一、准备工作
第一步,先查看一下python3是否有requests 和 BeautifulSoup4 这两个模块
1) 在命令行中输入python, 进入编辑模式
2) 输入下面指令:
import requests
from bs4 import BeautifulSoup
如果报错了, 请在有网络的环境在控制台下使用下面的命令
pip install requests
pip install BeautifulSoup4第二步,选定好您要准备爬去的小说网站:
每个网站都有不同的代码书写风格,当风格没确定好时,就有可能出现代码错误的情况,在这里我选择的是笔趣阁小说网站: https://www.biquge5200.com/
ps: 不是打广告不是打广告不是打广告!
之后,选择一本想要观看的小说(在笔趣阁里没有提供下载服务), 在这个教程里面我要下载的是 耳根的小说–一念永恒 (有喜欢玄幻小说的朋友们,我强烈推荐大家看这本书,但是请支持正版,毕竟是作者用心写的小说)
二、获取第一章内容
对html有一定了解的朋友们应该都知道, html是一个超文本标记语言, 里面存了大量标签, 打开网页,进入开发者模式, 可以看到下面的内容:
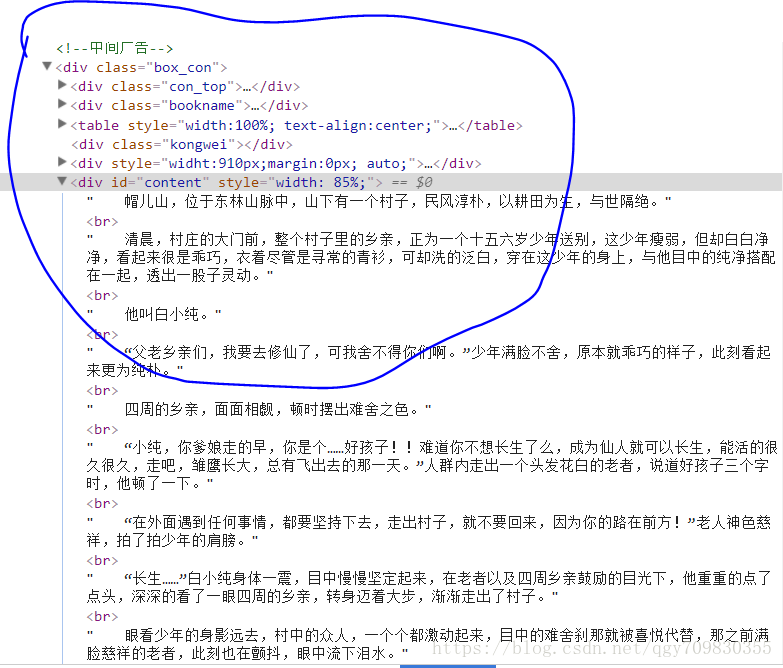
在图片中, 我们可以看到很多
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
def main():
target = 'https://www.biquge5200.com/38_38857/15054739.html'
req = requests.get(url=target)
bf = BeautifulSoup(req.text, 'html5lib')
content = bf.find_all('div', id='content')
print(content)
if __name__ == '__main__':
main()
注意:使用BeautifulSoup 解析文本的时候, 需要指定解析的方式,在这里,我们是以html5的方式来解析文本, 在第一次使用的时候,需要先安装html5lib库
运行结果:
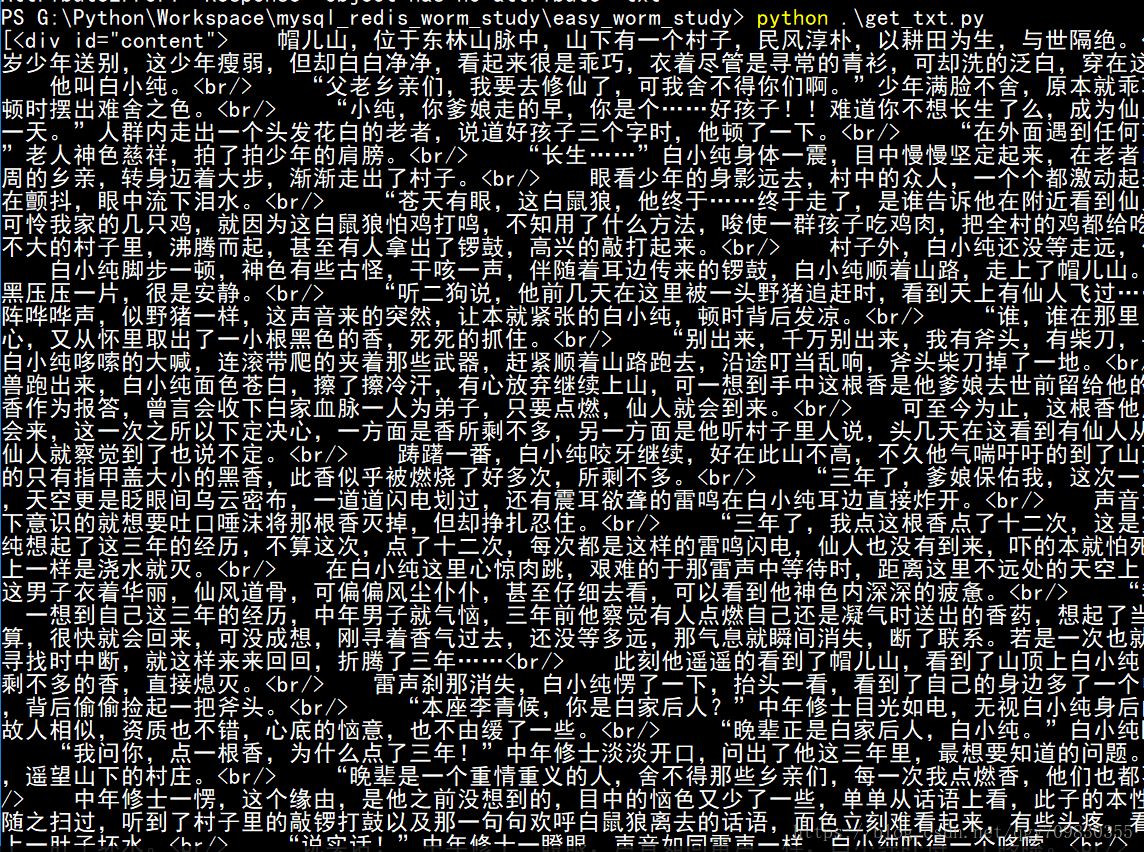
不过通过运行结果可以看出,光通过上面的代码,会用很多html标签, 需要,通过content[0].text 来获取文字, 并且将空格多的地方,用换行符替换掉,使得排版更加简洁, 当然,在有些网站,空格部分甚至可能使用转义字符”& n b s p ;”, 这个就需要通过正则表达式来查找转义字符并替换
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
def main():
target = 'https://www.biquge5200.com/38_38857/15054739.html'
req = requests.get(url=target)
bf = BeautifulSoup(req.text, 'html5lib')
content = bf.find_all('div', id='content')
final_content = content[0].text.replace(' ', '\n\n ')
print(final_content)
if __name__ == '__main__':
main()
注意:此处为什么会使用content[0]呢? 因为使用find_all方法查到的数据是以列表的形式呈现的,其实,在这个地方,因div定义的id属性,我们完全可以换成find方法来进行定位查找, 当然,如果您选择的网站存储正文的div(或者其他标签)他的属性是class的时候,请务必使用find_all方法来查找!
运行结果:
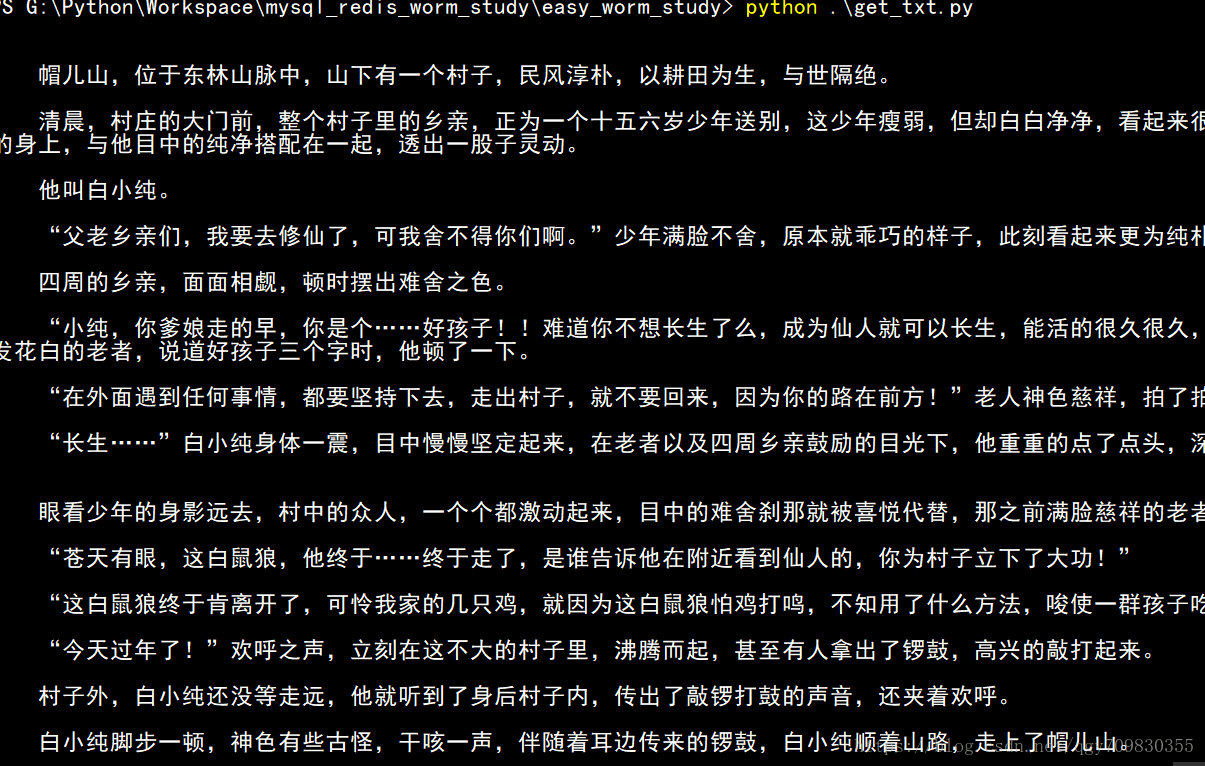
二、获取每一章节的url
什么是url? 我的解释就是每个网站网址,比如百度首页的url 就是 www.baidu.com
好了,下面进入正题,首先我们先查看一下小说目录页面的源码:
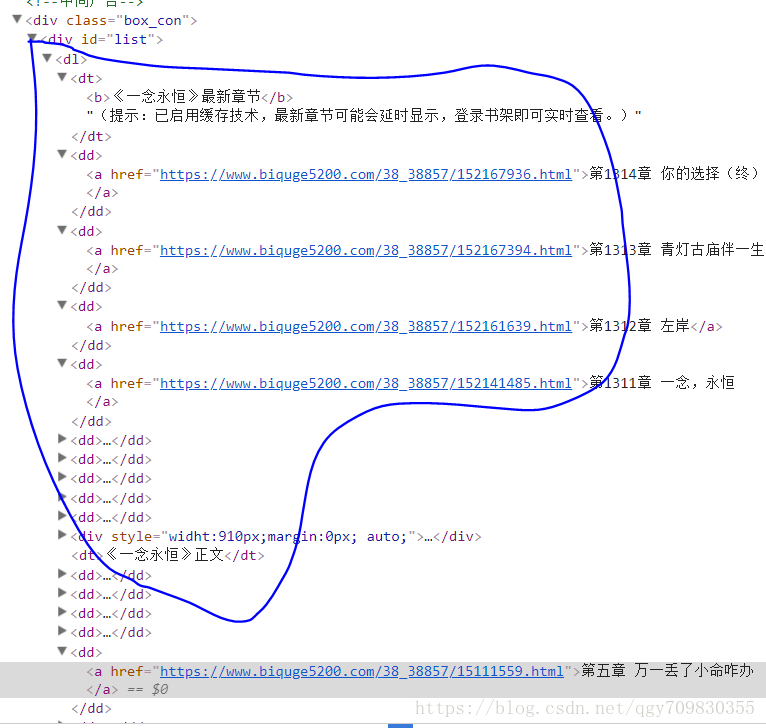
这里有一长串的
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
def main():
target = 'https://www.biquge5200.com/38_38857/'
req = requests.get(url=target)
bf = BeautifulSoup(req.text, 'html5lib')
content = bf.find_all('div', id='list')
print(content)
if __name__ == '__main__':
main()
运行结果:
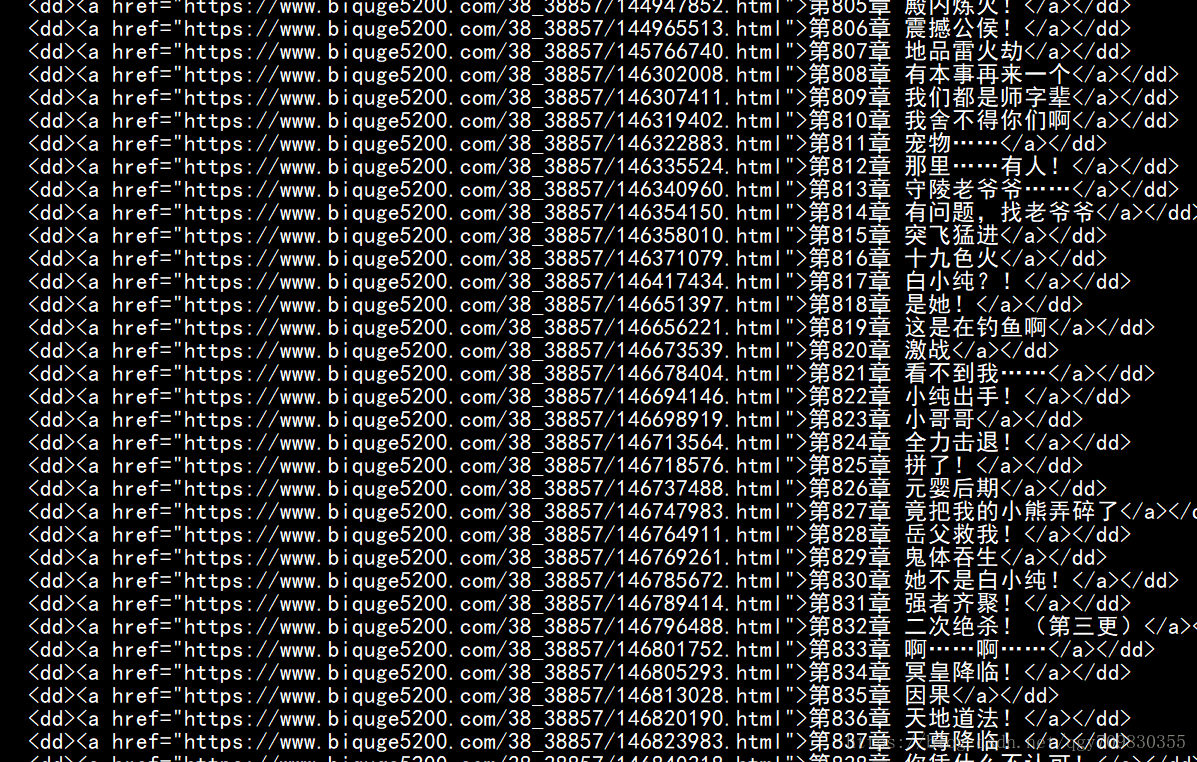
同样的也可以使用因为是id属性, 同样的也可以使用find 方法进行查找, 但是,很明显的,输出的结果肯定不是我们想要的结果
, 可以在前面基础下,在查找所有标签 , 再使用a.string 输出章节名字, 使用a.get(‘href’)获取每章的url
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
def main():
target = 'https://www.biquge5200.com/38_38857/'
req = requests.get(url=target)
bf = BeautifulSoup(req.text, 'html5lib')
content = bf.find_all('div', id='list')
bf_a = BeautifulSoup(str(content[0]), 'html5lib')
a = bf_a.find_all('a')
for each in a:
print(each.string, each.get('href'))
if __name__ == '__main__':
main()注意, 再转换的时候还是需要在使用BeautifulSoup进行解析, 这面有个坑,就是content 是一个列表, 如果直接使用content[0]的话,其类型是’bs4.element.Tag’, 所以必须强制转换成str类型
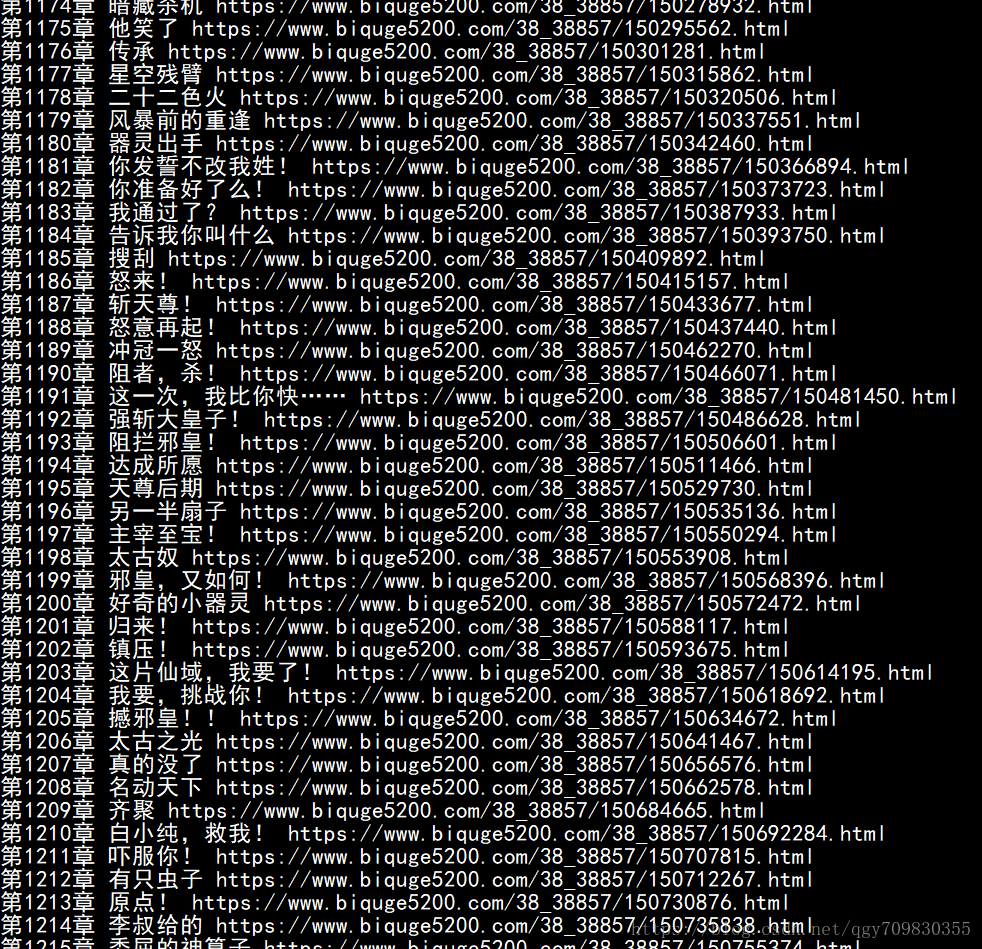
整合代码
定义一个下载器类,他有get_url, get_txt, write_txt 方法
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
import sys
class Downloader(object):
def __init__(self, target):
self._target = target
"""获取每一章的url"""
def get_url(self):
req = requests.get(url=self._target)
bf = BeautifulSoup(req.text, 'html5lib')
content_url = bf.find('div', id='list')
bf_a = BeautifulSoup(str(content_url), 'html5lib')
a = bf_a.find_all('a')
return a
"""获取每一章的内容"""
def get_txt(self, content_url, title):
req = requests.get(url=content_url)
bf = BeautifulSoup(req.text, 'html5lib')
text_content = bf.find('div', id='content')
content = text_content.text.replace(' ', '\n\n ').replace(' ', '\n\n ').replace('\n\n', '\n')
txt = title + '\n' + content
return txt
"""下载文件"""
def write_txt(self, filename, txt):
with open(filename, 'a', encoding='utf-8') as f:
f.write(txt)
def main():
target = sys.argv[1]
filename = sys.argv[2]
d = Downloader(target)
running = True
a = d.get_url()
while running:
for i in range(9, a):
txt = d.get_txt(a[i].get('href'), a[i].string)
d.write_txt(filename, txt)
print('%s 下载完成!' % each.string)
if __name__ == '__main__':
main()注意:上面的代码由于使用的是单线程,所以下载速度十分缓慢,而且在写入文件的时候有个坑,是, ‘w’, 是覆盖写入, ‘a’是追加写入, 如果您使用了’w’来写入的话,恭喜您,漫长的等待最后你只能下载到最后一章, 而且从下面的截图可以看到,前面有9章是最新章节,我们不需要,所以应该从第10章开始下载, 即a[9]
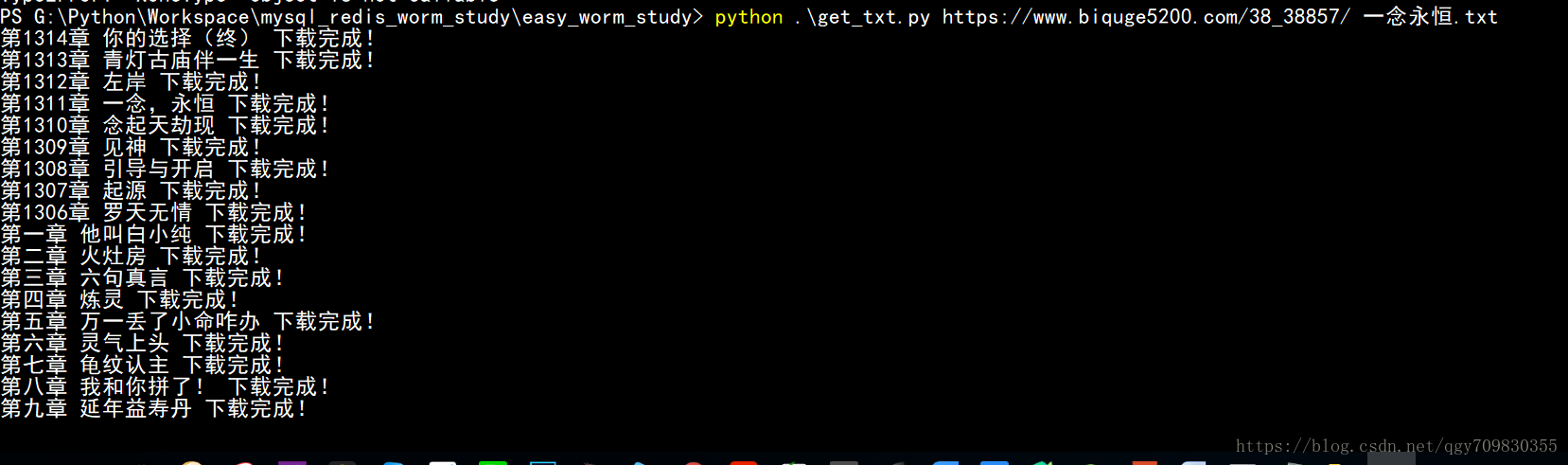
多线程速度优化
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
from threading import Thread
import time
import sys
class Downloader(object):
def __init__(self, target):
self._url = target
"""获取每一章节的url"""
def get_url(self):
req = requests.get(url=self._url)
bf = BeautifulSoup(req.text, 'html5lib')
div = bf.find_all('div', id='list')
a_bf = BeautifulSoup(str(div[0]), 'html5lib')
a = a_bf.find_all('a')
return a
"""获取每一章正文内容"""
def get_content(self, content_url, title):
req = requests.get(url=content_url)
bf = BeautifulSoup(req.text, 'html5lib')
text_content = bf.find_all('div', id='content')
if len(text_content) > 0:
content = text_content[0].text.replace(' ',
'\n\n ').replace(' ',
'\n\n ').replace('\n\n', '\n')
else:
print('错误')
txt = title + '\n' + content
return txt
"""写入文件"""
def write_txt(self, filename, txt):
with open(filename, 'a', encoding='utf-8') as f:
f.write(txt)
def main():
class WriteThread(Thread):
def __init__(self, first_num, last_num, thread_num, txt=''):
super().__init__()
self._first_num = first_num
self._last_num = last_num
self._txt = txt
self._thread_num = thread_num
def run(self):
nonlocal txt_list, is_end_list
print('线程%d启动' % self._thread_num)
for i in range(9+self._first_num, self._last_num):
title = a[i].string
try:
content_url = a[i].get('href')
self._txt += d.get_content(content_url, title)
except AttributeError:
print('该线程出现异常!请检查 %s--%s 网页是否有问题' % (a[9+self._first_num].string, a[self._last_num-1].string))
print('%s--%s完成' % (a[9+self._first_num].string, a[self._last_num-1].string))
is_end_list[self._thread_num-1] = True
txt_list[self._thread_num-1] = self._txt
def all_end(thread_num):
nonlocal is_end_list
for i in range(thread_num):
if is_end_list[i] == 'False':
return False
return True
def final_filename(filename):
if filename.rfind('.') == -1:
filename += '.txt'
return filename
target = sys.argv[1]
d = Downloader(target)
a = d.get_url()
running = True
first_num = 0
last_num = 59
title = sys.argv[2]
filename = final_filename(title)
print(filename)
thread_num = 0
txt_list = ['' for _ in range(200)]
is_end_list = ['False' for _ in range(200)]
start_time = time.time()
while running:
thread_num += 1
txt = WriteThread(first_num, last_num, thread_num)
txt.start()
if len(a) - last_num >= 50:
first_num = last_num - 9
last_num += 50
elif 0 < len(a) - last_num < 50:
first_num = last_num - 9
last_num = len(a)
else:
running = False
while True:
if all_end(thread_num):
for txt in txt_list:
if txt != '':
d.write_txt(filename, txt)
end_time = time.time()
print('耗时%ds' % (end_time-start_time))
return
if __name__ == '__main__':
main()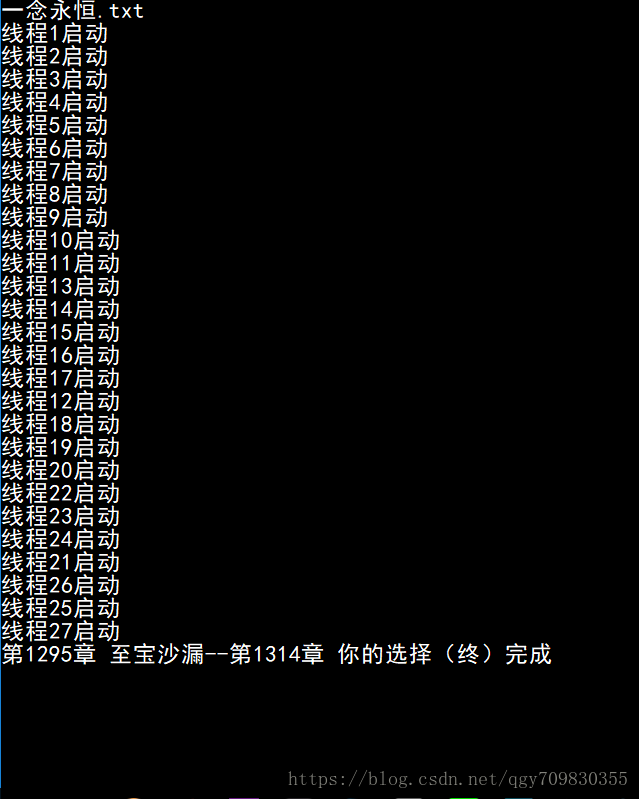
每50章起一个线程, 通过一个列表来顺序存储内容, 大大缩短了下载时间, 1000多章的小说,30~40秒便可以下载完毕