对于环境变量的搭建
在centos7环境下配置环境变量是必不可少的,所以直接上干货:
1.删除原有的jdk
通过java -version查看当前的jdk版本,之后可以通过如下命令删除系统自带的jdk
yum -y remove java*
2.安装新的jdk
下载最新的jdk,下载完成后在/home/node1/下载 (本人的目录如下)中找到jdk,通过如下命令移动到目标文件夹下(本人是/usr/local)
mv /home/node1/桌面/zxvf jdk-8u191-linux-x64 (2).tar.gz /usr/local
tar zxvf jdk-8u191-linux-x64 (2).tar.gz
mv jdk1.8.191 jdk
完成之后配置环境变量:
gedit /etc/profile
#JAVA Environment
JAVA_HOME=/usr/local/jdk
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
运行如下指令便可生效:
souce /etc/profile
通过java -version便可查到jdk版本
java -version
如果是这样就算是配置正确。

3.安装zookeeper
下载zookeeper安装包,执行如下造作指令
mv /home/node1/下载 /usr/local
tar zxvf zookeeper-3.4.13 (1).tar.gz
配置环境变量(特别说明:对于每一个软件的安装,若是需要配置环境变量,必须指明配置名称)
配置如下:
#ZOOKEEPER
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
~~~java
再运行:
~~~java
source /etc/profile/
便可生效。
接着就是zookeeper内部文件的配置,对于所配置文件的位置必须说明一下,本人参考好多经验,但大家都不说明位置,对于准备入门的小白来说,是个极大的考验,本次的配置位置是在zookeeper下的conf目录下
(1)复制zoo_sample.cfg并命名为zoo.cfg
cp zoo_sample.cfg zoo.cfg
接着配置zoo.cfg文件
gedit zoo.cfg
接着将必要的文件修改
(1)将dir=/tmp/zookeeper修改为(记住这个位置):
dataDir=/usr/local/zookeeper/zkdata
(2)添加对应关系(最后一行node1等为主机名,也可以写相对应的ip):
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
到此文件配置完成,接着就是在/usr/local/zookeeper/的目录下创建zkdata目录:
mkdir zkdata
cd zkdata
vi myid
按i进入myid文件,输入1(node1为1,node2为2,node3为3)即可。
tip:
在启动zookeeper前要关闭防火墙,接着启动zookeeper服务器
systemctl stop firewalld.service
zkServer.sh start
jps
会看到:
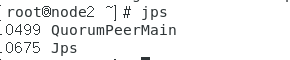
成功。接着通过命令:
scp -r /usr/local/zookeeper node2:/usr/local/
scp -r /usr/local/zookeeper node3:/usr/local/
接着就是修改/usr/local/zookeeper/zkdata/myid,为2(node2),3(node3).
如果传输失败,那就是ssh免密登录没有配置。具体配置如下:
小插曲
ssh-keygen -t rsa
只需要一路按回车即可。

如上图找到对应的公钥和私钥(/root/.ssh/)的位置,接着输入如下命令:
cp id_rsa.pub authorized_keys
chmod 600authorized_keys
ssh localhost

至此本机的ssh免密登录完成,若是和其他机免密登录,还需要将本机的id_rsa.pub文件内容复制到authorized_keys文件中(过程书写太麻烦,基本就是用scp 传输完成后,打开id_rsa.pub文件复制到authorized_keys中即可)
4.安装hadoop
下载想要的hadoop版本
(1)移动安装包并配置环境变量
mv /home/node1/下载/hadoop-3.0.1.tar.gz /usr/local/
tar zxvf hadoop-3.0.1.tar.gz
mv hadoop-3.0.1 hadoop
配置环境变量
gedit /etc/profile
#HADOOP Environment
HADOOP_HOME=/usr/local/hadoop
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_HOME
export PATH
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_ROOT_LOGGER=INFO,console
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
source /etc/profile
(2)文件配置
重点来了!重点来了!重点来了!!!
重要的事情说三遍,如果配置错了可别怪我没说。1.关于配置文件的目录全在/usr/local/hadoop/etc/hadoop/ 下
2.创建文件保存所需要的目录。
首先在hadoop-env.sh、mapred-env.sh、yarn-env.sh文件中指定JDK的路径
export JAVA_HOME=/usr/local/jdk
配置core-site.xml 文件
<configuration>
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/data/hdfs/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
接着配置hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/data/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/data/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node1:50070</value>
<description>
The address and the base port where the dfs namenode web ui will listen on.
If the port is 0 then the server will start on a free port.
</description>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/usr/local/data/hdfs/checkpoint</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:/usr/local/data/hdfs/edits</value>
</property>
</configuration>
接着配置yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandle</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tarcker.address</name>
<value>node1:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node1:8040</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>node1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>node1:8088</value>
</property>
最后就是配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tarcker</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
</configuration>
修改workers文件,删除localhost,并换成
node2
node3
mkdir /usr/local/data/hdfs/tmp
mkdir /usr/local/data/hdfs/name
mkdir /usr/local/data/hdfs/data
mkdir /usr/local/data/hdfs/checkpoint
mkdir /usr/local/data/hdfs/edits
到此完成,只需要做如下操作
scp -r /usr/local/hadoop node2:/usr/local/
scp -r /usr/local/hadoop node3:/usr/local/
hadoop安装完成
格式化一下Namonode
hdfs namenode –format
启动hadoop有一个粗暴的方法
cd /usr/local/hadoop/sbin
./start-all.sh
首先会看到

测试方式:jps会看到:
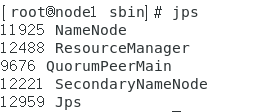
node2上jps一下会看到:
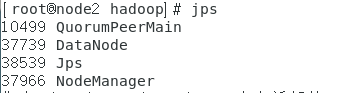
node3相同
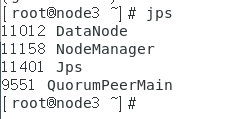
接着在网页上测试:
http://node1:50070

http://node1:8088

http://node2:8042

配置完成。
4安装hbase
下载hbase,并移动到目标文件夹
mv /home/node1/下载hbase-1.3.3-bin.tar.gz /usr/local
tar zxvf hbase-1.3.3-bin.tar.gz
mv hbase-1.3.3 hbase
配置环境变量
#HBASE
export HBASE_HOME=/usr/local/hbase
export PATH=$HBASE_HOME/bin:$PATH
export HBASE_MANAGES_ZK=false
配置conf目录下的hbase-site.xml文件
<configuration>
<configuration>
<!--HBase数据目录位置-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://node1:9000/hbase</value>
</property>
<!--启用分布式集群-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--默认HMaster HTTP访问端口-->
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<!--默认HRegionServer HTTP访问端口-->
<property>
<name>hbase.regionserver.info.port</name>
<value>16030</value>
</property>
<!--不使用默认内置的,配置独立的ZK集群地址-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node2,node3</value>
</property>
</configuration>
</configuration>

将regionservers文件下的内容改为
node2
node3
修改hbase-env.sh文件
添加如下内容:
export JAVA_HOME=/usr/local/jdk/
export HBASE_CLASSPATH=/usr/local/hadoop/etc/hadoop
export TZ="Asia/Shanghai"
export HBASE_PID_DIR=/var/hadoop/pids
export HBASE_MANAGES_ZK=false
并将下面的内容注释掉,即找到后在最前面加#即可
#export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
#export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
source /etc/profile
完成
启动hbase
cd /usr/local/hbase/bin
./start-hbase.sh
jps后会看到:

http://node1:16010
会看到:

完成。