ML学习笔记
一、环境搭建
1、pytorch-gpu
在这里推荐使用清华源安装:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda install pytorch torchvision cudatoolkit=10.0 (版本号从https://pytorch.org/上,查找对应版本)
这里有个坑
许多同学表示添加镜像源之后,安装pytorch的过程依然很漫长,甚至中断退出安装,甚至有不少帖子表示“不要再使用清华镜像源了”。
其实真正的问题是,pytorch官网中给出的下载命令为:
conda install pytorch torchvision cudatoolkit=9.0 -c pytorch
其中,-c pytorch参数指定了conda获取pytorch的channel,在此指定为conda自带的pytorch仓库。
因此,只需要将-c pytorch语句去掉,就可以使用清华镜像源快速安装pytorch了。
2、TensroFlow2.0安装
1、在这里建议使用清华源pip安装:
pip install tensorflow-gpu -i https://pypi.tuna.tsinghua.edu.cn/simple
2、然后,再使用conda安装相应的cuda、cudnn:
conda install cudatoolkit=10.0 cudnn=7.6
3、测试是否安装成功
import tenosorflow as tf
print(tf.__version__)
# 输出'2.0.0-alpha0'
print(tf.test.is_gpu_available())
# 会输出True,则证明安装成功
二、基本知识点
1、激活函数activation function
1.1.1 在深度学习中使用ReLUs要比等价的tanh快很多,因为tanh 或 sigmoid这些饱和的非线性函数在计算梯度的时候都要比非饱和的现行函数f(x)=max(0,x)f(x) = max(0, x)f(x)=max(0,x)慢很多。
2、Dropout
2.1.1 Dropout技术最早于2012年Hinton文章《ImageNet Classification with Deep Convolutional Neural Networks》中提出,在这篇文章中,Dropout技术确实提升了模型的性能,一般是添加到卷积神经网络模型的全连接层中;对于其它区域,我们不应该使用Dropout这项技术。
2.1.2 为什么Dropout不应在卷积层使用?
首先,在对卷积层进行正则化时,Dropout通常不太有效;原因在于卷积层具有很少的参数,因此初始时他们需要较少的正则化操作。此外,由于特征映射的空间关系,激活值可以变得高度相关,这使得Dropout无效。
3、批量标准化Batch Normalization
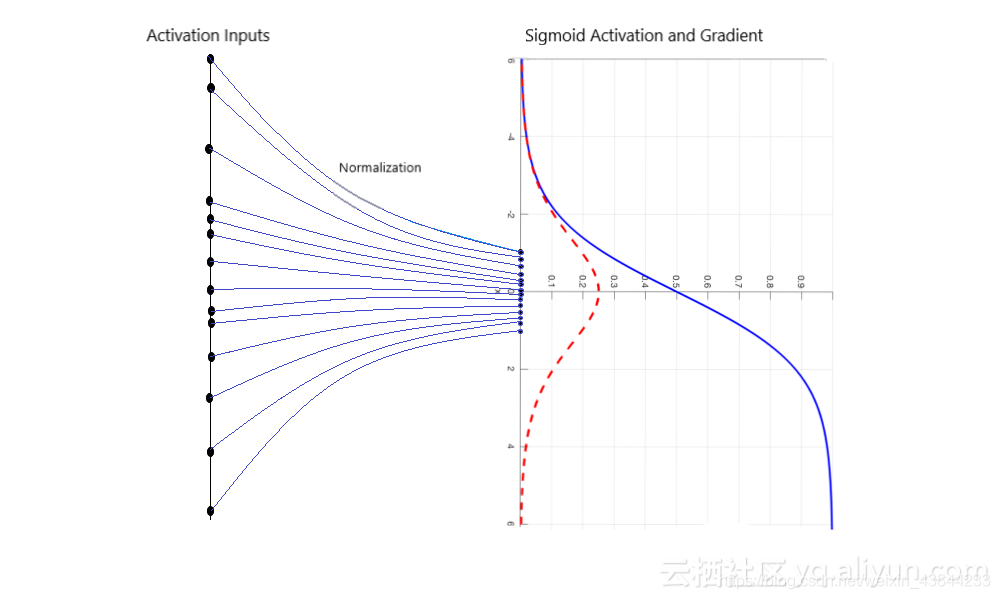
3.1.1 优点:除了具有正则化效果之外,批量标准化还可以使得卷积神经网络在训练期间能够抵抗梯度消失现象,这可以减少训练时间并能够获得更好的性能。如下图:
3.1.2当在构建卷积神经网络模型中应用批量标准化时:
• 在卷积层和激活层之间插入批量标准化层;
• 可以在此批量标准化层中调整一些超参数;
4、损失函数
注意事项:
- 无特殊说明,损失函数中的log实际为ln(求导方便,而非log10的简写)。
三、卷积网络中的一些疑惑点?
1、为什么深度学习图像分类的输入多是224*224?
1)一个图像分类模型,在图像中经历了下面的流程。
从输入image->卷积和池化->最后一层的feature map->全连接层->损失函数层softmax loss。
从输入到最后一个卷积特征feature map,就是进行信息抽象的过程,然后就经过全连接层/全局池化层的变换进行分类了,这个feature map的大小,可以是33,55,7*7等等
2)在这些尺寸中,如果尺寸太小,那么信息就丢失太严重,如果尺寸太大,信息的抽象层次不够高,计算量也更大,所以7*7的大小是一个最好的平衡。
另一方面,图像从大分辨率降低到小分辨率,降低倍数通常是2的指数次方,所以图像的输入一定是7*2^n。以ImageNet为代表的大多数分类数据集,图像的长宽在300分辨率左右。
解答2:所以要找一个72的指数次方,并且在300左右的,其中72的4次方=716=112,72的5次方等于732=224,7*2的6次方=448,与300最接近的就是224了。
这就是最重要的原因了,当然了对于实际的项目来说,有的不需要这么大的分辨率,比如手写数字识别MNIST就用32*32,有的要更大,比如细粒度分类。
2、为什么图像分类任务要从256*256中裁剪出224*224?
首先我们要知道crop的目标是用于做数据增强。
当我们描述一个数据集的大小,通常是以数量级来衡量,而数据增强也比例外,我们的目标是将数据集增长为原来的几个数量级以上,即扩充10,100,1000倍等。
输入为NN的大图,crop输出为MM的小图,可以实现(N-M)*(N-M)的数据集扩充倍数。对应扩充10,100,1000,10000倍,N-M约为3,10,32,100,因为最终结果图是224224,所以原图就应该是227227,234*234,256*256,324*324,很明显从256*256这个尺度进行裁剪,能够保证主体不至于太小或者太大,如前面图中红色框。
那不使用256*256使用其他的尺寸如何呢?在比赛刷榜中,经常使用多尺度模型测试,即使用不同尺度的输入图进行裁剪然后进行结果融合,笔者曾经在Place365数据集上训练过ResNet和DPN模型,下面是不同尺度的测试结果。
不同尺度的结果会有差异,但是通常都不大,因此除非模型特殊,不必太纠结与这个问题,毕竟256等于2^8,2的指数次幂,多么经典又快意。
3、深入理解卷积层,全连接层的作用意义:
链接:https://blog.csdn.net/m0_37407756/article/details/80904580
四、知识提升
1、迁移学习和预训练
链接:https://zhuanlan.zhihu.com/p/27657264
