就小弟看来,爬虫就是将网页上自己想要的东西扒下来,如果想要精准的找到自己想要的东西,就要学习正则表达式,xpath,BeautifualSoup,这些东西了。
这里给各位老铁安利一下xpath,因为它简单,而且还是万金油,在scrapy中也能够使用。
使用xpath首先要安装lxml库,pip install lxml一句话就搞定了。
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
老铁们可以参考w3c的官方文档,这里我们就不多说了。
这里我们简单讲一讲xpath的使用。
表达式 描述
nodename 选取此节点的所有子节点。
/ 从根节点选取。
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
. 选取当前节点。
.. 选取当前节点的父节点。
@ 选取属性。
路径表达式
body 选取 body 元素的所有子节点。
/div 选取根元素div。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径!
body/div 选取属于 body 的子元素的所有 div 元素。
//span 选取所有 span 子元素,而不管它们在文档中的位置。
div//span 选择属于 div 元素的后代的所有 span 元素,而不管它们位于div之下的什么位置。
//@lhref 选取名为 href 的所有属性。
/body/div[1] 选取属于 body 子元素的第一个 div 元素。
/body/div[last()] 选取属于 body 子元素的最后一个 div 元素。
/body/div[last()-1] 选取属于 body子元素的倒数第二个 div 元素。
/body/div[position()<3] 选取最前面的两个属于body 元素的子元素的 div 元素。
//img[@src] 选取所有拥有名为 src 的属性的 div元素。
//div[@class=’main’] 选取所有 div 元素,且这些元素拥有值为 main 的 class 属性。
为了鲜明的了解,我们还是对这一位小姐姐下手吧!
右键点击图片审查元素
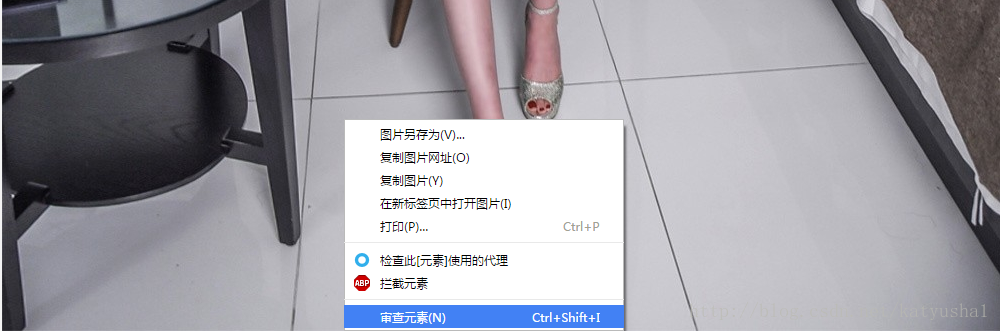

我们可以看见img的父节点是p,而p的父节点是div
如果想要用xpath找到图片的url地址只需要这样
//div[@class=”ImageBody”]/p/img/@src
为了确认我们的xpath表达式是否正确,我们可以利用chromo浏览器的Xpath Help插件验证一下

(Xpath Help的插件实在不好找!我是用免费vpn在线安装的,所以找不到插件安装包…………)
然后我们用代码验证一下,是否能够成功运行
代码:
# -*- coding:utf-8 -*-
from urllib import request, parse
#使用lxml的etree库
from lxml import etree
url='http://www.umei.cc/meinvtupian/xingganmeinv/78153.htm'
headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}
req=request.Request(url,headers=headers)
response=request.urlopen(req)
html=response.read().decode("utf-8")
#将html解析为xml文档
content=etree.HTML(html)
#利用xpath解析xml文档,获得的结果是一个list列表
imgurl=content.xpath('//div[@class="ImageBody"]/p/img/@src')
print(imgurl)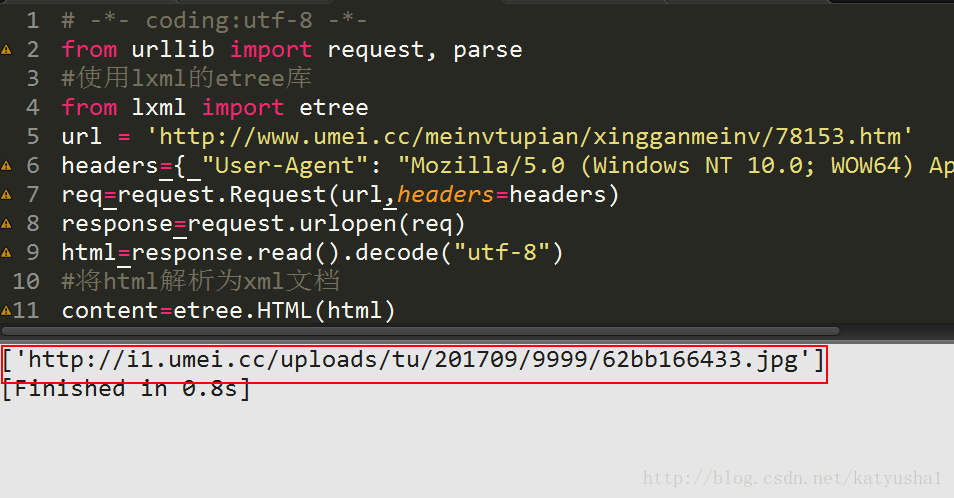
图片的url地址找到!
大功告成!