新手版手写数字识别
当我们开始学习编程的时候,第一件事往往是学习打印”Hello World”。就好比编程入门有Hello World,机器学习入门有MNIST。
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片,大概长成这样:
不但有图片,而且也做好了标签,换句话说,每个图像对应的是数字几也给标注好了。
这个教程只是为了演示TesnorFlow的功能,所以为了容易理解用了一个很简单的预测模型。
MNIST数据集介绍
参考:http://www.tensorfly.cn/tfdoc/tutorials/mnist_download.html
在正式开始之前,对数据集做个介绍。
MNIST是在机器学习领域中的一个经典问题。该问题解决的是把28x28像素的灰度手写数字图片识别为相应的数字,其中数字的范围从0到9。
官方教程为了方便新手入门,对数据集也做了封装和重构。
下载数据集
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
import tempfile
import numpy
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
from tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets
# 你会发现`MNIST_data`目录下多了四个压缩文件
mnist = read_data_sets('MNIST_data', one_hot=True)Extracting MNIST_data\train-images-idx3-ubyte.gz
Extracting MNIST_data\train-labels-idx1-ubyte.gz
Extracting MNIST_data\t10k-images-idx3-ubyte.gz
Extracting MNIST_data\t10k-labels-idx1-ubyte.gz
| 文件 | 内容 |
|---|---|
| train-images-idx3-ubyte.gz | 训练集图片 - 55000 张 训练图片, 5000 张 验证图片 |
| train-labels-idx1-ubyte.gz | 训练集图片对应的数字标签 |
| t10k-images-idx3-ubyte.gz | 测试集图片 - 10000 张 图片 |
| t10k-labels-idx1-ubyte.gz | 测试集图片对应的数字标签 |
数据集说明
底层的源码将会执行下载、解压、重构图片和标签数据来组成以下的数据集对象:(通过mnist = read_data_sets('MNIST_data', one_hot=True))
| 数据集 | 目的 |
|---|---|
| data_sets.train | 55000 组 图片和标签, 用于训练 |
| data_sets.validation | 5000 组 图片和标签, 用于迭代验证训练的准确性。 |
| data_sets.test | 10000 组 图片和标签, 用于最终测试训练的准确性。 |
print(len(mnist.train.images),len(mnist.validation.images),len(mnist.test.images))55000 5000 10000
每一张图片包含28X28个像素点,可以用一个矩阵来表示:

我们把这个数组展开成一个向量,长度是 28x28 = 784。如何展开这个数组(数字间的顺序)不重要,只要保持各个图片采用相同的方式展开。
展平图片的数字数组会丢失图片的二维结构信息。这显然是不理想的,最优秀的计算机视觉方法会挖掘并利用这些结构信息,我们会在后续教程中介绍。但是在这个教程中我们忽略这些结构,所介绍的简单数学模型,softmax回归(softmax regression),不会利用这些结构信息。
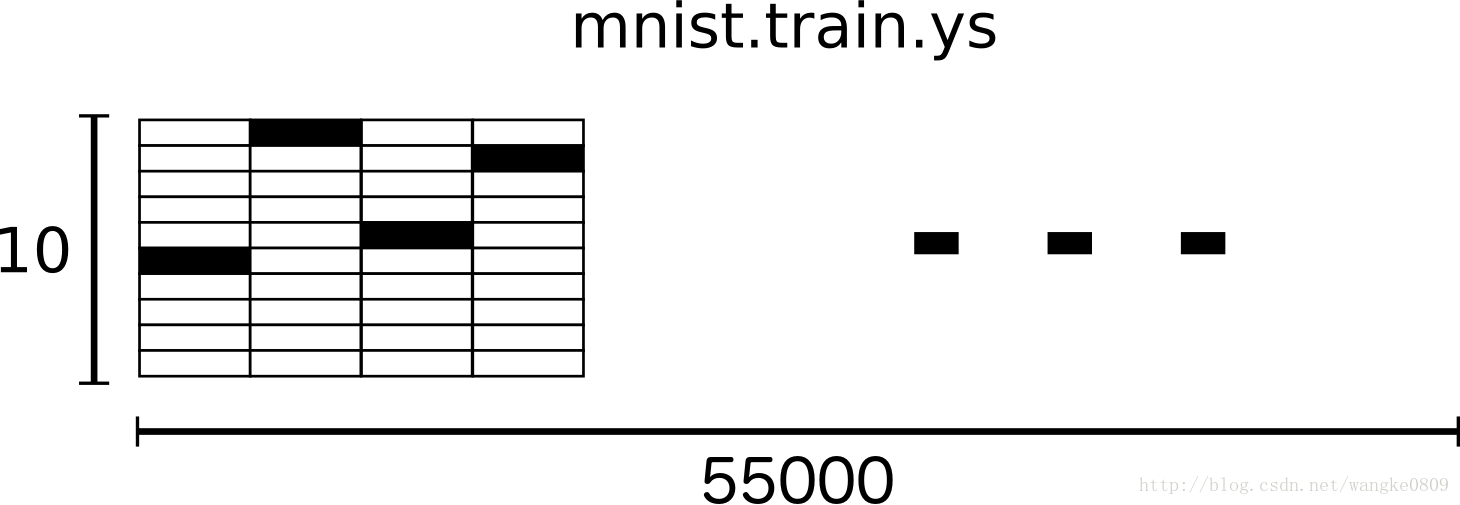
因此,在MNIST训练数据集中,mnist.train.images 是一个形状为 [60000, 784] 的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于0和1之间。直观点看是这样:

one-hot vectors
相对应的MNIST数据集的标签是介于0到9的数字,用来描述给定图片里表示的数字。 一个one-hot向量除了某一位的数字是1以外其余各维度数字都是0。所以在此教程中,数字n将表示成一个只有在第n维度(从0开始)数字为1的10维向量。比如,标签0将表示成([1,0,0,0,0,0,0,0,0,0,0]),1则表示成[0,1,0,0,0,0,0,0,0,0]。因此, mnist.train.labels 是一个 [60000, 10] 的数字矩阵。
现在,我们准备好可以开始构建我们的模型啦!
构建模型
手写数字识别是个Classfication分类问题,所以来搞个最简单最基本的Softmax regressionSoftmax回归,虽然叫regression,但其实是分类,名字的叫法历史遗留问题而已…
设计模型
也就是李宏毅教授讲的 Step 1 : A set of function
上代码:
#输入28*28=784
x = tf.placeholder("float", [None, 784])
#为什么是【784,10】?
W = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))placeholder为占位符,None表示第一个纬度可为任意长度
Variable可修改的张量存在在TensorFlow的用于描述交互性操作的图中。它们可以用于计算输入值,也可以在计算中被修改。对于各种机器学习应用,一般都会有模型参数,可以用Variable表示。(Getting started有介绍)
tf.zeros全零矩阵
x为输入,需要28*28=784个输入参数
W为Weight权重矩阵,通过下面两个图理解一下【784,10】

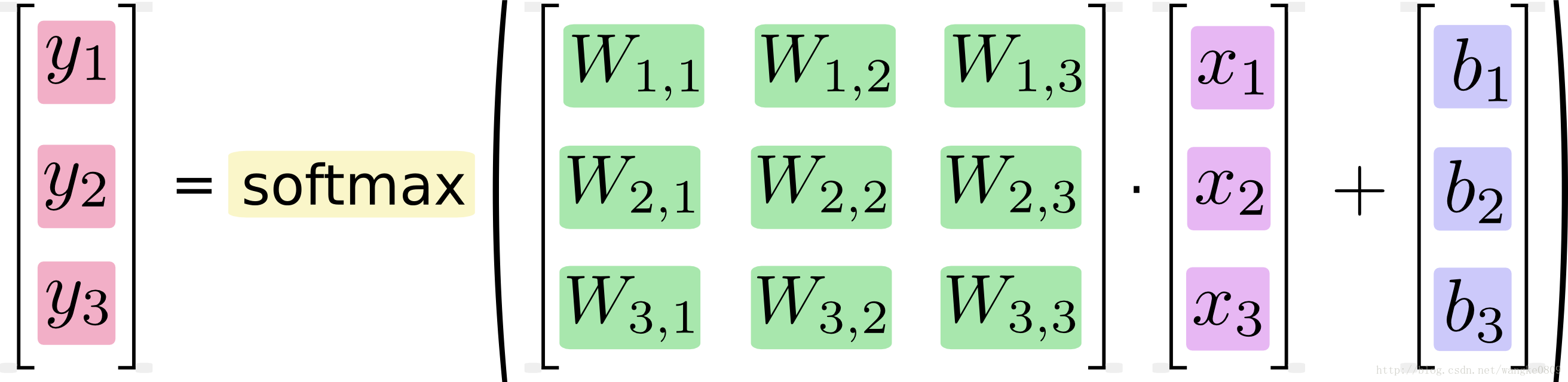
按上图理解x应该是个784*1(行*列)的矩阵,W是10*784的矩阵,W*x得到10*1的矩阵
在实际写代码的时候,x = tf.placeholder("float", [None, 784])表示每个张量的第二纬度是固定的,也就是输入784个像素点,有多少个这样的784像素点不确定,所以可以这样理解,x是个1*784的矩阵,W是784*10的矩阵,x*W得到1*10的矩阵。
y = tf.nn.softmax(tf.matmul(x,W) + b)tf.matmul(x,W)表示x乘以W,矩阵相乘,然后通过softmax输出。
这里是x在前而不是W在前。
Goodness of Function
李弘毅教授的Step 2 : Goodness of Function找个方法来衡量一下函数的好坏。
y_ = tf.placeholder("float", [None,10])
loss_func = y_*tf.log(y)
cost_func = -tf.reduce_sum(loss_func)y为神经网络计算出的值
y_为训练数据
tf.reduce_sum计算张量的所有元素的总和
loss function与cost function我原本以为是一个意思,后来看了吴恩达教授的课后发现这俩还是有区别的,前者是某一个样本的误差,后者是所有的样本误差之和。
Best Function
李弘毅教授的Step 3 : Best Function,找一个最好的函数。这里用梯度下降法来找。这里只是选择了梯度下降算法,并没有真正开始计算。
learning_rate = 0.01
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost_func)训练模型
在运行计算之前,我们需要添加一个操作来初始化我们创建的变量
init = tf.global_variables_initializer()在一个Session里面启动模型,并且初始化变量
sess = tf.Session()
sess.run(init)开始训练
每训练50次输出一下当前的cost
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})验证
在测试集上进行验证
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))0.9182
首先让我们找出那些预测正确的标签。tf.argmax是一个非常有用的函数,它能给出某个tensor对象在某一维上的其数据最大值所在的索引值。由于标签向量是由0,1组成,因此最大值1所在的索引位置就是类别标签,比如tf.argmax(y,1)返回的是模型对于任一输入x预测到的标签值,而 tf.argmax(y_,1) 代表正确的标签,我们可以用 tf.equal 来检测我们的预测是否真实标签匹配(索引位置一样表示匹配)。
这行代码会给我们一组布尔值。为了确定正确预测项的比例,我们可以把布尔值转换成浮点数,然后取平均值。例如,[True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75.
更加直观
所以,我训练好了这个模型,怎么能更加直观的看出效果呢?
来,可视化一下这个测试数据集的第一个图片:
import cv2
img = cv2.threshold(mnist.test.images[0:1].reshape(28,28), 0.2, 255, cv2.THRESH_BINARY)
cv2.imwrite('number.bmp',mnist.test.images[0:1].reshape(28,28)*255)True
长这样,是个数字7:

来用模型预测一下:
print(sess.run(y,feed_dict={x: [mnist.test.images[0]]}))[[ 4.78636775e-06 6.37775180e-11 5.33124967e-06 6.77303236e-04
9.03468020e-08 1.01798132e-05 7.99003919e-11 9.99229670e-01
2.13898397e-06 7.05658749e-05]]
可以发现,输出的one-hot标签里面,第8位99.92%几乎为1,其余为零,第8位对应的是数字7,预测正确!
