Ubuntu16.04以上
Hadoop 2.7.1以上
Java JDK 1.7以上
Spark 2.1.0
1、安装好jdk
2、解压spark文件
tar -xvf spark-2.0.1-bin-hadoop2.7.tgz
3、进入安装文件
cd conf
修改配置文件
复制conf spark-env.sh.template 文件为 spark-env.sh
在其中修改,增加如下内容
SPARK_LOCAL_IP=服务器IP地址

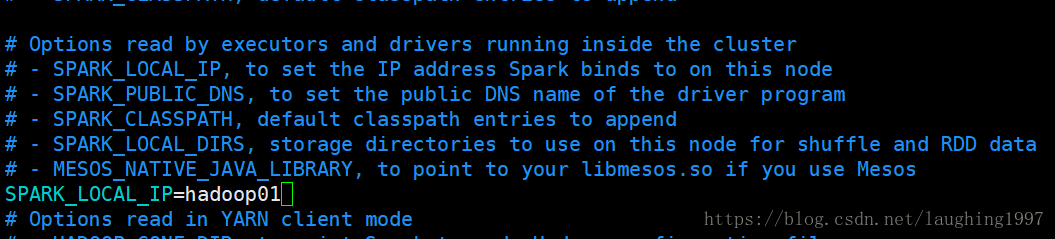
注意,我IP是主机名映射的。
主机名映射教程:
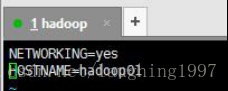
1.配置主机名
执行:vim /etc/sysconfig/network
编辑主机名
**注意:主机名里不能有下滑线,或者特殊字符 #$,不然会找不到主机导致无法启动 这种方式更改主机名需要重启才能永久生效,因为主机名属于内核参数。 如果不想重启,可以执行:hostname hadoop01。但是这种更改是临时的,重启后会恢复 原主机名。
所以可以结合使用。先修改配置文件,然后执行:hostname hadoop01 。可以达到不重启或 重启都是主机名都是同一个的目的**
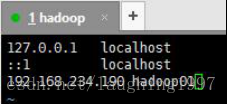
2.配置hosts文件
执行:vim /etc/hosts
3.spark的使用
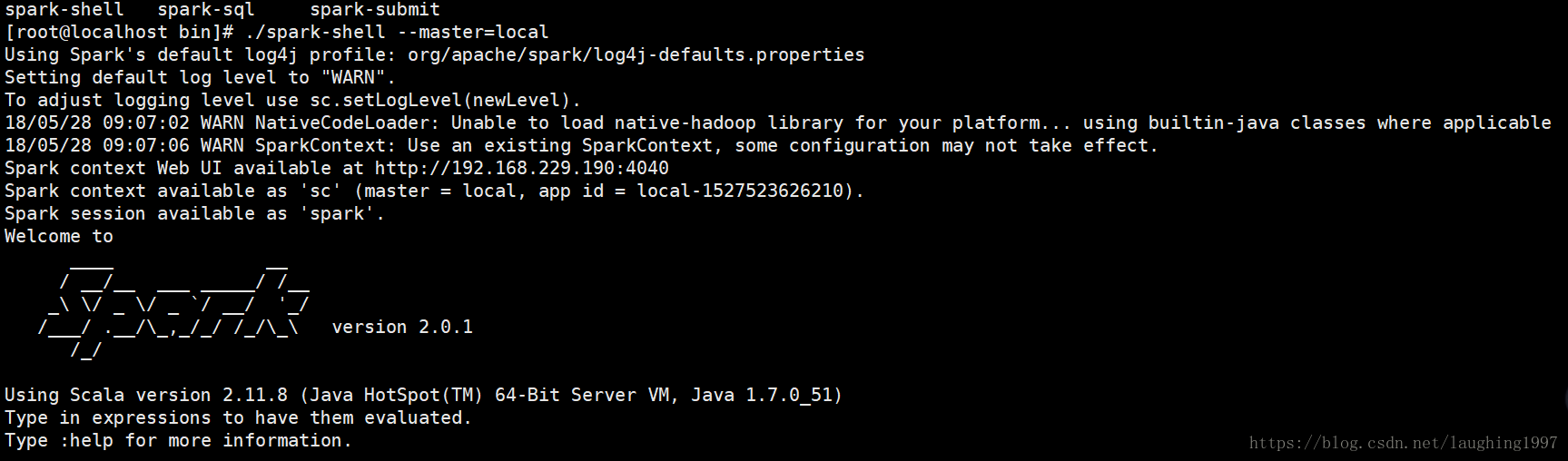
在bin目录下通过 spark-shell --master=local 启动本地模式
启动后 发现打印消息
Spark context Web UI available at http://192.168.242.101:4040//Spark的浏览器界面
Spark context available as 'sc' (master = local, app id = local-1490336686508).//Spark提供了环境对象 sc
Spark session available as 'spark'.//Spark提供了会话独享spark