如果要全面的使用spark,你可能要安装如JDK,scala,hadoop等好些东西。可有时候我们只是为了简单地安装和测试来感受一下spark的使用,并不需要那么全面。对于这样的需要,我们其实只要安装好JDK,然后下载配置spark,两步即可。
本文选择:
1、centos
2、JDK1.8
3、spark2.3
一、JDK安装
spark需要运行在Java环境中,所以我们需要安装JDK。
JDK安装配置参考:https://www.cnblogs.com/lay2017/p/7442217.html
二、spark安装
下载
我们到spark官网(http://spark.apache.org/downloads.html),找到对应的spark的tar包地址:https://archive.apache.org/dist/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz

我们新建一个目录存放spark的下载文件
mkdirs /usr/local/hadoop/spark
进入该目录,使用wget命令下载

wget https://archive.apache.org/dist/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz
配置
下载完毕以后我们先解压
tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz
你会得到一个文件夹
spark-2.3.0-bin-hadoop2.7
我们编辑/etc/profile文件,添加环境变量

并使之生效
source /etc/profile
我们启动spark-shell看看是否配置成功
spark-shell
你会进入shell面板
这样,我们即安装好了单机spark。如果你使用spark-shell提供的scala做操作的话(也就是不单独运行scala程序),其实就不需要安装scala。我们也不需要去集成到独立的hadoop中,所以也不用安装hadoop。
三、spark-shell测试
上面的安装完成以后,你可能希望做一些很简单的操作,来感受一下spark。在此之前,我们先准备一份txt文件
我们在:/usr/local/hadoop/spark目录下创建一个txt文件,文件内容如下:
hello java
hello hadoop
hello spark
hello scala
然后我们启动spark-shell(退出使用":quit"命令)
spark-shell
我们执行以下代码
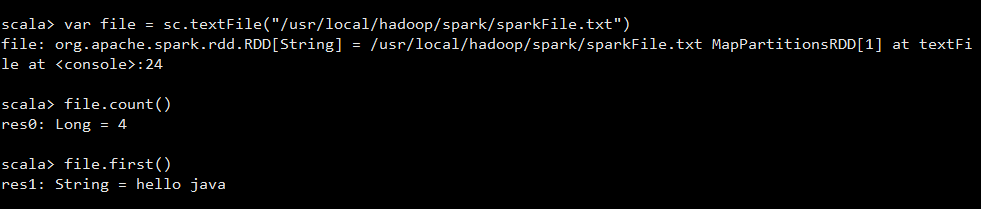
首先我们使用sparkContext的textFile方法加载了我们刚刚创建的txt文件
然后,统计该文件的行数,以及我们查找了第一行的数据。