1、上传scala和spark架包
scala官网下载:https://www.scala-lang.org/download/
spark官网下载:http://spark.apache.org/downloads.html
2、解压包,重命名
#scala
tar -zxf scala-2.12.7.tgz
mv scala-2.12.7 scala
#spark
tar -zxf spark-2.3.2-bin-hadoop2.7.tgz
mv spark-2.3.2-bin-hadoop2.7 spark
3、配置scala 和spark的环境变量
vi /etc/profile
#shift+g 快速定位到最后一行 #scala export SCALA_HOME=/home/scala export PATH=${SCALA_HOME}/bin:$PATH #spark export SPARK_HOME=/home/spark/ export PATH=${SPARK_HOME}/bin:$PATH
4、加载环境变量
source /etc/profile
5、 cd 到spark 的conf里面拷贝文件
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
6、加入配置
vi slaves
加入localhost或者服务器IP
vi spark-env.sh
#java
export JAVA_HOME=/home/jdk
#scala
export SCALA_HOME=/home/scala
#Spark主节点的IP
export SPARK_MASTER_IP=服务器IP
#Spark主节点的端口号
export SPARK_MASTER_PORT=7077
7、关闭防火墙
[root@localhost ]# systemctl stop firewalld.service //关闭防火墙服务 [root@localhost ]# systemctl disable firewalld.service //禁止防火墙服务开机启动
8、进入spark/sbin目录启动spark
cd /home/spark/sbin
./start-all.sh
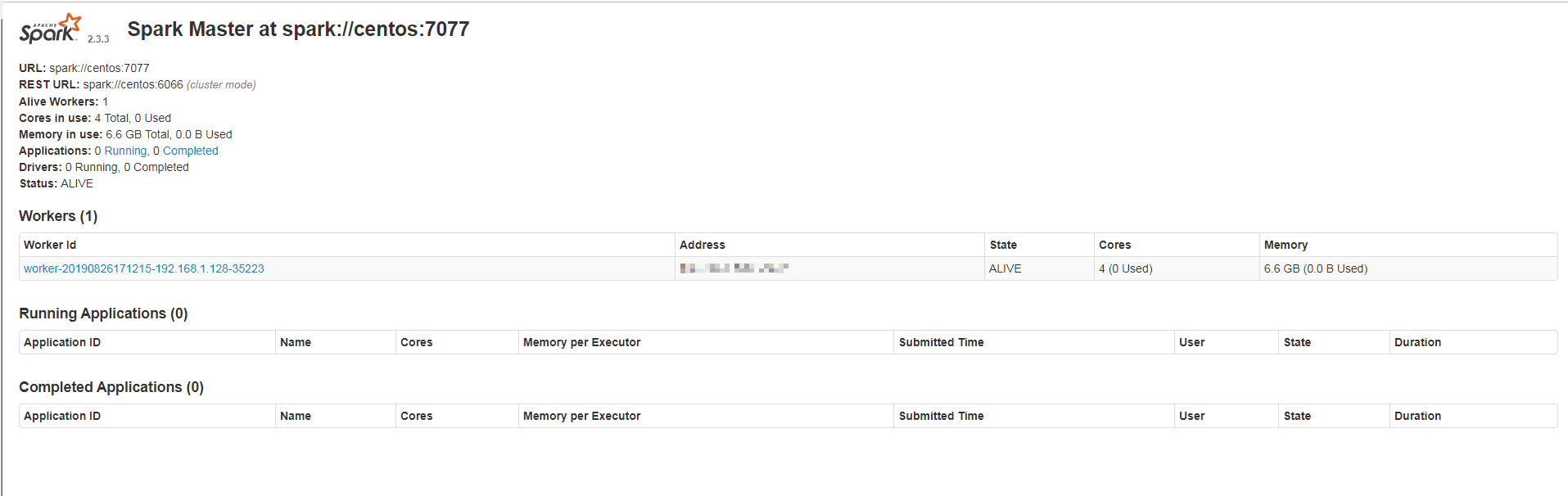
9、然后再浏览器上输入: 你spark安装的IP:8080,出现如下效果,则安装成功