版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012535605/article/details/80487514
参考原文: 点击打开链接
XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力。 [1] 起初 XPath 的提出的初衷是将其作为一个通用的、介于XPointer与XSLT间的语法模型。但是 XPath 很快的被开发者采用来当作小型查询语言。
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<pi class="item-inactive"><a href="link3.html">third item</a></pi>
<ci class="item-1"><a href="link4.html">fourth item</a></ci>
<ti class="item-0"><a href="link5.html">fifth item</a></ti>
</ul>
</div>
'''
html = etree.HTML(text)
result = etree.tostring(html)
print(result)1 节点关系
1.1 父节点
每个元素以及属性都有一个父节点
在上面的例子中:div是ul的父节点,ul是li的父节点
1.2 子节点
在上面的例子中:ul是div的子节点,li是ul的子节点
1.3同胞节点
在上面的例子中:li、pi、ci、ti是同胞节点
1.4先辈节点
在上面的例子中:div是ul、pi、li、a的先辈节点
1.5后代节点
在上面的例子中:ul、pi、li、a是div的后代
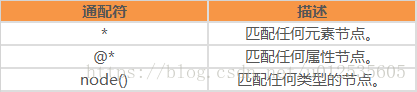
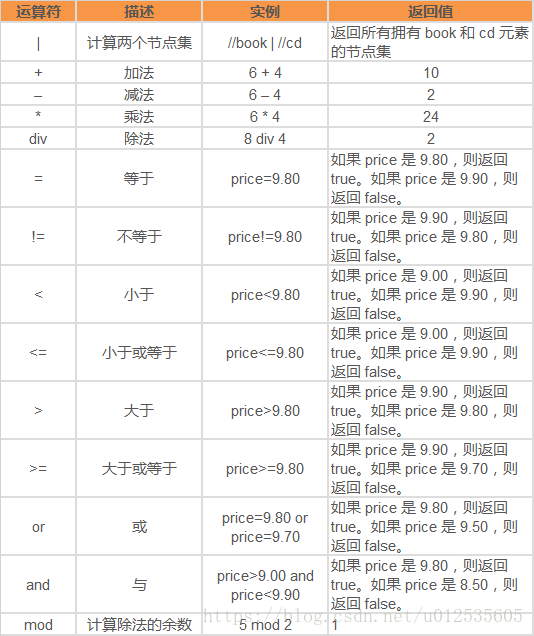
2 规则和表达式
表达式:
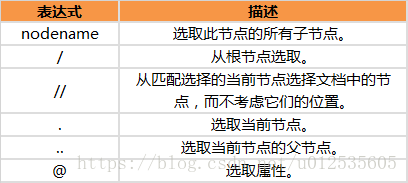
路径表达式
扫描二维码关注公众号,回复:
3113921 查看本文章




3 LXML用法
3.1获取所有li标签
其中,这里体现了 lxml 的一个非常实用的功能就是自动修正 html 代码,大家应该注意到了,最后一个 li 标签,其实我把尾标签删掉了,是不闭合的。不过,lxml 因为继承了 libxml2 的特性,具有自动修正 HTML 代码的功能。
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
html = etree.HTML(text)
result = etree.tostring(html)
print(result)输出:<html><body>
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</body></html>利用parse来解析读取文件,把上述代码存为hello.html的文件名
from lxml import etree
html = etree.parse('hello.html')
result = etree.tostring(html, pretty_print=True)
print(result) from lxml import etree
html = etree.parse('hello.html')
print (type(html))
result = html.xpath('//li')
print (result)
print (len(result))
print (type(result))
print (type(result[0]))
<class 'lxml.etree._ElementTree'>
[<Element li at 0x13f66488>, <Element li at 0x13f66b48>, <Element li at 0x13f66108>, <Element li at 0x13effb08>, <Element li at 0x13eff188>]
5
<class 'list'>
<class 'lxml.etree._Element'>从上面的代码中可以看出:etree.parse的类型为<class 'lxml.etree._ElementTree'>
通过Xpath之后有5个包含li的标签
3.2获取 <li> 标签的所有 class
esult = html.xpath('//li/@class')
print (esult)
['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']3.3 获取 <li> 标签下 href 为 link1.html 的 <a> 标签
html.xpath('//li/a[@href="link1.html"]')
Out[7]: [<Element a at 0xa8d6d48>]3.4 获取 <li> 标签下 所有的 <a> 标签
html.xpath('//li/a[@href]')
Out[9]:
[<Element a at 0xa8d6d48>,
<Element a at 0xa951308>,
<Element a at 0xa8d6688>,
<Element a at 0xa984848>,
<Element a at 0xa984788>]
html.xpath('//li/a')
Out[10]:
[<Element a at 0xa8d6d48>,
<Element a at 0xa951308>,
<Element a at 0xa8d6688>,
<Element a at 0xa984848>,
<Element a at 0xa984788>]
html.xpath('//li//a')
Out[11]:
[<Element a at 0xa8d6d48>,
<Element a at 0xa951308>,
<Element a at 0xa8d6688>,
<Element a at 0xa984848>,
<Element a at 0xa984788>]3.5 获取最后一个 <li> 的 <a> 的 href
html.xpath('//li[last()]/a/@href')
Out[16]: ['link5.html']3.6 获取倒数第二个 <li> 的 <a> 的 href
result = html.xpath('//li[last()-1]/a')
print (result[0].text)3.7 获取倒数第二个 <li> 的 <a> 的标签
html.xpath('//li[last()-1]/a')[0].tag