NCA是Jacob Goldberger和Sam Roweis等发表于2014年的NIPS上同名文章Neighborhood Components Analysis中的工作。

之前在KNN算法的学习中提到,KNN算法两个很重要的问题表示K值的选择和距离度量方式的选择。其中K值可以通过交叉验证来看模型在验证集上的效果来启发式的选择最终的K,而距离度量通常选择的是欧式距离。通常这样的方法得到的KNN在某些数据集上可以取得不错的效果,但是欧式距离并不能很好的适用于所有类型的数据。因此,如果能自动的学习到一种距离度量不是更好嘛?NCA的提出就是为上述的问题提供了一种解决方案。
在具体了解NCA之前,我们需要明白一些包括度量学习和流形学习等基础知识。
- 度量学习(Metric Learning):又可以称为距离度量学习(Distance Metric Learning)或是相似度学习,或许最后一个更熟悉一些,因此在深度学习的各种分类问题中直观上来看就是各种样本之间相似度的比较。

source度量学习本质上做的是学习一个映射空间,使得同类的物体距离更近,而不同类物体距离更远。因此,度量学习常常和无监督近邻分类问题和维度归约问题相关
NCA是一种监督式的学习方法,同时它也是一种距离度量学习方法,其目的在于通过在训练集上学习得到一个线性空间转移矩阵,在新的转换空间中最大化平均留一分类效果。所以,算法的关键在于如何学习得到和空间转换矩阵相关的一个正定矩阵A,矩阵A可以通过定义A的一个可微的目标函数并利用迭代法求解得到。

留一分类法(leave-one-out):对一个单一的数据点进行类别预测时,我们需要考虑有一种给定的距离度量确定的K个最近邻居,根据k个近邻的类别标签投票得到该样本的类别
邻里成分分析
由于网上关于NCA的资料不多,另外我对于度量学习并不是很了解,所以就稍微写一下在看完原论文后的一些理解叭~
开章明义,作者在摘要中对于NCA的作用和原理做了清楚的介绍。NCA是一种通过在训练集上最大化留一分类随机方差的方式来学习一种用于KNN的距离度量。NCA除了用于分类问题外,它还可以用于数据的可视化和维度规约。
假设标注数据集包含
个样本向量
,样本对应的标签为
。那么在最近邻分类问题中,我们的目标是学习到一个度量来使得对新样本的分类效果最优。但是我们并不知道数据本身的真实分布,所以选择优化LOO来达到这个目的。根据前面的定义,NCA本质上也是想学到一个和转换矩阵
相关的正定阵
使得
成立,使得度量函数可写作:
而利用留一法计算误差时,误差函数关于A并不是连续的,因此文中引入一个可微的softmax函数
其中
表示为:
在随机选择近邻的过程中最终选择
作为近邻并继承它的类标签
的概率。那么
被正确分类的概率为
其中
表示和
同类的所有近邻。我们的目标就转为想让正确分类的点数目最大,即正确的将同类的点选择近邻的可能性最高,所以定义函数:
是可微的,最大化
是一个无约束的优化问题,因此可以像现在深度学习中优化问题一样采用共轭梯度法或是SGD进行迭代求解最优值。梯度的计算为:
通过不断的迭代优化就可以得到 的最优解。
NCA的优点在于:使用它做距离度量或是降维时没有复杂的矩阵运算,也不需要对样本空间的分布做特定的假设。
sklearn中对于使用NCA的函数sklearn.neighbors.NeighborhoodComponentsAnalysis来加强KNN的分类效果提供了一个例子,从代码中可以看出在定义的pipeline中首先使用nca,然后才用KNN进行最后的分类操作。
from sklearn.neighbors import (NeighborhoodComponentsAnalysis,
KNeighborsClassifier)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y,
stratify=y, test_size=0.7, random_state=42)
nca = NeighborhoodComponentsAnalysis(random_state=42)
knn = KNeighborsClassifier(n_neighbors=3)
nca_pipe = Pipeline([('nca', nca), ('knn', knn)])
nca_pipe.fit(X_train, y_train)
print(nca_pipe.score(X_test, y_test)) # 0.96190476...
此外,sklearn中还实现了NCA用于维度规约,它可以像LDA或是PCA一样实现降维,从下面例子的结果途中可以看出它的效果还是不错的。
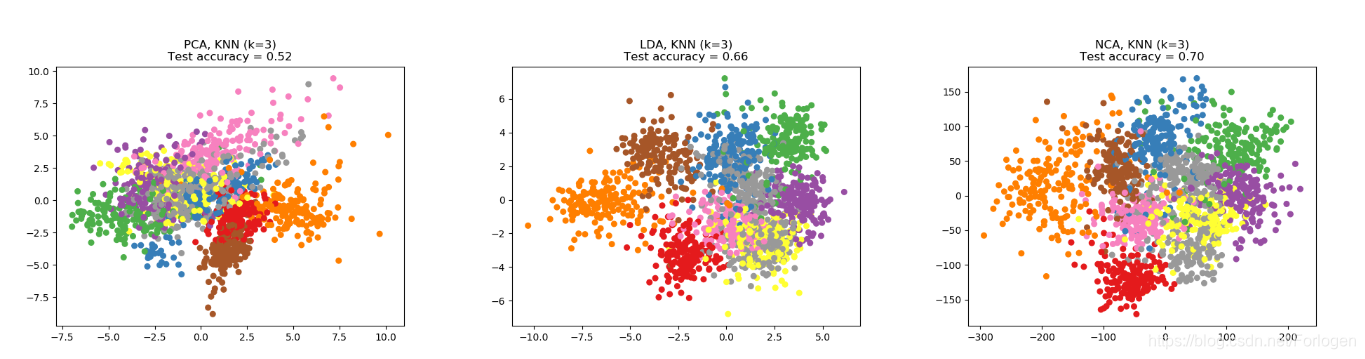
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import (KNeighborsClassifier,
NeighborhoodComponentsAnalysis)
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
print(__doc__)
n_neighbors = 3
random_state = 0
# Load Digits dataset
X, y = datasets.load_digits(return_X_y=True)
# Split into train/test
X_train, X_test, y_train, y_test = \
train_test_split(X, y, test_size=0.5, stratify=y,
random_state=random_state)
dim = len(X[0])
n_classes = len(np.unique(y))
# Reduce dimension to 2 with PCA
pca = make_pipeline(StandardScaler(),
PCA(n_components=2, random_state=random_state))
# Reduce dimension to 2 with LinearDiscriminantAnalysis
lda = make_pipeline(StandardScaler(),
LinearDiscriminantAnalysis(n_components=2))
# Reduce dimension to 2 with NeighborhoodComponentAnalysis
nca = make_pipeline(StandardScaler(),
NeighborhoodComponentsAnalysis(n_components=2,
random_state=random_state))
# Use a nearest neighbor classifier to evaluate the methods
knn = KNeighborsClassifier(n_neighbors=n_neighbors)
# Make a list of the methods to be compared
dim_reduction_methods = [('PCA', pca), ('LDA', lda), ('NCA', nca)]
# plt.figure()
for i, (name, model) in enumerate(dim_reduction_methods):
plt.figure()
# plt.subplot(1, 3, i + 1, aspect=1)
# Fit the method's model
model.fit(X_train, y_train)
# Fit a nearest neighbor classifier on the embedded training set
knn.fit(model.transform(X_train), y_train)
# Compute the nearest neighbor accuracy on the embedded test set
acc_knn = knn.score(model.transform(X_test), y_test)
# Embed the data set in 2 dimensions using the fitted model
X_embedded = model.transform(X)
# Plot the projected points and show the evaluation score
plt.scatter(X_embedded[:, 0], X_embedded[:, 1], c=y, s=30, cmap='Set1')
plt.title("{}, KNN (k={})\nTest accuracy = {:.2f}".format(name,
n_neighbors,
acc_knn))
plt.show()
