REALM: Retrieval-Augmented Language Model Pre-Training

从ELMO、BERT和GPT到如今多种多样的预训练模型的横空出世,pre-training + fine-tune逐渐成为了NLP中建模的新范式,众多研究人员也不断的针对于Transformer和预训练做出改进,其中包括对Transformer本身结构的改进、预训练策略的调整、预训练结合多任务学习……甚至已有文章将其和视觉等其他的领域任务进行融合,同样取得了不错的效果。
本文提出了一种利用检索技术增强的预训练模型REALM,目的是希望通过中间步骤的检索任务来增强模型的学习能力,同时增强模型的可解释性。总所周知,预训练模型两个显著的特点便是:在大规模的文本数据上的无监督训练和依靠强大的算力。因此,当模型训练所依赖的数据量极大时,为了使模型更好的学习到其中的知识,一种暴力的方法便是不断的增大模型的容量和提升算力。但即便有条件可以做到这些,模型所学到的东西只是隐式的保存在模型的众多参数中,我们并不能以一种直观的方式明白模型是否真正的学到了,以及它学到了什么。
因此,本文在pre-training和fine-tune两个阶段都增加了一个知识检索(knowledge retrieval)的步骤。
- 预训练时,模型利用MLM策略进行预测MASK的区域正确的内容前,首先通过检索模型从文档集中检索相关的文档,然后利用检索结果中TOP-K文档中的内容来进行正确的预测。
- fine-tune阶段,模型同样是先从完整的文档集中进行相应的检索,最后利用检索结果来完成Open-QA任务,从而实现对于模型的fine-tune。
由于检索过程的存在,模型通过retrieve-then-predict的过程提供了一种间接且直观化的方供我们理解模型的学习过程,而且检索模型和预训练模型是共同训练的。当检索模型可以正确的检索到对应的文档时,模型就可以更好的进行预测和完成QA任务;反之如何模型利用检索的结果很好的实现了后续的任务,它就会给检索模型一个正的反馈,从而促使模型不断朝好的方向发展。
对于之前的预训练模型的pre-training和fine-tune两个阶段来说,模型的目标都是希望通过
x来预测正确的
y,即计算条件概率
p(y∣x)。其中预训练阶段的
x是被MASK策略处理后的文本,
y为MASK的部分;fine-tune阶段的
x为问题(question),
y为对应的答案(answer)
针对于Open-QA任务而言
而REALM通过retrieve-then-predict的过程将
p(y∣x)的计算分解为计算
p(z∣x)和
p(y∣x,z)两部分。首先从知识库中检索相应的文档
z,即相当于计算
p(z∣x),然后根据
x和检索结果
z来共同预测
y,即计算
p(y∣x,z)。因此,模型整体的流程可表示为:
p(y∣x)=z∈Z∑p(y∣x,z)p(z∣x)
通过上式可以看出,模型整体从判别式转换到了生成式。
如何理解生成模型和判别模型
下面从和
p(z∣x)和
p(y∣x,z)计算相对应的模型的两个关键部分:知识检索模型(neural knowledge retriever)和知识增强编码器(Knowledge-Augmented Encoder)出发来理解REALM。
在预测阶段之前,模型需要完成从完整的文档集中检索出相关的部分文档。REALM这里使用了一种简单的检索模型 – Dense Inner Product Model来完成相应的工作。首先分别将
x和文档集中的文档转换为对应的表示向量,然后通过两者的内积来计算
p(z∣x),从而找出和
x最为相关的部分文档。
p(z∣x)=∑z′expf(x,z′)expf(x,z)f(x,z)=Embedinput(x)TEmbeddoc(z)
其中
Embed input (x)=Winput BERTCLS (joinBERT (x)) Embed doc (z)=Wdoc BERT CLS ( join BERT (ztitle ,zbody ))
joinBERT(x)joinBERT(x1,x2)=[CLS]x[SEP]=[CLS]x1[SEP]x2[SEP]
当得到检索结果
z后,模型需要使用
z和
x来预测
y。由于pre-training和fine-tune阶段需要解决的任务不同,因此两阶段计算
p(y∣z,x)有所区别。
-
pre-training:这里采用和BERT一致的MLM的策略进行建模,因此模型需要预测每个被
[MASK]标记部分的内容。

具体的计算
p(y∣z,x)可表示为:
p(y∣z,x)p(yj∣z,x)=j=1∏Jxp(yj∣z,x)∝exp(wj⊤BERTMaSK(j)(joinBERT(x,zbody)))
-
fine-tune:这里解决的Open-QA任务,因此预测
y的过程相当于预测答案对应的起始索引(start index)和终止索引(end index)。

计算
p(y∣z,x)可表示为:
p(y∣z,x)hSTART(s)hEND(s)∝s∈S(z,y)∑exp(MLP([hSTART(s);hEND(s)]))=BERTSTART(s)(JoinBERT(x,zbody))=BERTEHD(s)(joinBERT(x,zbody))
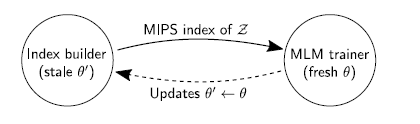
另外由于训练所使用的文档集规模巨大,在检索阶段的计算量就会特别的大。为了使模型能够顺利的跑起来,作者使用了一些机制来保证:
- 预先计算好预料库中所有文档的嵌入向量以及构建有效的索引机制
- 使用表示向量内积来对检索到的文档进行排序
- 在训练几百步后再异步的更新表示向量所对应的索引
其中索引更新过程又分为两步进行,首先进行参数的更新,然后进行索引的构建。
为了减少模型训练过程中带来的偏差,作者同样提出了几种策略来进行处理,包括:
- Salient span masking:即采用和ERNIE类似的方式,通过MASK比较重要的部分来迫使模型学习到更重要的东西

- Null document:当预测的部分不重要时,将检索结果设置为空文档
ϕ来减少计算量
- Prohibiting trivial retrievals:避免检索结果和完整文档集一致
- Initialization:采用更好的初始化方式来期望得到更好的表示向量
实验部分通过在不同的Open-QA数据集上进行实验和已有的预训练模型进行比较证明了REALM的优异性。

