持续更新
已更新17章
第一章:为什么选择机器学习策略
如果你的团队要使用神经网络做一个猫图片识别系统。
如果你能够在以上可能的方向中做出正确的选择,那么你将建立起一个领先的猫咪图片识别平台,并带领你的公司获得成功。但如果你选择了一个糟糕的方向,则可能因此浪费掉几个月甚至数年的开发时间。
第二章:如何使用本书帮助你的团队
完成本书的阅读后,你将对于“如何在机器学习项目中设定一个技术方向”有着深层次的了解。优先级的稍加改变会对团队的生产力产生巨大的影响。
第三章:先修知识与符号标记
简要介绍了监督学习。
第四章:规模驱动机器学习发展
有两个主要因素推动着近期机器学习的发展:
数据可用性(data availability):海量数据对于学习算法是很有用的。
计算规模(computational scale):在近些年前,我们才开始能够使用现有的海量数据集来训练规模足够大的神经网络。
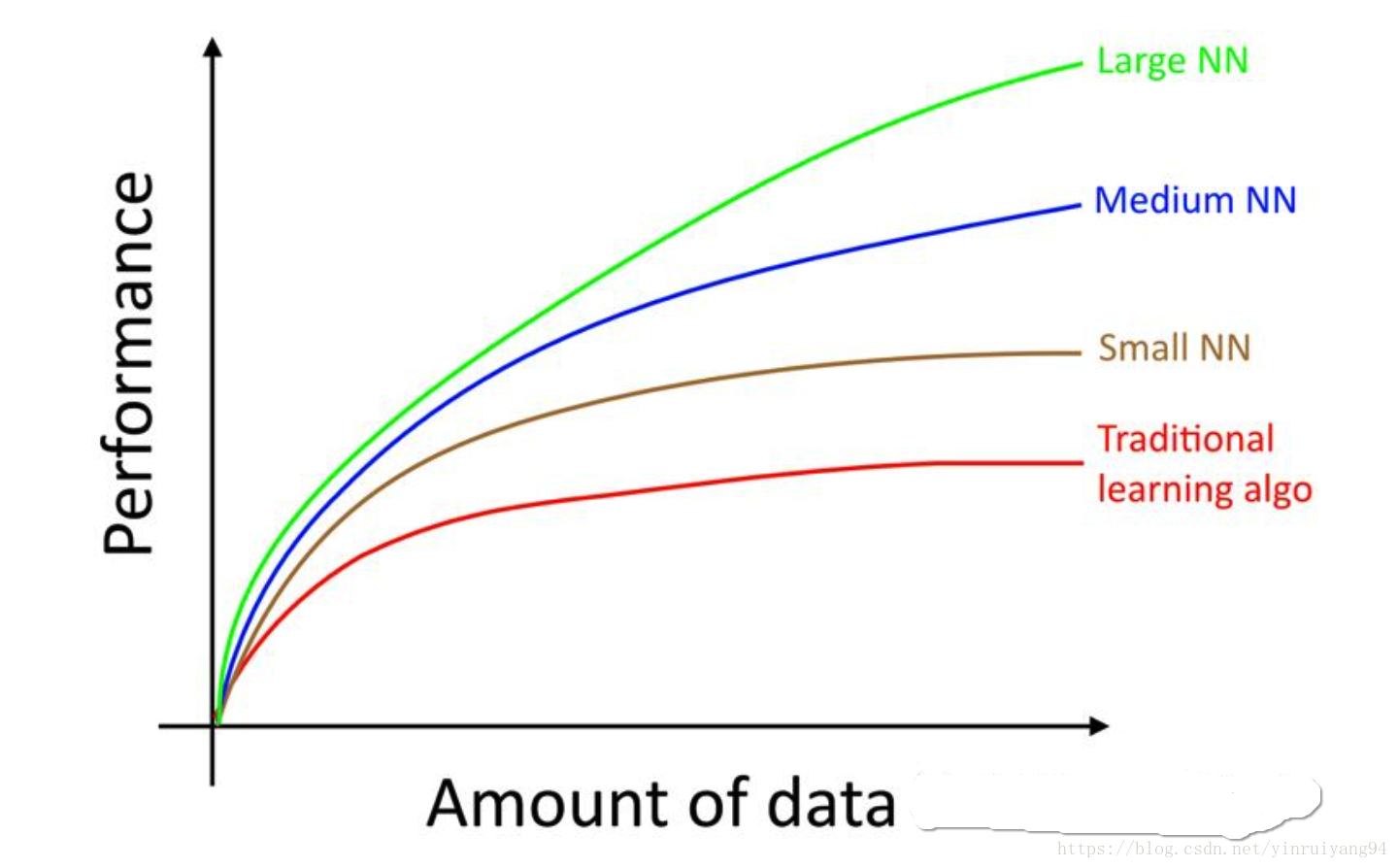
在算法训练时,许多其它的细节也同等重要,例如神经网络的架构。但目前来说,提升算法性能的更加可靠的方法仍然是训练更大的网络以及获取更多的数据。
第五章:开发集和测试集的概念
在大数据时代来临前,机器学习中的普遍做法是使用 70% / 30% 的比例来随机划分出训练集和测试集。这种做法的确可行,但在越来越多的实际应用中,训练数据集的分布与人们最终所关心的分布情况往往不同,此时执意要采取这样的划分则是一个坏主意。(例如猫图片识别系统中,训练集都是网络上找到的清晰图片,而测试集是用户上传的手机拍摄的模糊图片。因此训练好的系统却不能识别用户上传的图片。)
我们通常认为:
训练集(training set)用于运行你的学习算法。
开发集(development set)用于调整参数,选择特征,以及对学习算法作出其它决定。有时也称为留出交叉验证集(hold-out cross validation set)。
测试集(test set)用于评估算法的性能,但不会据此决定使用什么学习算法或参数。
所以对于上边提到的情况你应当这样处理:
合理地设置开发集和测试集,使之近似模拟可能的实际数据情况,并处理得到一个好的结果。也就是说你的测试集不应该仅是简单地将可用的数据划分出 30%,尤其是将来获取的数据(移动端图片)在性质上可能会与训练集(网站图片)不同时。
第六章:开发集和测试集应该服从同一分布
一旦定义了开发集和测试集,你的团队将专注于提高开发集的性能表现,这就要求开发集能够体现任务的核心:使算法在所有情况都表现优异,而不仅仅是其中的部分情况。
开发集和测试集的分布不同还将导致第二个问题:你的团队开发的系统可能在开发集上表现良好,但在测试集上却表现不佳。
举个例子,假设你的团队开发了一套能在开发集上运行性能良好,却在测试集上效果不佳的系统。如果开发集和测试集分布相同,那么你就会非常清楚地知道,是在开发集上过拟合了(overfit)。解决方案显然就是获得更多的开发集数据。
但是如果开发集和测试集来自不同的分布,解决方案就不那么明确了。
第七章:开发集和测试集应有多大?
开发集的规模应该大到足以区分出你所尝试的不同算法间的性能差异。例如,如果分类器 A 的准确率为 90.0% ,而分类器 B 的准确率为 90.1% ,那么仅有 100 个样本的开发集将无法检测出这 0.1% 的差异。相比我所遇到的机器学习问题,一个样本容量为 100 的开发集的规模是非常小的。通常来说,开发集的规模应该在 1,000 到 10,000 个样本数据之间,而当开发集样本容量为 10,000 时,你将很有可能检测到 0.1% 的性能提升。
在大数据时代,我们所面临的机器学习问题的样本数量有时会超过 10 个亿,即使开发集和测试集中样本的绝对数量一直在增长,可总体上分配给开发集和测试集的数据比例正在不断降低。可以看出,我们并不需要远超过评估算法性能所需的开发集和测试集规模,即开发集和测试集的规模并不是越大越好。
第八章:使用单值评估指标进行优化
所谓的单值评估指标(single-number evaluation metric)有很多,分类准确率就是其中的一种:你在开发集(或测试集)上运行分类器后,它将返回单个的数据值,代表着被正确分类的样本比例。根据这个指标,如果分类器 A 的准确率为 97%,而分类器 B 的准确率为 90%,那么我们可以认为分类器 A 更优秀。
precision recall就不算单值评估指标。如果你认为查准率和查全率很关键,可以参考其他人的做法,将这两个值合并为一个值来表示。例如取二者的平均值,或者你可以计算 “F1分数(F1 score)”
取平均值或者加权平均值是将多个指标合并为一个指标的最常用方法之一。
第九章:优化指标和满意度指标
下面将提到组合多个评估指标的另一种方法。
假设你既关心学习算法的准确率(accuracy),又在意其运行时间(running time)。将准确率和与运行时间放入单个公式计算后可以导出单个的指标,这似乎不太自然。
你可以有一种替代的方案:首先定义一个“可接受的”运行时间,一般低于 100ms 。接着在限定的运行时间范围内最大化分类器的准确率。此处的运行时间是一个“满意度指标” —— 你的分类器必须在这个指标上表现得“足够好”,这儿指的是它应该至多需要 100ms,而准确度是一个“优化指标”。
一般是N-1个满意度指标,1个优化指标。
一旦你的团队的评估指标保持一致并进行优化,他们将能够取得更快的进展。
第十章:通过开发集和度量指标加速迭代
拥有开发集和度量指标,可以使你更快地检测出哪些想法给系统带来了小(或大)的提升 ,从而快速确定要继续研究或者是要放弃的方向。
第十一章:何时修改开发集、测试集和度量指标
我通常会要求我的团队在不到一周(一般不会更长)的时间内给出一个初始的开发集、测试集和度量指标,提出一个不太完美的方案并迅速采取行动 ,比花过多时间去思考要好很多。
如果你渐渐发现初始的开发集、测试集和度量指标设置与期望目标有一定差距,快速想方法去改进它们。
何时需要改变它们:
- 你需要处理的实际数据的分布和开发集/测试集数据的分布情况不同。
- 你在开发集上过拟合了。
- 该指标所度量的不是项目应当优化的目标。
第十二章:小结:建立开发集和测试集(重点)
- 选择作为开发集和测试集的数据,应当与你预期在将来获取并良好处理的数据有着相同的分布,但不需要和训练集数据的分布一致。
- 开发集和测试集的分布应当尽可能一致。
- 为你的团队选择一个单值评估指标进行优化。或者定义满意度指标和优化指标。
- 拥有开发集、测试集和单值评估指标可以帮你快速评估一个算法,从而加速迭代过程。当你探索一个全新的应用时,快速找到开发集、测试集和单值评估指标。
- 开发集的规模应当大到能够检测出算法精度的细微改变,但也不用太大;测试集的规模应该大到能够使你对系统的最终性能作出一个充分的估计。
- 当开发集和评估指标不再能给团队一个正确的导向时,就尽快修改它们:(i) 如果你在开发集上过拟合,则获取更多的开发集数据。(ii) 如果开发集和测试集的数据分布和实际关注的数据分布不同,则获取新的开发集和测试集。 (iii) 如果评估指标不能够对最重要的任务目标进行度量,则需要修改评估指标。
第十三章:快速构建并迭代你的第一个系统
当你想要构建一个新的垃圾邮件过滤系统时,团队可能会有很多不同的想法。
试图在一开始就设计和构建出完美的系统会有些困难,不妨先花几天的时间构建并训练一个最基础的系统。
或许这个最基础的系统离我们所能构建的“最佳”系统相去甚远,但研究里面的基础功能也很有价值:你会很快地找到一些线索来帮助决定在什么方向投入时间。
第十四章:根据开发集样本评估想法
进行误差分析,查看造成系统分类出错的是那些样本,得到几个错误类。哪种站的比例最大就从哪个着手进行改进。
误差分析也可以帮助你发现在不同的想法中哪些更有前景。
误差分析(Error Analysis) 指的是检查算法误分类的开发集样本的过程,以便你找到造成这些误差的原因。这将帮助你确定项目优先级并且获得关于新方向的灵感。
第十五章:在误差分析时并行评估多个想法
通常我会创建一个电子表格,并在查看被误分类的 100 个开发集样本时完善其内容,如下。记录五分类样本的具体情况
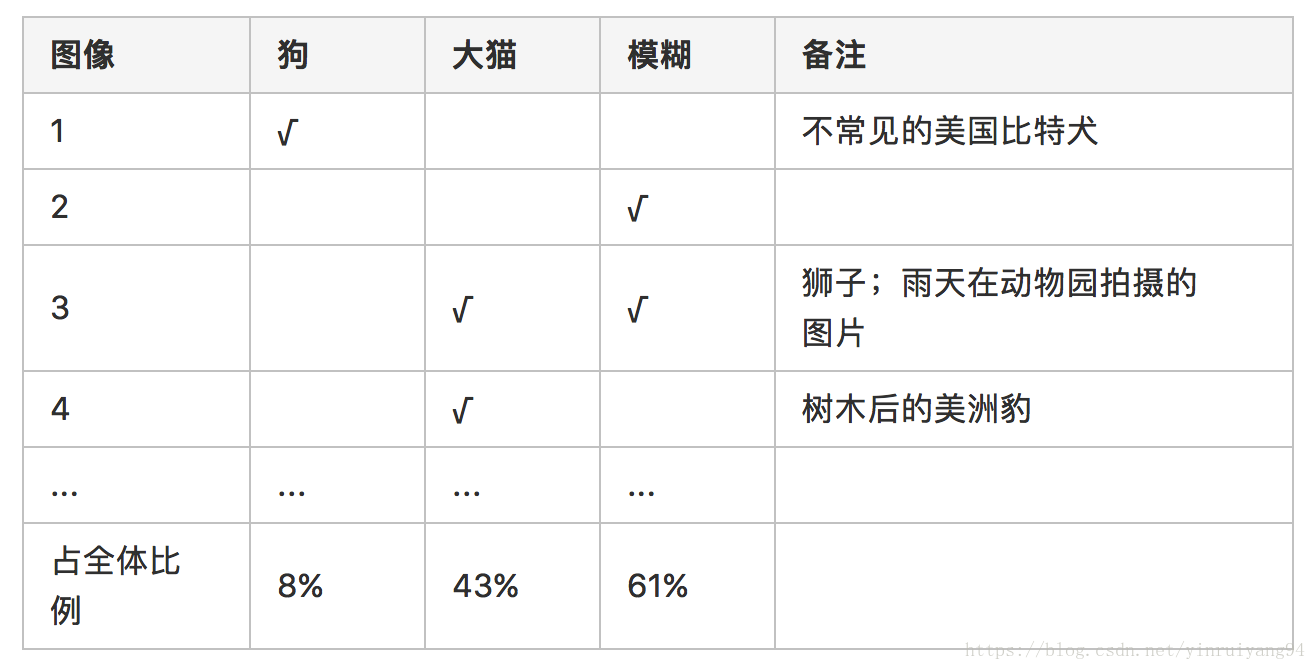
通过表格可以得到优化的优先级。
误差分析并不会产生一个明确的数学公式来告诉你什么任务的优先级最高。你还需要考虑在不同类别上的预期进展以及解决每个类别所需的工作量。
第十六章:清洗误标注的开发集和测试集样本
除了上一章中提到的误分类原因,还有一种是开发集的标签打错,因为这些标签是人工做的,所以难免会出现错误。一般最开始,标签错误带来的误差不会有其他情况大,因此应着手其他情况(当然要视具体情况而定)。随着其他的误差的修正,误标注问题对系统的影响也就越来越大。此时应该着手修正标签。
重点在于不仅仅要修正误分类样本的标签,因为在正确分类的样本中,也会有标注错误的样本。
第十七章:将大型开发集拆分为两个子集,专注其一
假设你有一个含有 5000 个样本的大型开发集,并有着 20% 的误差。因此算法将误分类 1000 张开发集图片。手动检查这 1000 张图片会花费很长时间,在这种情况下,我会明确地将开发集分成两个子集,并只专注其中的一个。
你将会更快地过拟合手动查看的那些图片,而另一部分没有被手动查看的图片可以拿来调参。
Eyeball开发集:用来手动检查,进行误差分析的开发集部分
Blackbox开发集:用来评估算法、调参的开发集部分
当你在 Eyeball 开发集中建立对样本的直观认识之后,则容易更快地过拟合。当你发现 Eyeball 开发集的性能比 Blackbox 开发集提升得更快,说明已经过拟合 Eyeball 开发集了。此时可能需要丢弃它并寻找一个新的 Eyeball 开发集,比如可以将更多 Blackbox 开发集中的样本移到 Eyeball 开发集中,也可以获取新的标注数据。