接上篇文章,使用redis sentinel cluster 实现redis replication高可用,接下来详细讲解redis哨兵集群,本节内容较多,全是干货!
4.7. redis 哨兵架构讲解
4.7.1. 认识 Sentinel
sentinel,中文名是哨兵,目前采用的是sentinel 2版本,sentinel 2相对于sentinel 1,重写了很多代码,主要是让故障转移的机制和算法变得更加健壮和简单。
在深入讲解Sentinel之前,我们先认识Sentinel的配置,对 其中的配置项先有个大概认识,方便对Sentinel原理的深入剖析。
在redis存放配置文件处,创建一个sentinel.conf配置文件,sentinel 默认端口26379,所以我们的配置文件可以取名为: sentinel-26379.conf 配置文件,文件内容如下:
port 26379
daemonize yes
logfile "26379.log"
dir "./"
sentinel monitor mymaster 192.168.250.132 7000 2
sentinel down-after-milliseconds mymaster 30000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 15000
sentinel auth-pass mymaster 123
bind 192.168.250.132 127.0.0.1
主要配置项解释:
| 序号 | 配置项 | 解释 |
|---|---|---|
| 1 | sentinel monitor | 告诉sentinel去监听地址为ip:port的一个master,这里的master-name可以自定义,quorum是一个数字,指明当有多少个sentinel认为一个master失效时,master才算真正失效。 |
| 2 | sentinel auth-pass | 设置连接master和slave时的密码,注意的是sentinel不能分别为master和slave设置不同的密码,因此master和slave的密码应该设置相同。 |
| 3 | sentinel down-after-milliseconds | 这个配置项指定了需要多少失效时间,一个master才会被这个sentinel主观地认为是不可用的。 单位是毫秒,默认为30秒。 |
| 4 | sentinel parallel-syncs | 这个配置项指定了在发生failover主备切换时,最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。 |
| 5 | sentinel failover-timeout | failover-timeout 可以用在以下这些方面: 1. 同一个sentinel对同一个master两次failover之间的间隔时间。 2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。 3.当想要取消一个正在进行的failover所需要的时间。 4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了。 |
4.7.2. 哨兵sentinel的核心原理
4.7.2.1. 哨兵sentinel的核心原理
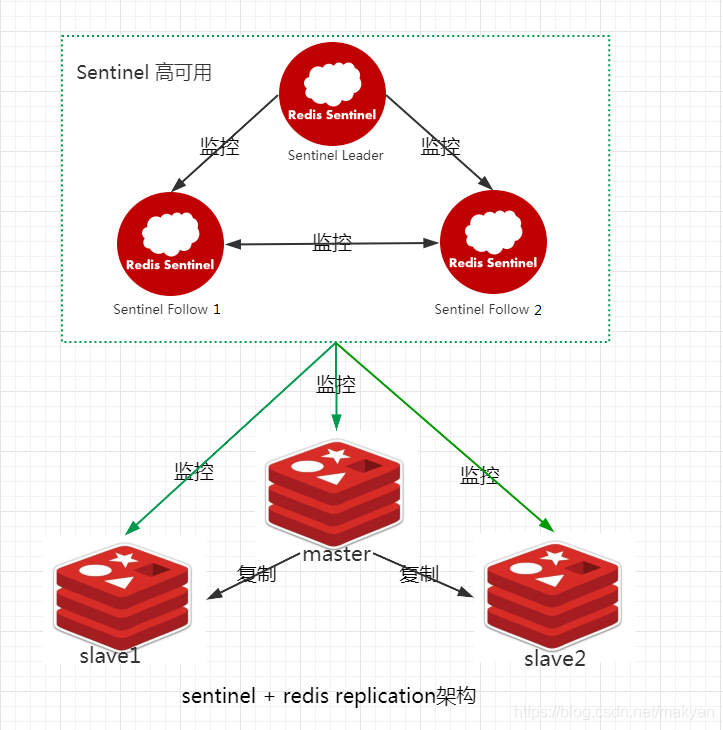
哨兵sentinel的核心原理
哨兵是redis集群架构中非常重要的一个组件,主要原理如下:
(1)哨兵本身是一个分布式集群,相互之间协同工作;
(2)集群监控:负责监控redis master和slave进程是否正常工作;
(3)消息通知:如果某个redis实例有故障,那么哨兵负责发送消息通知管理员;
(4)故障转移:如果master node挂掉了,各个哨兵自动转移到slave node上,选举一个新的master,并进行故障转移(主备切换);
(5)配置中心:如果故障转移发生了,通知client客户端新的master地址。
注意事项:
(1)故障转移时,判断一个master node是否宕机了,需要大部分的哨兵都认同master node宕机才是真的宕机,这涉及到了分布式选举的问题。
(2)即使部分哨兵节点挂掉了,哨兵集群也能正常工作。(3)哨兵至少需要3个实例,来保证自己的健壮性。
(4)sentinel + redis replication 架构,是不会保证数据零丢失的,只能保证redis集群的高可用性。
(5)sentinel + redis replication 架构,尽量在测试环境和生产环境,都进行充足的测试和演练。
4.7.2.2. Sentinel监控master整个过程
每个 `Sentinel` 节点都需要 **定期执行** 以下任务。
4.7.2.2.1. Sentinel向所知的master、slave发送PING命令
每个 `Sentinel` 以 每 `10` 秒一次的频率,向它所知的 **主服务器**、**从服务器** 以及其他 `Sentinel` **实例** 发送一个 `PING` 命令。
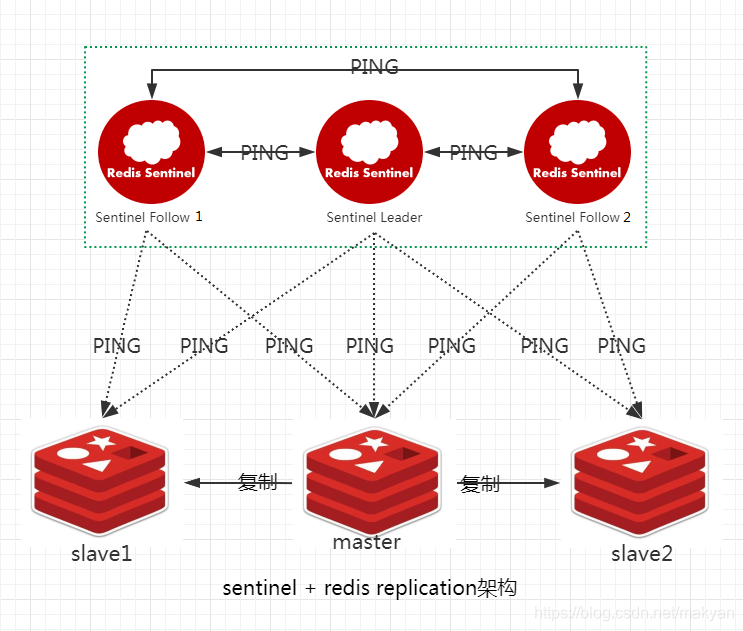
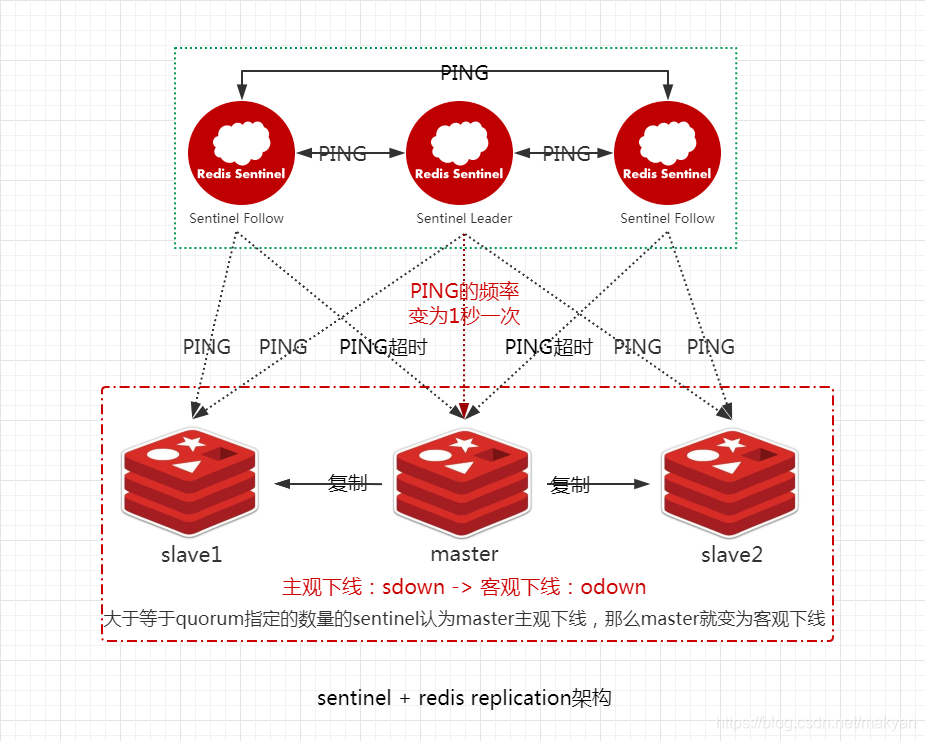
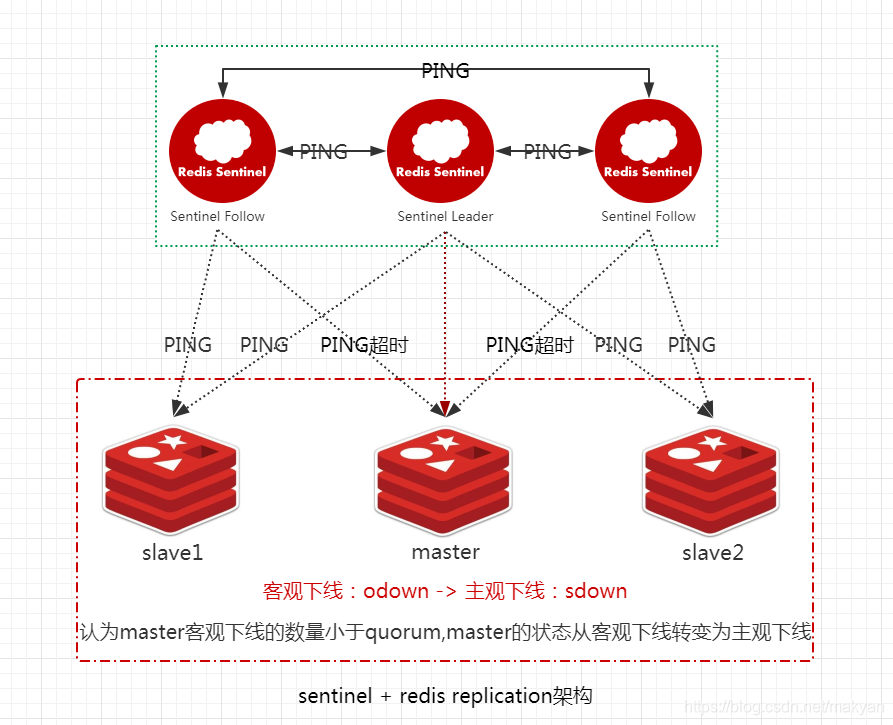
4.7.2.2.2. master转变为主观下线sdown
如果一个哨兵ping一个master,超过了down-after-milliseconds指定的毫秒数之后,那么这个哨兵就主观认为master宕机,此时master处于sdown状态。
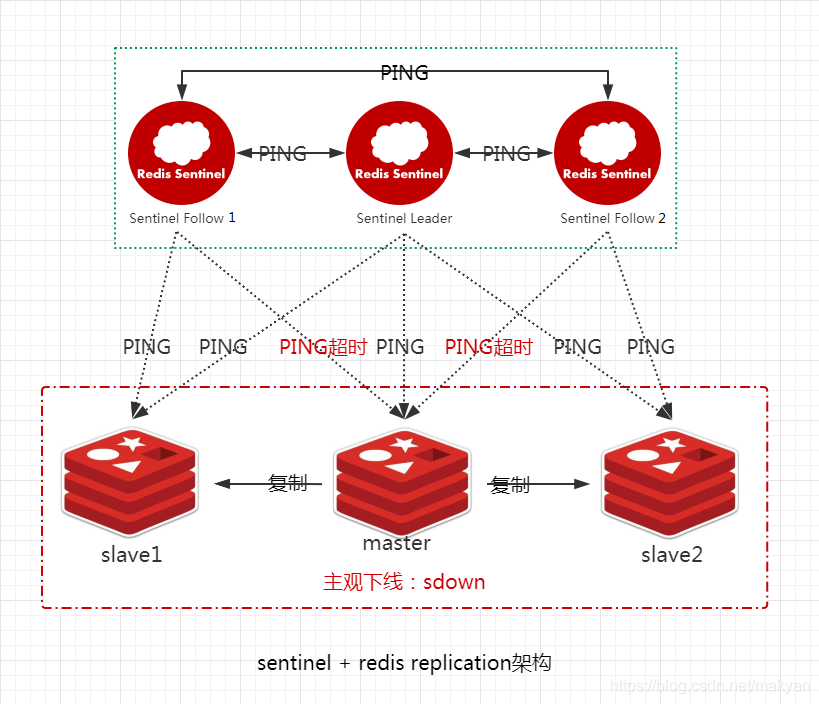
当Sentinel Follow1或Sentinel Follow2 ping master超过down-after-milliseconds指定的毫秒数之后,就认为master处于 **主观下线 **,即 **sdown **。
4.7.2.2.3. Sentinel每秒一次的频率确认master是否进入了 主观下线状态
如果一个 **master ** 被标记为 **主观下线**,那么正在 **监视** 这个 **主服务器** 的所有 `Sentinel` 节点,要以 **每秒一次** 的频率确认 **master** 的确进入了 **主观下线** 状态。
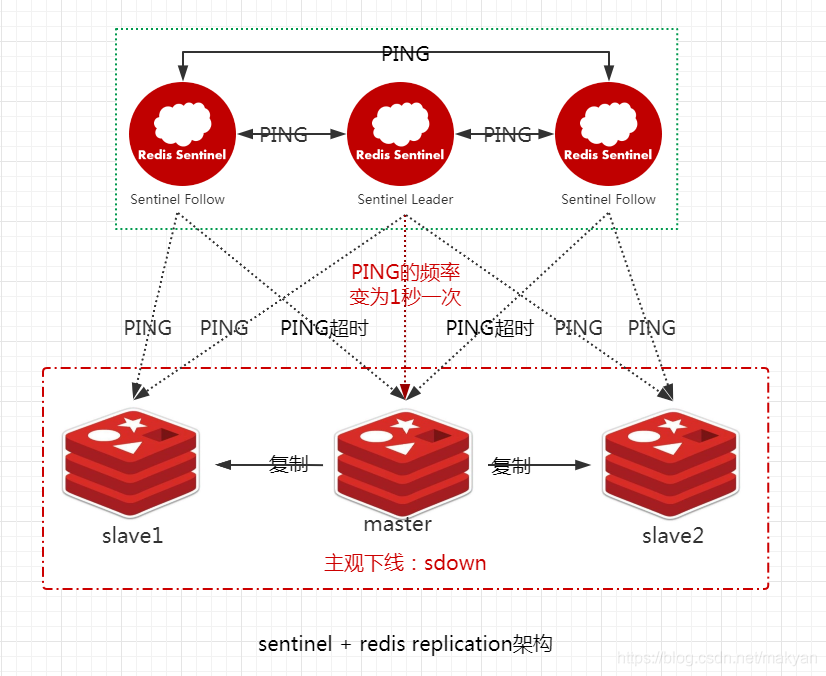
Sentinel Leader ping master的频率编程1秒一次。
4.7.2.2.4. master转变为客观下线odown
如果一个 master 被标记为 **主观下线**,并且有 **足够数量** 的 `Sentinel`(大于等于quorum指定的数量)在指定的 **时间范围** 内同意这一判断,那么这个 **master** 被标记为 **客观下线**,即**odown**。
哨兵之间的自动发现机制
这里会涉及到sentinel之间的自动发现机制,哨兵互相之间发现的实现原理:是通过redis的pub/sub系统实现的。
1、每隔两秒钟,每个哨兵都会往自己监控的某个master+slaves对应的__sentinel__:hello channel里发送一个消息,内容是自己的host、ip和runid还有对这个master的监控配置。
2、每个哨兵也会去监听自己监控的每个master+slaves对应的__sentinel__:hello channel,然后去感知到同样在监听这个master+slaves的其他哨兵的存在。
3、每个哨兵还会跟其他哨兵交换对master的监控配置,互相进行监控配置的同步。
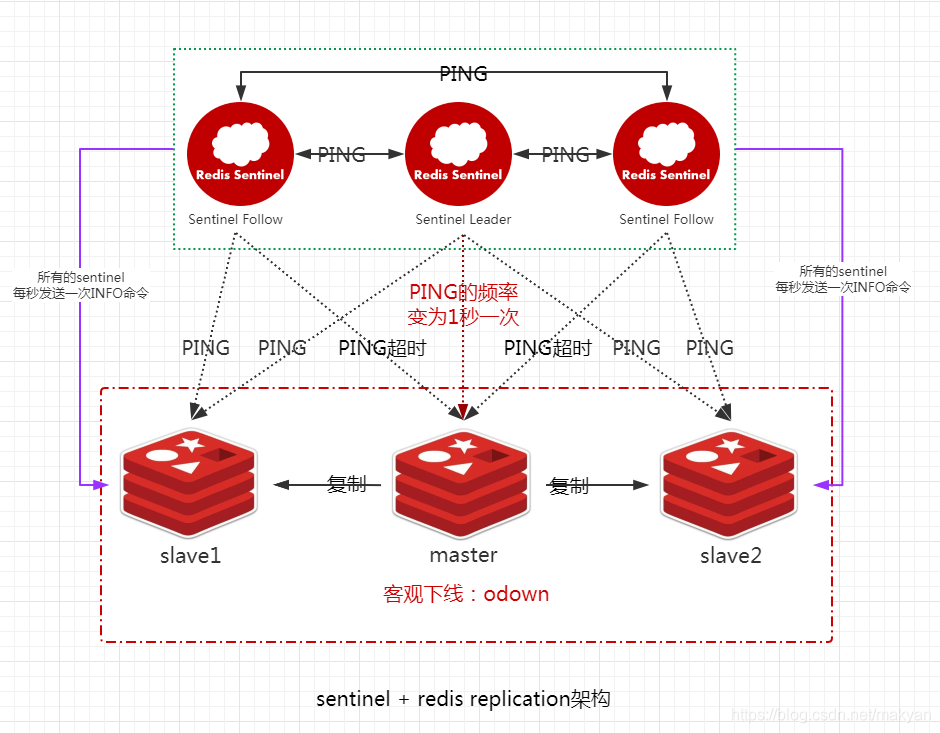
4.7.2.2.5. Sentinel向所有slave每秒一次发送INFO命令
当一个 **master** 被 `Sentinel` 标记为 **客观下线** 时,`Sentinel` 向所有 **从服务器 slave** 发送 `INFO` 命令的频率,会从`10秒一次改为每秒一次`。
4.7.2.2.6. 选举主节点master,进行主备切换
选取主节点:`Sentinel` 和其他 `Sentinel` 协商 **master** 的状态,如果 **master** 处于 `SDOWN` 状态,则投票自动选出新的 **主节点 master**。将剩余的 **从节点slave** 指向 **新的主节点** ,并进行 **数据复制**。
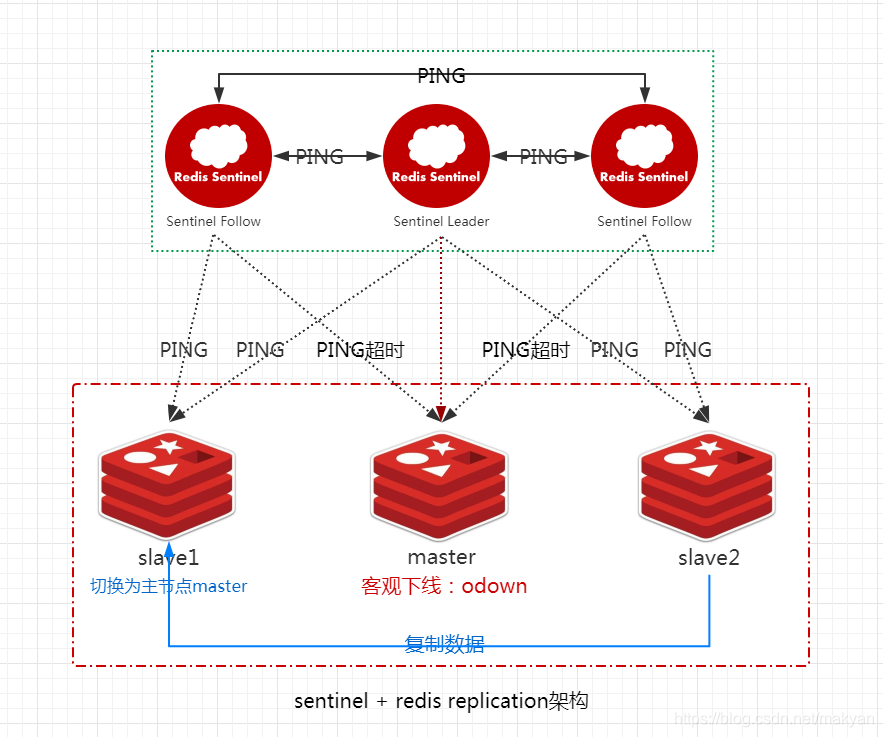
这个过程会涉及到slave配置的自动纠正,以及slave被选举为master的算法。
1、slave配置的自动纠正
哨兵会负责自动纠正slave的一些配置,比如slave如果要成为潜在的master候选人,哨兵会确保slave复制现有master的数据。如果slave连接到了一个错误的master上(故障转移之后,连接到旧的master上),那么哨兵会确保它们连接到正确的master上。
2、slave->master选举算法
如果一个master被认为odown了,而且majority哨兵都允许了主备切换,那么某个哨兵就会执行主备切换操作,此时首先要选举一个slave,选举slave通过以下信息进程选举。
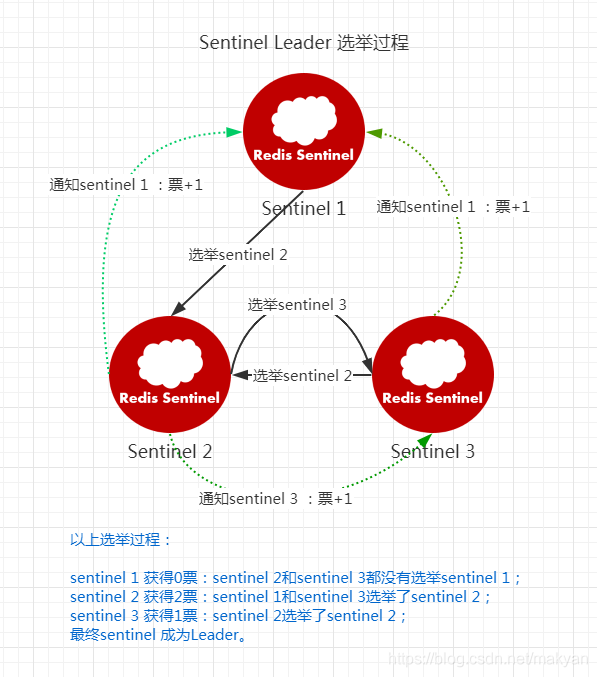
(1)Sentinel集群选举Leader
如果需要从redis集群选举一个节点为主节点,首先需要从Sentinel集群中选举一个Sentinel节点作为Leader。
每一个Sentinel节点都可以成为Leader,当一个Sentinel节点确认redis集群的主节点主观下线后,会请求其他Sentinel节点要求将自己选举为Leader。被请求的Sentinel节点如果没有同意过其他Sentinel节点的选举请求,则同意该请求(选举票数+1),否则不同意。
如果一个Sentinel节点获得的选举票数达到Leader最低票数(quorum和Sentinel节点数/2+1的最大值),则该Sentinel节点选举为Leader;否则重新进行选举。
(2)Sentinel Leader决定新主节点
当Sentinel集群选举出Sentinel Leader后,由Sentinel Leader从redis从节点中选择一个redis节点作为主节点,选举过程如下:
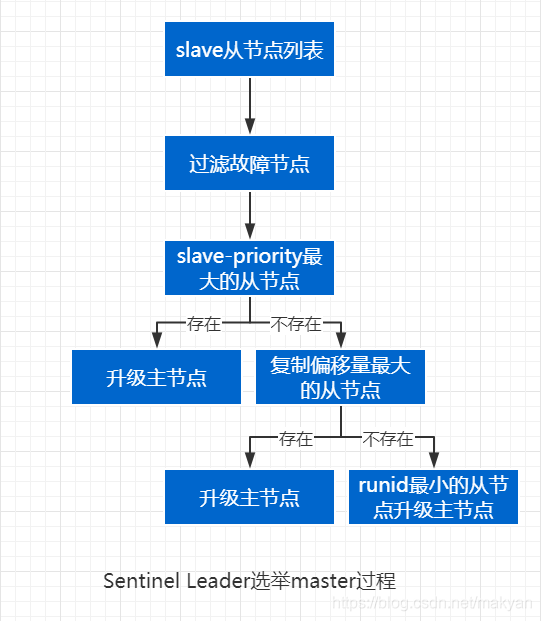
(1)跟master断开连接的时长
如果一个slave跟master断开连接已经超过了down-after-milliseconds的10倍,外加master宕机的时长,那么slave就被认为不适合选举为master。
(down-after-milliseconds * 10) + milliseconds_since_master_is_in_SDOWN_state
(2)对slave进行排序,排序方法如下:
- slave priority:选择优先级
slave-priority最大的从节点作为主节点,如不存在则继续。 按照slave优先级进行排序,slave priority越低,优先级就越高。- replica offset:选择复制偏移量(数据写入量的字节,记录写了多少数据。主服务器会把偏移量同步给从服务器,当主从的偏移量一致,则数据是完全同步)最大的从节点作为主节点,如不存在则继续。如果slave priority相同,那么看replica offset,哪个slave复制了越多的数据,offset越靠后,优先级就越高。
- run id:如果上面两个条件都相同,那么选择一个run id比较小的那个slave。(redis每次启动的时候生成随机的
runid作为redis的标识)
3、quorum和majority
quorum:quorum数量的哨兵认为master odown了,这个master才真正的odown。
majority:选举出一个哨兵切换为master,只有得到majority个哨兵的授权,才能正式执行切换。
quorum和majority的关系:
1、如果quorum < majority,比如5个哨兵,majority就是3,quorum设置为2,那么就3个哨兵授权就可以执行切换
2、但是如果quorum >= majority,那么必须quorum数量的哨兵都授权,比如5个哨兵,quorum是5,那么必须5个哨兵都同意授权,才能执行切换。
4、configuration epoch
哨兵会对一套redis master+slave进行监控,有相应的监控配置。
执行切换的那个哨兵,会从要切换到的新master(salve->master)那里得到一个configuration epoch,这就是一个version号,每次切换的version号都必须是唯一的。
如果第一个选举出的哨兵切换失败了,那么其他哨兵,会等待failover-timeout时间,然后接替继续执行切换,此时会重新获取一个新的configuration epoch,作为新的version号。
5、configuration传播
哨兵完成切换之后,会在自己本地更新生成最新的master配置,然后同步给其他的哨兵,就是通过之前说的pub/sub消息机制。
这里之前的version号就很重要了,因为各种消息都是通过一个channel去发布和监听的,所以一个哨兵完成一次新的切换之后,新的master配置是跟着新的version号的。
其他的哨兵都是根据版本号的大小来更新自己的master配置的。
4.7.2.2.7. 移除主服务器的客观下线
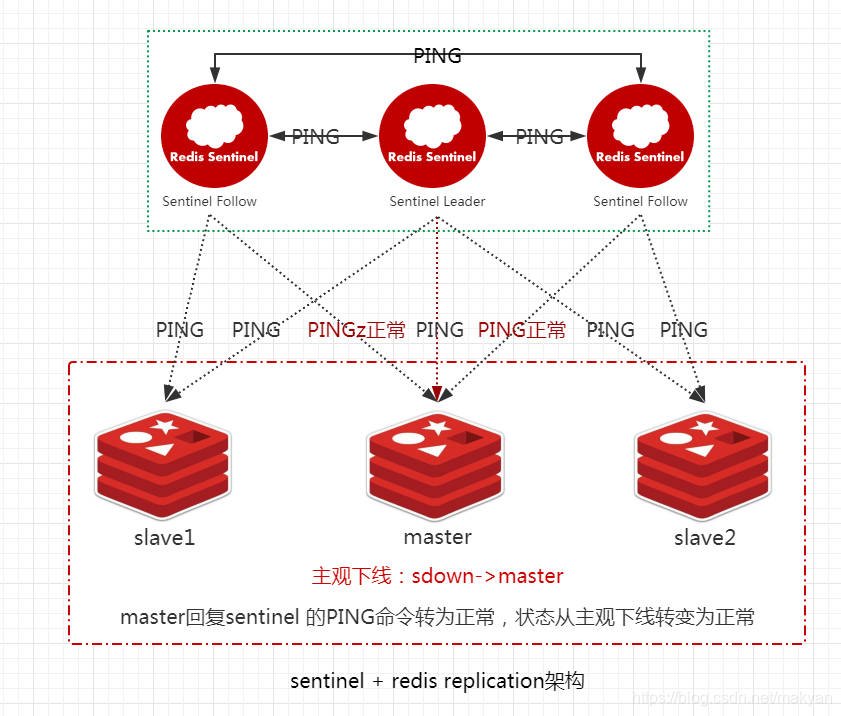
移除主服务器的客观下线。当没有足够数量的 `Sentinel` 同意 **master** 下线时, **master** 的 **客观下线状态** 就会被移除。
4.7.2.2.8. 移除主服务器的主观下线
移除主服务器的主观下线。当 **master** 重新向 `Sentinel` 的 `PING` 命令返回 **有效回复** 时,**主服务器** 的 **主观下线状态** 就会被移除。
4.7.3. 两种数据丢失的情况
主备切换的过程,可能会导致数据丢失,数据丢失主要有两种情况:
4.7.3.1. 异步复制导致的数据丢失
因为master -> slave的复制是异步的,所以可能有部分数据还没复制到slave,master就宕机了,此时这些部分数据就丢失了
4.7.3.2. 脑裂导致的数据丢失
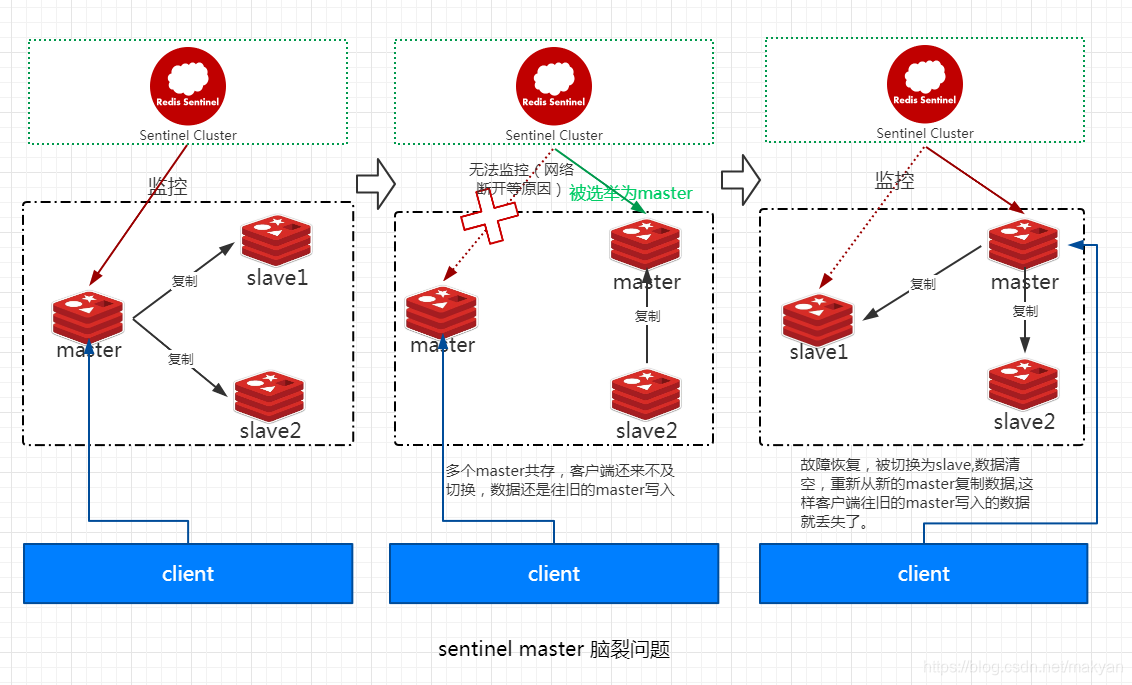
1、如上图所示,master所在机器突然脱离了正常的网络或其他原因,导致其他slave以及sentinel不能连接,但是实际上master还运行着。 2、此时哨兵可能认为master宕机了,然后开启选举,将其他slave切换成了master。这个时候,集群里就会有两个master,也就是所谓的脑裂。 3、此时虽然某个slave被切换成了master,但是可能client还没来得及切换到新的master,还继续写向旧的master。 4、当旧master再次恢复的时候,会被作为一个slave挂到新的master上去,自己的数据会清空,重新从新的master复制数据,这时写入旧的master数据就丢失了。
4.7.3.3.数据丢失解决方案
解决异步复制和脑裂导致的数据丢失。
在redis.conf配置中配置以下两个属性:

min-slaves-to-write 1
min-slaves-max-lag 10意义:要求至少有1个slave,数据复制和同步的延迟不能超过10秒
如果所有的slave数据复制和同步的延迟都超过了10秒钟,master就不会再接收任何请求。
上面两个配置可以减少异步复制和脑裂导致的数据丢失。
配置 这两个参数后,一旦slave从master复制数据和ack延时太长,不能继续给指定数量的slave发送数据,就直接拒绝客户端的写请求,这样脑裂后的旧master就不会接受client的新数据,也就避免了数据丢失,这样就可以把master宕机时由于部分数据未同步到slave导致的数据丢失降低到可控范围内。
因此在脑裂和异步复制的场景下,最多就丢失10秒的数据。
