第8章主要内容:
1.尽量选单个数字来优化你的模型。
2.如果想要同时考虑几个指标,可以用一种标准方式将它们组合成一个数字(例如平均)。
3.提到了recall、precision、F1 score。
8 Establish a single-number evaluation metric for your team to optimize
分类准确性可以用一个数字来衡量:你在开发集(或测试集)上运行你的分类器,会返回一个数字,这个数字表示正确分类的比例。通过这个指标,如果分类器A获得了97%的准确率,B获得了90%的准确率,那么我们会判别A更好。
相比之下,precision(查准率、准确率)和recall(查全率、召回率)
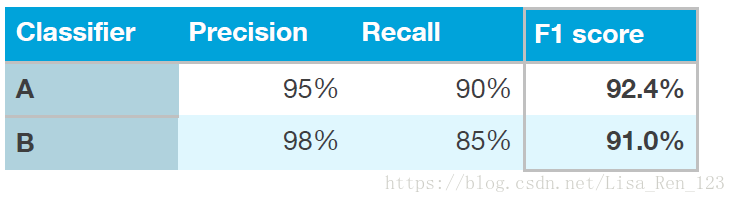
并不是单数评估指标:它提供了两个数字来评估你的分类器。有多个数字的评估指标会使比较算法时变得困难。假设你的算法表现如下:

没有哪个分类器是很明显好于另一个的,所以这不能立刻决定选哪一个。

在开发过程中,你的团队会尝试各种算法结构、模型参数、特征选择等等。有一个单数字评估标准例如准确性,能让你依靠这个指标对你的模型排序,然后快速决定哪个是最好的。
如果你真的同时在意Precision和Recall,我建议使用一种标准方式将它们组合成一个数字。例如,可以取precision和recall的平均,这样就成了一个数字了。或者,你可以计算“F1分数”,这是一种计算平均值的改进方式,并且比简单的取平均要好用
。
使用单数字评估指标能让你在很多分类器里面快速做选择。它能对他们有一个明确的偏好排名,因此明确了进展的方向。
最后一个例子,假设你要在四个主要市场中分别跟踪你的猫分类器准确性:(i)美国,(ii)中国,(iii)印度,(iv)其他。你会得到4个数字。通过取这4个数字的平均或者加权平均,最终你将有一个评估数字。取平均或者加权平均是将多个指标组合成一个的最常见的方式。
猫分类器的查准率是开发集(测试集)选出来的猫中有多少是真正的猫.( )。查全率是真正的猫有多少被选出来了.( )。经常在高查准率和高查全率之间中和。
如果你想了解更多关于F1分数的内容,查看https://en.wikipedia.org/wiki/F1_score。它是查准率和查全率的“调和平均值”。计算公式为