Scrapy添加代理爬取boss直聘,并存储到mongodb
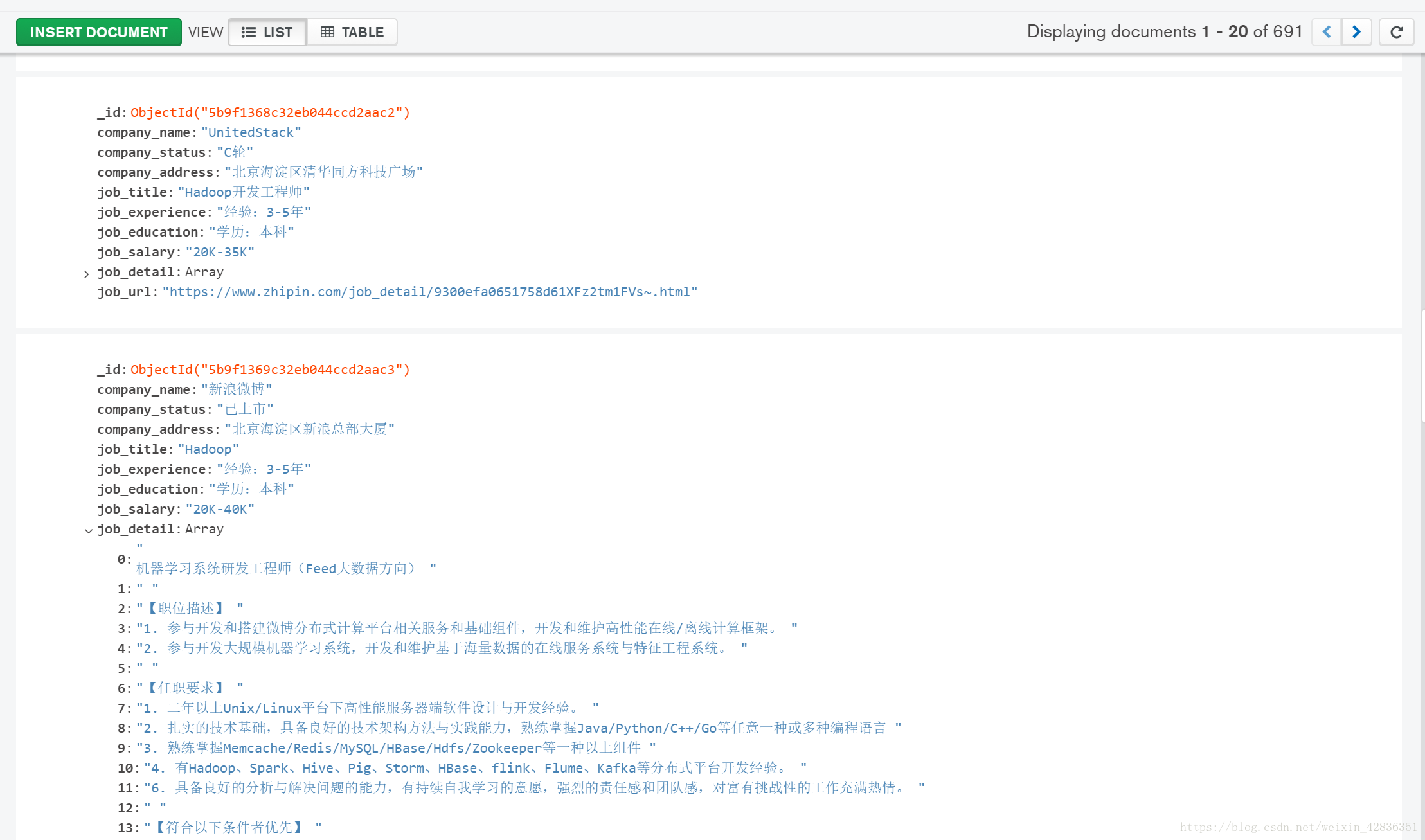
最终爬取截图
项目创建
本项目使用的是Windows系统下的Pycharm平台,Python版本为3.6
使用scrapy startproject scrapy_boss创建scrapy项目
items
from scrapy import Item, Field
class BossItem(Item):
company_name = Field() #公司名称
company_status = Field() #公司规模
company_address = Field() #公司地址
job_title = Field() #职位名称
job_salary = Field() #薪酬
job_detail = Field() #职位描述、详情要求
job_experience = Field() #工作经验
job_education = Field() #学历要求
job_url = Field() #发布页面
Spider
- 参数
class BossSpider(Spider):
name = 'boss'
allowed_domains = ['www.zhipin.com']
# start_urls = ['http://www.zhipin.com/']
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': '__c=1535347437; __g=-; __l=l=%2Fwww.zhipin.com%2Fc101010100%2Fh_101010100%2F%3Fquery%3D%25E7%2588%25AC%25E8%2599%25AB%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588%26page%3D4%26ka%3Dpage-4&r=; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1533949950,1534555474,1535095432,1535347437; lastCity=101010100; toUrl=https%3A%2F%2Fwww.zhipin.com%2Fjob_detail%2F%3Fquery%3Dpython%26scity%3D101010100%26industry%3D%26position%3D; JSESSIONID=""; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1535348378; __a=5534803.1512627994.1535095432.1535347437.264.8.4.260',
'referer': 'https://www.zhipin.com/job_detail/?query=python&scity=101010100&industry=&position=',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
- 解析index页
def start_requests(self):
queries = ['hadoop', 'spark', 'hbase', 'hive', r'大数据',
r'数据分析', r'数据运营', r'数据挖掘', r'爬虫', r'抓取', r'可视化', r'数据开发', r'数据工程',
r'数据处理', r'数据科学家', r'数据工程师', r'数据架构师', r'数据采集', r'数据建模', r'数据平台',
r'数据研发', r'数据管理', r'数据统计', r'数据产品', r'数据方向', r'数据仓库', r'数据研究',
r'数据算法', r'数据蜘蛛', r'数据应用', r'数据技术', r'数据运维', r'数据支撑', r'数据安全',
r'数据爬取', r'数据经理', r'金融数据', r'数据专员', r'数据主管', r'数据项目经理', r'数据整合',
r'数据模型', r'财务数据', r'数据专家', r'数据报送', r'数据中心', r'数据移动', r'数据标准',
r'数据推广', r'数据质量', r'数据检索', r'数据服务', r'数据搭建', r'数据实施', r'数据风控']
urls = []
for query in queries:
url = 'https://www.zhipin.com/job_detail/?query=%s&scity=101010100'%query
urls.append(url)
for url in urls:
yield Request(url=url, headers=self.headers, callback=self.parse_index)
- 解析index页面构造url,并实现翻页
def parse_index(self, response):
sel = Selector(response)
url_prefix = 'https://www.zhipin.com'
job_urls = sel.xpath('//a[@data-index]/@href').extract()
for job_url in job_urls:
url = url_prefix + job_url
yield Request(url=url,headers=self.headers, callback=self.parse_detail)
next_page_url = sel.xpath('//a[@class="next"]/@href').extract()
if len(next_page_url) != 0:
next_page_url = url_prefix + ''.join(next_page_url)
yield Request(url=next_page_url, headers=self.headers, callback=self.parse_index)
- 解析详情页
def parse_detail(self,response):
item = BossItem()
item['company_name'] = response.xpath('//a[@ka="job-detail-company"]/text()').extract_first()
item['company_status'] = response.xpath('//div[@class="info-company"]/p[1]/text()[1]').extract_first()
item['company_address'] = response.xpath('//div[@class="location-address"]/text()').extract_first()
item['job_title'] = response.xpath('//div[@class="name"]/h1/text()').extract_first()
item['job_experience'] = response.xpath('//div[@class="job-primary detail-box"]/div[@class="info-primary"]/p/text()[2]').extract_first()
item['job_education'] = response.xpath('//div[@class="job-primary detail-box"]/div[@class="info-primary"]/p/text()[3]').extract_first()
item['job_salary'] = response.xpath('//span[@class="badge"]/text()').extract_first().replace("\n", "").strip()
item['job_detail'] = response.xpath('//div[@class="job-sec"]/div[@class="text"]/text()').extract()
item['job_url'] = response.url
yield item
Middleware添加ip代理
此处借助了一个IP池,在本地提供了一个随机提取可用代理的端口。
class ProxyMiddleware(object):
def process_request(self,request,spider):
response = requests.get('http://localhost:5555/random')
proxy = response.text
request.meta['proxy'] = "http://"+proxy
- settings
需要在settings中打开DownloaderMiddleware
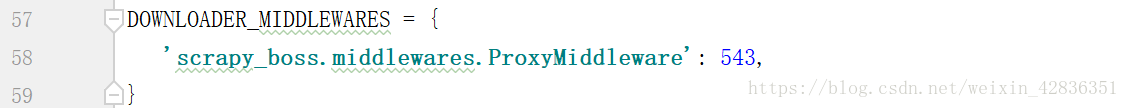
Pipeline添加mongodb存储
import pymongo
class scrapy_bossPipeline(object):
def process_item(self, item, spider):
return item
class MongoPipeline(object):
def __init__(self,mongo_uri,mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_uri = crawler.settings.get('MONGO_URI'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self,item,spider):
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item
- settings:
需要在settings中添加
SPIDER_MODULES = ['scrapy_boss.spiders']
NEWSPIDER_MODULE = 'scrapy_boss.spiders'
MONGO_URI = 'localhost'
MONGO_DB = 'scrapy_boss'
并打开itemspipeline
