0. 前言
互联网发展历史中,最绚烂的结果当属搜索引擎,但通用的搜索引擎并不能完全满足用户对于有偏好信息检索的需求,基于关键词的搜索在很多情况下不能精准和深刻的反映用户的潜在需求,搜索引擎始终无法平衡在搜索广度和搜索精准程度之间的矛盾,推荐系统应运而生。
1. 推荐系统概述
a) 初识推荐系统-亚马逊网站
推荐系统算法原理精妙却不复杂,它的迅速成功归因于它着力于对需求的深刻理解,从需求定位,多数情况用户需求很难用简单的关键字来表述;从需求个性,用户需要更加符合个人偏好的查询结果;衍生需求的模糊性,购买行为产生新的购买需求。
对亚马逊网站的简单分析可以得到商品列表这样的组成部分:
- 经常一起购买的产品->打包销售
- 购买此商品的顾客也购买了:协同过滤
- 看过此商品的顾客购买的其它商品:通过浏览行为做出推荐
- 用户商品评论列表:评论文本和打分
b) 推荐系统架构
如下图,从左到右分为三部分,第一部分是环形区域,表示推荐系统的数据来源,第二部分是矩形排列的部分,是算法区域,第三部分是推荐结果,建立物品与用户的关联:
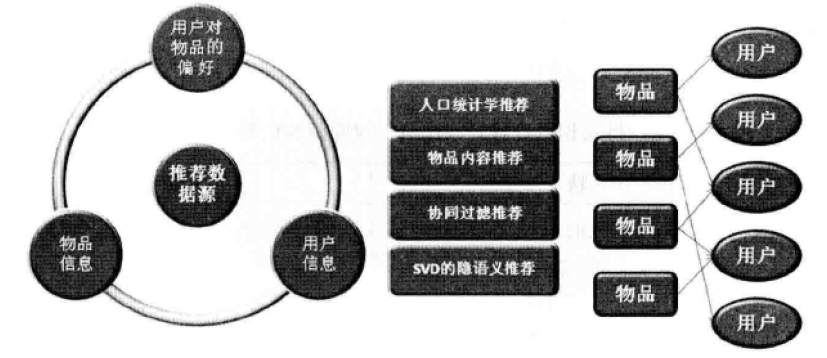
- 第一部分是环形区域,表示一个完整的推荐系统最少存在的三个参与方(一个矩阵)
l 物品信息
l 用户信息
l 用户对物品或者信息的偏好
n 显式的用户反馈
n 隐式的用户反馈【浏览信息】
用户偏好在不同企业都存在差异,可以简单了解一下各个因素以及其起作用的方式【图片来自《探索推荐引擎内部的秘密》】:
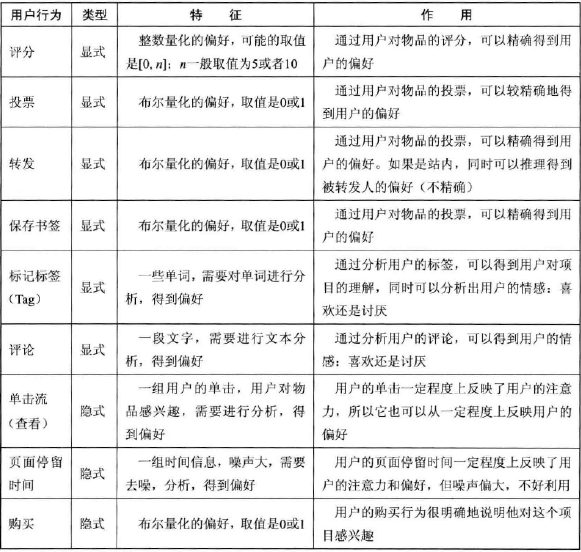
- 第二部分是算法区域:
l 基于人口统计学的推荐机制【根据用户基本信息发现用户关联程度】
l 基于内容的推荐【根据物品或者内容的相关性】
l 基于协同过滤的推荐【根据用户对物品或者信息的偏好发现物品或者内容本身的相关性或者用户的相关性】,分为:
n 基于用户的推荐
n 基于项目的推荐
l 基于隐语义的推荐模型,也称基于模型的推荐(协同过滤的相似度计算模型),目前精度最高的算法是SVD隐语义模型,当然啊还有其他
c) 开源推荐系统
机器学习的大多数算法有以下特点:
l 经历了较长时间的验证,稳定性强,一旦部署不轻易修改
l 执行的多数数据密集型的任务,即在训练阶段属于CPU密集型任务,再分类或者预测阶段属于I/O密集型任务。
l 算法改进和优化涉及知识产权,脚本代码多数会被反编译不是和具有知识产权的算法编码
2. 协同过滤机器算法
a) 协同过滤
系统过滤通过用户和产品及用户的偏好信息产生推荐的策略,最基本的策略有两种,一是找到具有类似品味的人所喜欢的物品,二是从一个人喜欢的物品中找出类似的物品,即基于用户和基于物品的推荐技术,它们被称为系统过滤。
协同过滤可以利用用户和物品的信息来预测用户的好恶,并发现新的用户还不知道的东西,形成促销策略。它一般在海量的用户中发掘出一小部分和你品味比较类似的,在协同过滤中,这些用户成为领导,根据他们所喜欢的其他东西组织成一个排序的目录作为推荐给你。
首先了解一下协同过滤的模型和算法
l 数据预处理和UI矩阵
l 推荐模型:User CF和Item CF
l KMeans计算相似性
l SVD计算相似性
b) 数据预处理
大型电商五站都提供多种跟踪用户行为的方法,组合这些用户可以参考以下两种方式:
l 将不同的行为分组
l 根据不同行为反映用户偏好的程度将它们进行加权,得到用户对于物品的总体偏好
收集了用户行为数据,还需要对数据进行一定的预处理,减噪和归一化是最常用的方法,目的是为了下一步的聚类:
l 用户行为数据是用户在使用应用过程中产生的,可能存在大量噪声和用户的误操作,通过减噪算法过滤数据中的噪声,一般是离群点,这样可以使我们的分析更加精准
l 归一化:在计算用户对物品的偏好程度时,不同的数据取值量纲不同,甚至差异很大
l 使用专门的方法聚类:原始数据都是基于单个用户和单个物品的,这样会导致计算量过大
- 使用Scikit-Learn的KMeans聚类
- User CF原理
User Item即UI矩阵,行是用户列表,列是物品列表,值是用户对物品的偏好,一般是归一化之后的,基于用户的CF基本思想很简单,基于用户对物品的偏好划分用户类型(聚类),找到最近邻用户(kNN算法),然后将同类用户和相邻用户所喜欢的推荐给当前用户。计算上就是建一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到K邻居后,根据邻居的相似度权重及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。
- Item CF原理
基于物品的CF原理,在计算时采用物品之间的相似度,而不是从用户的角度,即基于用户对物品的偏好划分物品类型找到最近邻物品将其推荐给当前用户。从计算的角度就是将所有用户对每个物品的偏好作为一个向量来计算物品之间的相似度,得到物品的相似物品后,根据用户历史的偏好预测当前用户还没有表示偏好的物品,计算得到一个排序的物品列表作为推荐。
- SVD原理与计算
在协同过滤的模型中我们得到一个UI矩阵,并希望通过此得到基于User CF或者Item CF的相似性,一次作为依据进行推荐,实践中关于相似性计算存在如下一些问题:
l 物品的人为分类对推荐算法造成影响,分类是认为指定的,不同的分类标准对不同用户带来预测精度的问题
l 类中物品的相似度是一个消费行为的问题,需要针对不同用户确定不同的权重
l 即使能够构建权重和分类,也不能完全确定某个用户对某类产品感兴趣的程度
因此,需要一种针对每类用户的不同消费行为来计算对不同物品的相似度的算法,相比与传统的相似性计算方法,SVD的推荐算法的有点在于通过训练样本集对用户和物品建模,训练样本集可以很大,它反映了一段时间内用户与物品的各种综合指标,这样较少了认为预测的敢于,特别是物品或用户的错分,对孤立值不敏感。
c) KMeans算法
- 算法流程
l 从N个数据文房中随机选取K个数据文档作为质心
l 对剩余的每个数据文档测量其到每个质心的距离并把它归到最近的质心的类
l 重新计算各个类的质心
l 迭代以上两部直至质心与原质心相等或者小于制定阈值,算法结束
整体流程如下图:
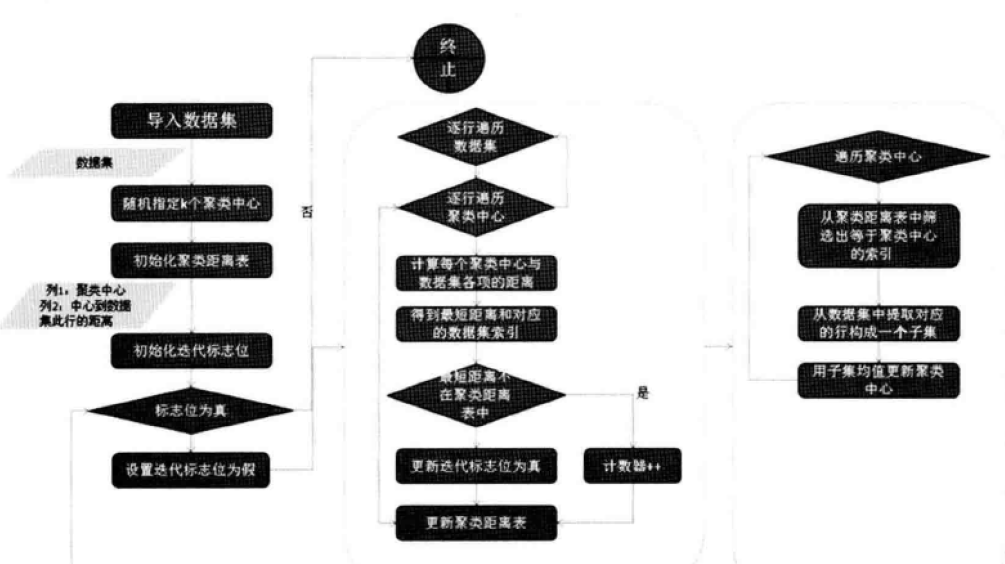
KMeans算法简单容易掌握,数学上可证明收敛,但是也存在一些问题:
l 算法的初识中心点选择与算法的运行效率密切相关,而随机选取中心点有可能导致迭代次数很大或者局部最优,通常k<<n且t<<n,所以算法经常局部最优收敛
l K均值最大问题是要求用户必须实现给出k的个数,k的选择一般基于一些经验值或者多次实验结果
l 对异常偏离的数据敏感
- 算法改进-二分KMeans算法
二分KMeans的主要思想是:首先将所有点作为一个cu,然后将该簇一分为二。之后选择能最大限度降低聚类代价函数【误差平方和】的簇分为两个簇,以此进行下去,直到簇的数目等于用户给定的数目k为止。隐含的一个原则是:因为聚类的误差平方和能够衡量聚类性能,该值越小表示数据点越接近于他们的质心,聚类效果就越好,所以我们就需要对误差平方和最大的簇进行再一次划分,因为误差平方和越大,表示该簇聚类效果约不好,越有可能是多个簇被当成一个簇,所以我们首先需要对这个簇进行划分。
d) SVD算法【详见博文】