1、lxml和XPath的介绍
因为爬虫的主要工作是爬取HTML文档,使用正则表达式解析不仅开发效率慢,解析效率也慢,从而使用解析库是我们的上上之选。
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,也可以用于HTML的检索。lxml库是一款高性能的 Python HTML/XML 解析器一个,支持XPath语法。
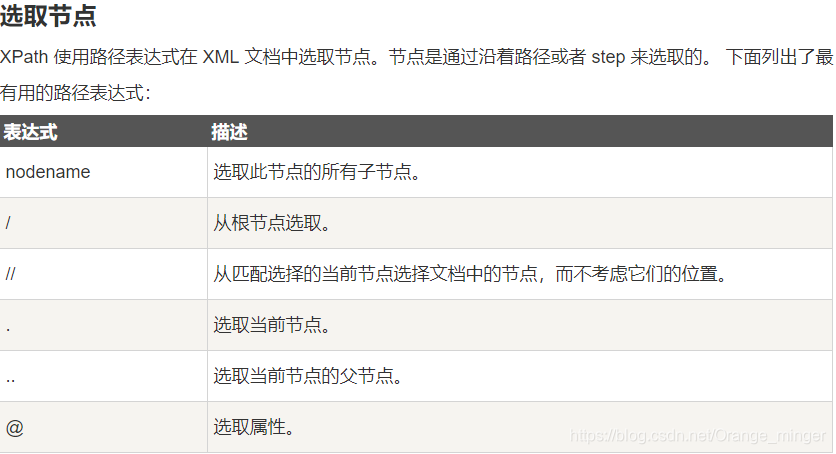
2、XPath规则
3、lxml库的使用
3.1、获取HTML
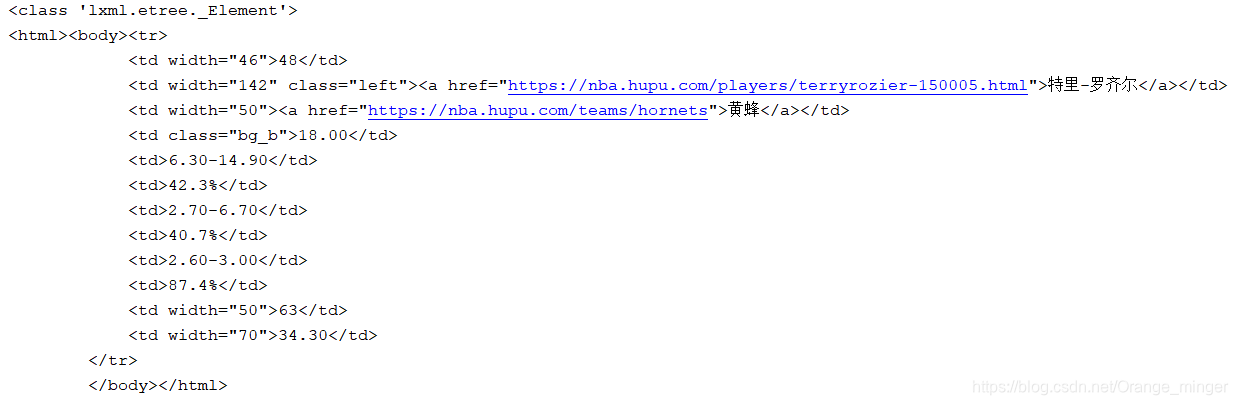
def getHtml():
text = """
<tr>
<td width="46">48</td>
<td width="142" class="left"><a href="https://nba.hupu.com/players/terryrozier-150005.html">特里-罗齐尔</a></td>
<td width="50"><a href="https://nba.hupu.com/teams/hornets">黄蜂</a></td>
<td class="bg_b">18.00</td>
<td>6.30-14.90</td>
<td>42.3%</td>
<td>2.70-6.70</td>
<td>40.7%</td>
<td>2.60-3.00</td>
<td>87.4%</td>
<td width="50">63</td>
<td width="70">34.30</td>
</tr>
"""
html = etree.HTML(text=text)
print(type(html)) # 将一段文本转化为lxml.etree._Element对象
html = etree.tostring(html,encoding='utf-8').decode('utf-8') # 将lxml.etree._Element对象转化为文本的二进制数据,再解码为utf-8
return html
结果输出为:
3.2、获得所有节点
from lxml import etree
def getHtml():
text = """
<tr>
<td width="46">48</td>
<td width="142" class="left"><a href="https://nba.hupu.com/players/terryrozier-150005.html">特里-罗齐尔</a></td>
<td width="50"><a href="https://nba.hupu.com/teams/hornets">黄蜂</a></td>
<td class="bg_b">18.00</td>
<td>6.30-14.90</td>
<td>42.3%</td>
<td>2.70-6.70</td>
<td>40.7%</td>
<td>2.60-3.00</td>
<td>87.4%</td>
<td width="50">63</td>
<td width="70">34.30</td>
</tr>
"""
html = etree.HTML(text=text)
print(type(html)) # 将一段文本转化为lxml.etree._Element对象
return html
if __name__ == '__main__':
html = getHtml()
elements = html.xpath('//*')
for e in elements:
print(e)
3.3、指定属性节点
html = getHtml()
elements = html.xpath('//td[@class="left"]')
for e in elements:
print(e)
3.4、获取文本
from lxml import etree
def getHtml():
text = """
<tr>
<td width="46">48</td>
<td width="142" class="left"><a href="https://nba.hupu.com/players/terryrozier-150005.html">特里-罗齐尔</a></td>
<td width="50"><a href="https://nba.hupu.com/teams/hornets">黄蜂</a></td>
<td class="bg_b">18.00</td>
<td>6.30-14.90</td>
<td>42.3%</td>
<td>2.70-6.70</td>
<td>40.7%</td>
<td>2.60-3.00</td>
<td>87.4%</td>
<td width="50">63</td>
<td width="70">34.30</td>
</tr>
"""
html = etree.HTML(text=text)
# print(type(html)) # 将一段文本转化为lxml.etree._Element对象
return html
if __name__ == '__main__':
html = getHtml()
elements = html.xpath('//td[@class="left"]/a/text()')
for e in elements:
print(e)
3.5、其他方法
可以通过查看文档获取其他节点的方法,基本上大同小异。
有错误的地方敬请指出!觉得写得可以的话麻烦给个赞!欢迎大家评论区或者私信交流!
