作为快速入门Kafka系列的第二篇博客,本篇为大家带来的是Kafka集群搭建~
码字不易,先赞后看!

文章目录
Kafka 集群环境搭建
1、初始化环境准备
安装jdk,安装zookeeper并保证zk服务正常启动。
因为在之前的博客中,博主已经将如何搭建Hadoop集群的过程叙述过了,这里就不再重复赘述,有需要的同学可以看看这篇博客《Hadoop(CDH)分布式环境搭建》。
集群规划
| node01 | node02 | node03 |
|---|---|---|
| zk | zk | zk |
| kafka | kafka | kafka |
2、下载安装包并上传解压
通过以下地址进行下载安装包
node01执行以下命令,下载并解压
cd /export/softwares
wget http://archive.apache.org/dist/kafka/1.0.0/kafka_2.11-1.0.0.tgz
tar –zxvf kafka_2.11-1.0.0.tgz -C /export/servers/
3、node01服务器修改kafka配置文件
node01执行以下命令先创建数据文件存放目录
mkdir -p /export/servers/kafka_2.11-1.0.0/logs
再进入到kafka的配置文件目录,修改配置文件
cd /export/servers/kafka_2.11-1.0.0/config
vim server.properties
#broker 的全局唯一编号,不能重复
broker.id=0
#处理网络请求的线程数量
num.network.threads=3
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志存放的路径
log.dirs=/export/servers/kafka_2.11-1.0.0/logs
#topic 在当前 broker 上的分区个数
num.partitions=2
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.flush.interval.messages=10000
log.flush.interval.ms=1000
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
#配置连接 Zookeeper 集群地址
zookeeper.connect=node01:2181,node02:2181,node03:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
#开启 删除 topic 功能
delete.topic.enable=true
#绑定节点的名称,值为当前节点
host.name=node01
4、node01配置环境变量
cd /etc/profile.d
新添一个文件kafka.sh
vim kafka.sh
export KAFKA_HOME=/export/servers/kafka_2.11-1.0.0/
export PATH=$PATH:$KAFKA_HOME/bin
5、 安装包分发到其他服务器上面去
node01执行以下命令,将node01服务器的kafka安装包发送到node02和node03服务器上面去
cd /export/servers/
scp -r kafka_2.11-1.0.0/ node02:$PWD
scp -r kafka_2.11-1.0.0/ node03:$PWD
6.node02与node03服务器修改配置文件
node02使用以下命令修改kafka配置文件
cd /export/servers/kafka_2.11-1.0.0/config
vim server.properties
#broker 的全局唯一编号,不能重复
broker.id=1
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/export/servers/kafka_2.11-1.0.0/logs
num.partitions=2
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.flush.interval.messages=10000
log.flush.interval.ms=1000
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=node01:2181,node02:2181,node03:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
delete.topic.enable=true
host.name=node02
node03使用以下命令修改kafka配置文件
cd /export/servers/kafka_2.11-1.0.0/config
vim server.properties
broker.id=2
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/export/servers/kafka_2.11-1.0.0/logs
num.partitions=2
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.flush.interval.messages=10000
log.flush.interval.ms=1000
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=node01:2181,node02:2181,node03:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
delete.topic.enable=true
host.name=node03
7. kafka集群启动与停止
注意事项: 在kafka启动前,一定要让zookeeper启动起来。
node01执行以下命令将Kafka进程启动在后台
cd /export/servers/kafka_2.11-1.0.0
nohup bin/kafka-server-start.sh config/server.properties 2>&1 &
node02执行以下命令将kafka进程启动在后台
cd /export/servers/kafka_2.11-1.0.0
nohup bin/kafka-server-start.sh config/server.properties 2>&1 &
node03执行以下命令将kafka进程启动在后台
cd /export/servers/kafka_2.11-1.0.0
nohup bin/kafka-server-start.sh config/server.properties 2>&1 &
三台机器也可以执行以下命令停止kafka集群
cd /export/servers/kafka_2.11-1.0.0
bin/kafka-server-stop.sh
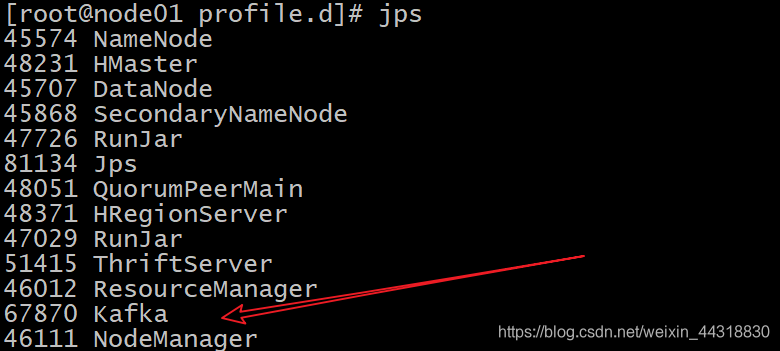
启动成功之后,三台节点均可以通过命令jps可以检测到kafka服务的存在
好了,本篇博客的知识分享就到这里,受益或对大数据技术感兴趣的朋友记得点赞加关注(^U^)ノ~YO,下一篇博客将为大家介绍Kafka的架构,敬请期待|ू・ω・` )

