1.通过画学习曲线来观察。学习曲线:横坐标是不同数量的训练样本,纵坐标是dev set的error。随着训练样本的增加,error降低。一般来说,我们有一个期望误差率,希望网络能够达到。比如:人类的误差率;直觉上任务应该达到的误差率;长期目标需要达到的误差率。
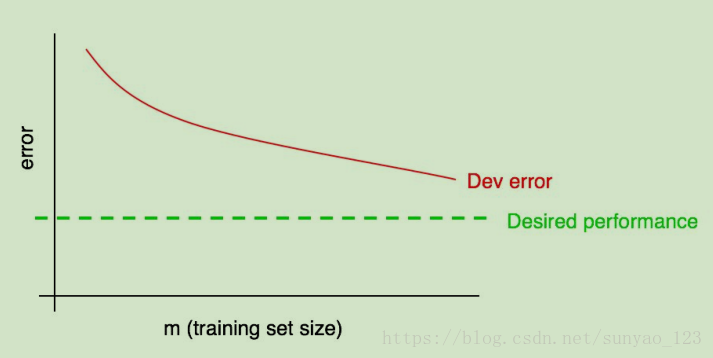
通过观察上述曲线,可以推断还需要多少训练样本才能达到期望误差率。但是如果误差曲线最后是平的:
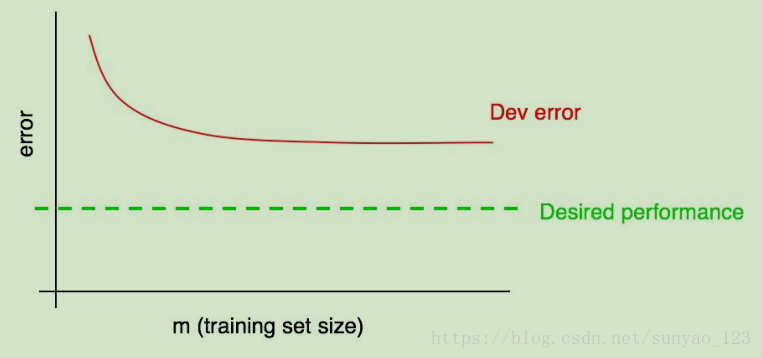
那么,通过增加训练数据是不能够达到我们的要求的。通过这个曲线,我们就不需要去花费精力收集数据。
如果仅仅看dev集误差率,很难推断使用更多的数据,这个误差率最终达到什么程度,这个时候,我们就可以使用训练误差。
2.我们的测试误差随着训练数据的增多而下降,但是训练误差会随着训练数据的增加而增加。
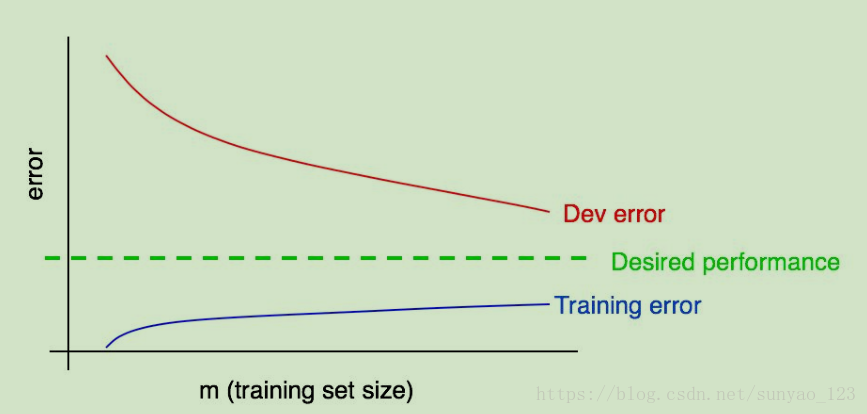
虽然训练误差在增长,但是小于测试误差。
上边说,如果测试误差随着训练数据的增加基本不在下降,那么单单通过测试误差不能确定增加训练数据是否使得测试误差达到什么程度。因为可能是测试集的问题(比如测试集较小,这个曲线噪声较大)。
如果图是这样的:
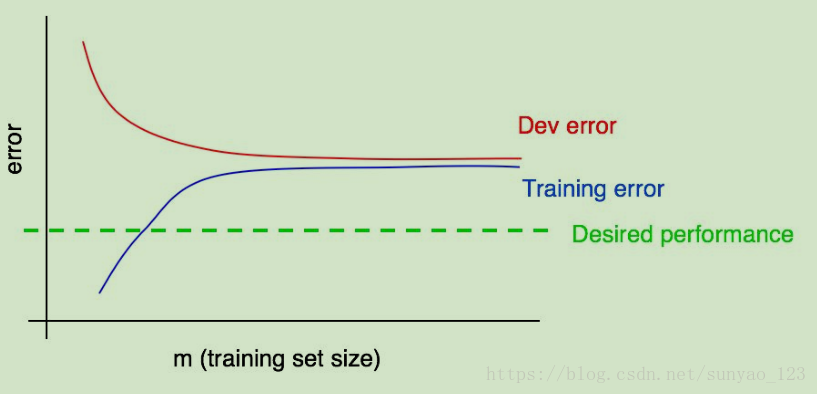
我们就可以自信的说,增加训练数据永远不能降低测试误差,因为训练误差高于期望误差,网络已经是高bias。由于测试误差和训练误差接近,variance较低。
当然这些分析有一个前提是:一般来说,训练误差小于测试误差。
所以最好画出完整的(使用所有的训练数据)训练,测试误差曲线。