified perspective direction of knowledge.
Our contributions are summarized as follows:
It is suggested to revisit the pretrained language model as a knowledge-based system and divide the knowledge life cycle in PLM into five key periods.
For each period, the existing research is reviewed and the main challenges and shortcomings of each direction are summarized.
Based on this review, the limitations of the current research are discussed and potential future directions are revealed.
overview
In this section, we present the overall structure of this review, describe in detail the taxonomy shown in Figure 2, and discuss themes for each key period.
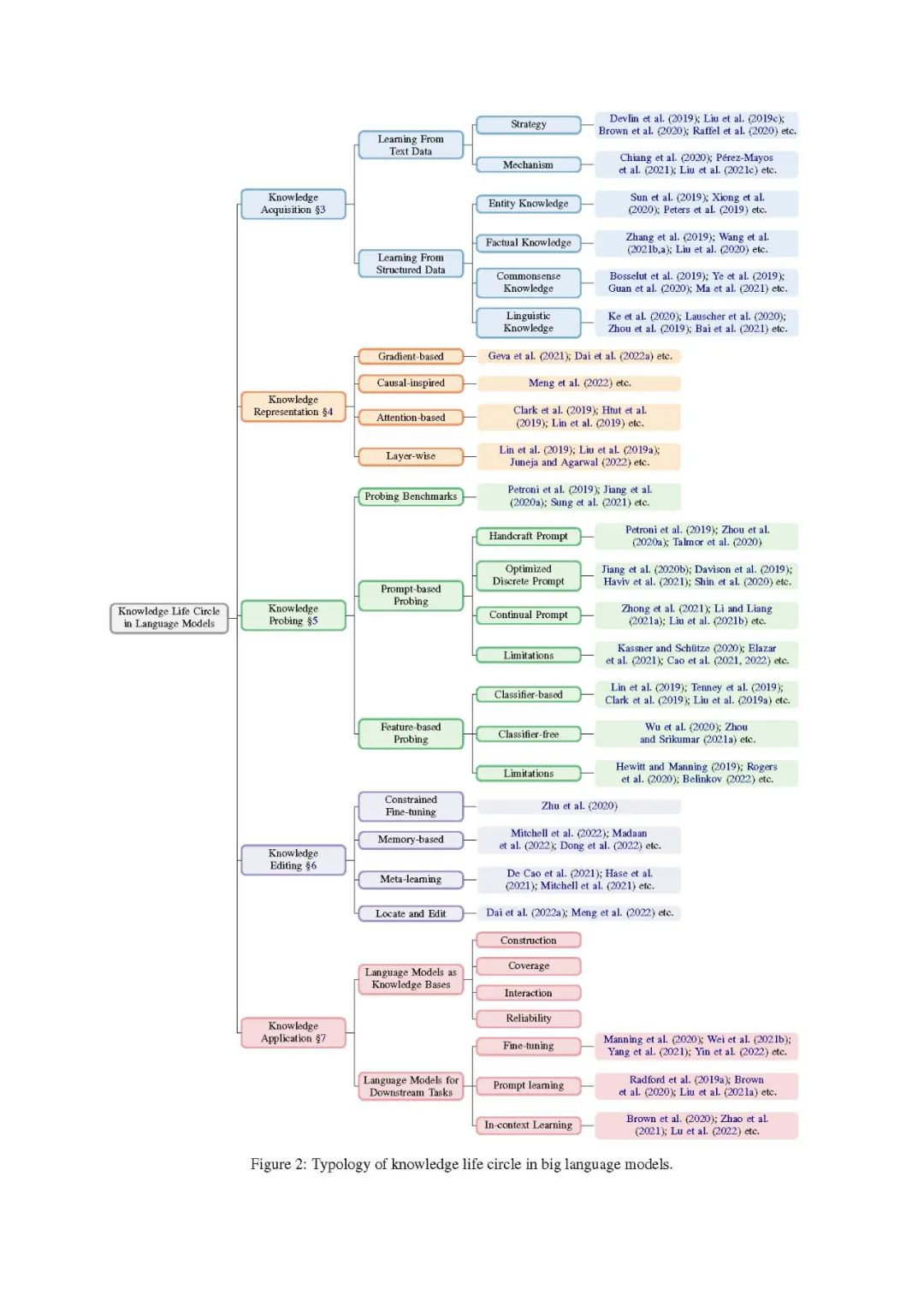
Knowledge acquisition is the knowledge learning process of language model. Currently, there are two main sources of knowledge acquisition: plain text data and structured data. To acquire knowledge from text data, language models are usually learned self-supervisedly on large-scale text corpora (Devlin et al., 2019; Liu et al., 2019c; Brown et al., 2020; Raffel et al., 2020). This review will focus on the methods and mechanisms of how pretrained language models acquire knowledge from plain text (Chiang et al., 2020; Pérez-Mayos et al., 2021; Liu et al., 2021c). To acquire knowledge from structured data, current research mainly focuses on infusing knowledge from different types of structured data. The main categories of structured data contain entity knowledge (Sun et al., 2019; Xiong et al., 2020; Peters et al., 2019), factual knowledge (Zhang et al., 2019; Wang Zhiqiang, Yang Zhiqiang, Yang Zhiqiang; Liu et al., 2020), Common sense knowledge (Bosselut et al., 2019; Ye et al., 2019; Guan et al., 2020; Ma et al., 2021) and language knowledge (Ke et al., 2020; Lauscher et al., 2020; Zhou et al., 2019; Bai et al., 2021). We will discuss them in Section 3.
Knowledge representation aims to study how language models encode, store and represent knowledge in their dense parameters. Research on knowledge representation mechanisms will help to better understand and control knowledge in PLMs, and may also inspire researchers to better understand knowledge representation in the human brain. Currently, strategies for knowledge representation analysis in PLMs include gradient-based (Geva et al., 2021; Dai et al., 2022a), causal heuristics (Meng et al., 2022), attention-based (Clark et al., 2019; Htut et al. et al., 2019; Lin et al., 2019) and hierarchical (Lin et al., 2019; Liu et al., 2019a; Juneja and Agarwal, 2022) approaches. We will discuss them in Section 4.
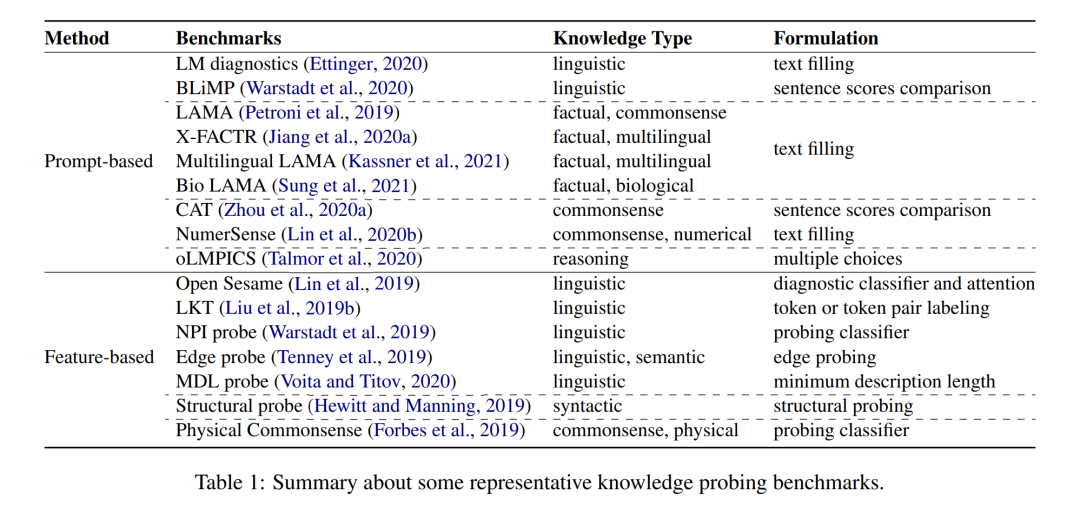
The purpose of knowledge probing is to assess the impact of current PLMs on specific types of knowledge. Currently, there are two main strategies for probing knowledge in PLMs: 1) Hint-based probing, which usually constructs hints indicative of knowledge and then uses these natural language expressions to query PLMs (Petroni et al., 2019; Jiang et al., 2020a ; Sung et al., 2021; Forbes et al., 2019; Zhou et al., 2020a). For example, query PLMs with “The capital of France is .” to evaluate whether the corresponding knowledge is stored in PLMs. Meanwhile, to improve the performance of plms, a series of studies have been devoted to optimizing two discrete cues (Jiang et al., 2020b; Davison et al., 2019; Haviv et al., 2021; Shin et al., 2020) and a continuous space (Zhong et al., 2020) et al., 2021; Li and Liang, 2021a; Liu et al., 2021b). Despite the widespread application of hint-based exploration, many studies also pointed out that there are still some open issues such as inconsistency (Elazar et al., 2021; Kassner and Schütze, 2020; Jang et al., 2022; Cao et al., 2022) , inaccurate (Perner et al., 2020; Zhong et al., 2021; Cao et al., 2021) and unreliable (Cao et al., 2021; Li et al., 2022a), and the quantitative results based on cue detection question. 2) Feature-based detection, which usually freezes the parameters of the original PLM and evaluates the performance of the PLM on the detection task based on its internal representation or attention weights. We categorize existing feature-based detection research into classifier-based detection (Lin et al., 2019; Tenney et al., 2019; Clark et al., 2019; Liu et al., 2019a) and classifier-free detection (Wu et al. et al., 2020; Zhou and Srikumar, 2021a) depending on whether additional classifiers are introduced. Since most methods introduce additional parameters or training data, the main disadvantage of feature-based detection is whether the results should be attributed to the knowledge in the PLM or to the detection task learned through additional detection. We discuss them in Section 5.
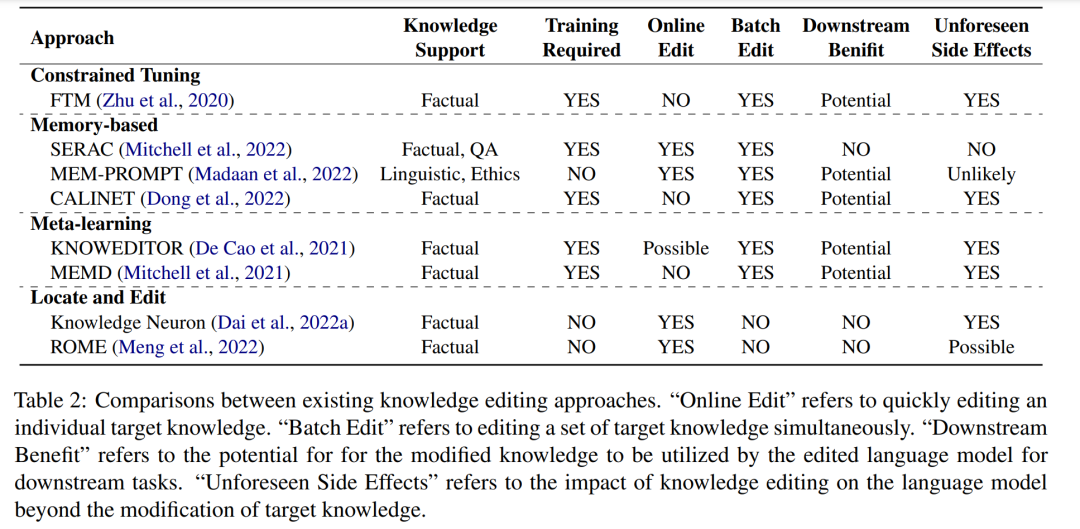
Knowledge editing aims to modify incorrect knowledge or delete bad information in the product life cycle. Due to the inevitable errors and knowledge updates learned by PLMs, reliable and effective knowledge editing methods are crucial for the sustainable application of PLMs. Current approaches include constrained fine-tuning (Zhu et al., 2020), memory-based (Mitchell et al., 2022; Madaan et al., 2022; Dong et al., 2022), meta-learning heuristics (De Cao et al., 2021; Hase et al. et al., 2021; Mitchell et al., 2021) and location-based methods (Dai et al., 2022a; Meng et al., 2022). We discuss them in Section 6.
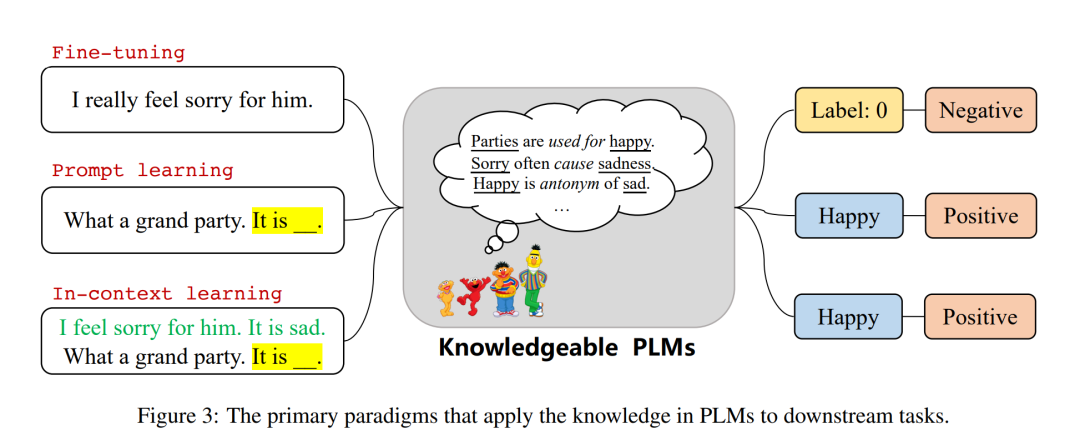
Knowledge application aims to extract or utilize specific knowledge from PLMs to benefit further applications. Currently, there are two main application paradigms for knowledge in PLMs: 1) Language Models as Knowledge Bases (LMs-as-KBs), which treat language models as dense knowledge bases that can be directly queried in natural language to obtain specific types of knowledge (Petroni et al., 2019; Heinzerling and Inui, 2021; Jiang et al., 2020b; Wang et al., 2020; Cao et al., 2021; Razniewski et al., 2021; AlKhamissi et al., 2022). A comprehensive comparison of structured knowledge bases and LMs-as-KBs (Razniewski et al., 2021) is carried out from the four aspects of construction, coverage, interactivity and reliability; 2) the language model for downstream tasks, directly in the Downstream NLP tasks using plms that incorporate specific types of knowledge (Manning et al., 2020; Wei et al., 2021b; Yang et al., 2021; Yin et al., 2022), learn quickly (Radford et al., 2019a; Brown et al., 2020 ; Liu et al., 2021a) and contextual learning (Brown et al., 2020; Zhao et al., 2021; Lu et al., 2022). We discuss them in Section 7.
Special knowledge, professional and credible artificial intelligence knowledge distribution , make cognitive collaboration faster and better! Welcome to register and log in Zhuanzhi www.zhuanzhi.ai to get 100,000 +AI (AI and military, medicine, public security, etc.) themed dry goods knowledge materials!
OpenKG
OpenKG (Chinese Open Knowledge Graph) aims to promote the openness, interconnection and crowdsourcing of knowledge graph data with Chinese as the core, and promote the open source and open source of knowledge graph algorithms, tools and platforms.

Click to read the original text and enter the OpenKG website.