1.操作系统是怎么组织进程的?
1.1什么是线程,什么是进程:
刚接触时可能经常会将这两个东西搞混。简单一点的说,进程是一个大工程,线程则是这个大工程中每个小地方需要做的东西(在linux下看作"轻量级进程"):
例如当你打开QQ微信,这时系统启动了一个进程。然后你开始看别人发的消息,这时启动了一个线程用来传输文本,如果发了一段语音,这也会启动一个线程来传输语音......(当然一个程序并不代表一定只有一个进程)
1.2进程内核栈与thread_info(用于存储进、线程及其信息等):
1 struct task_struct { 2 ...... 3 4 /* 指向进程内核栈 */ 5 void *stack; 6 7 ...... 8 };
1 union thread_union { 2 struct thread_info thread_info; 3 unsigned long stack[THREAD_SIZE/sizeof(long)]; /*内核态的进程堆栈*/ 4 };
1 /*线程描述符(linux4.5 x86架构)*/ 2 /*typedef unsigned int __u32*/ 3 struct thread_info { 4 struct task_struct *task; /* 存储进(线)程的信息 */ 5 __u32 flags; /* 进程标记 */ 6 __u32 status; /* 线程状态 */ 7 __u32 cpu; /* current CPU */ 8 mm_segment_t addr_limit; 9 unsigned int sig_on_uaccess_error:1; 10 unsigned int uaccess_err:1; /* uaccess failed */ 11 };
- 进程在内核态运行时需要自己的堆栈信息, 因此linux内核为每个进程都提供了一个内核栈kernel stack;
- 内核还需要存储每个进程的PCB信息, linux内核是支持不同体系的的, 但是不同的体系结构可能进程需要存储的信息不尽相同, 这就需要我们实现一种通用的方式, 我们将体系结构相关的部分和无关的部门进行分离;
-
linux将内核栈和thread_info融合在一起, 组成一个联合体thread_union。(下图左块)

由上图(左大块为"进程内核栈", 右块为"进程描述符")所示,进程的内核栈是向下增长的,也就是栈底在高位地址,栈顶在低位地址,thread_info在进程内核栈的最低处。其中可总结出:
- esp寄存器为CPU栈指针,用来存放栈顶单元的地址。当数据写入时,esp的值减少;
- thread_info和内核栈虽然共用了thread_union结构, 但是thread_info大小固定, 存储在联合体的开始部分, 而内核栈由高地址向低地址扩展, 当内核栈的栈顶到达thread_info的存储空间时, 则会发生栈溢出(内核中有kstack_end函数判断);
- 系统的current指针指向了当前运行进程的thread_union(或者thread_info)的地址;
其中在早期的Linux内核中使用struct thread_info *thread_info,而之后的新版本(2.6.22后)中用进程task_struct中的stack指针指向了进程的thread_union(或者thread_info)的地址来代替thread_info指针,因为联合体中stack和thread_info都在起始地址, 因此可以很方便的转型:
#define task_thread_info(task) ((struct thread_info *)(task)->stack)
1.3进程标示符PID:
struct task_struct { ........ /* 进程ID,每个进程(线程)的PID都不同 */ pid_t pid; /* 线程组ID,同一个线程组拥有相同的pid,与领头线程(该组中第一个轻量级进程)pid一致,保存在tgid中,线程组领头线程的pid和tgid相同 */ pid_t tgid; /* 用于连接到PID、TGID、PGRP、SESSION哈希表 */ struct pid_link pids[PIDTYPE_MAX]; /*PID : 进程的ID(Process Identifier),对应pids[PIDTYPE_PID] *TGID : 线程组ID(Thread Group Identifier),对应pids[PIDTYPE_TGID] *PGRP : 进程组(Process Group),对应pids[PIDTYPE_PGID] *SESSION : 会话(Session),对应pids[PIDTYPE_SID] */ ........ };
PID就像我们学生的学号,每个人的身份证号一样,是独一无二的。而我们会有一个群体,比如同一个班级,同一个学校等,即有同一个组群,因此建立了TGID,用来将同一个组的PID串联起来。其中getpid()返回当前进程的tgid值而不是pid的值。
而在系统运行的时候,可能会建立非常非常多的进程,因此为了提高内核的查找效率,专门建立了四个hash表pids[PIDTYPE_TGID]、pids[PIDTYPE_TGID]、pids[PIDTYPE_PGID]、pids[PIDTYPE_SID]用来索引。
在内核中,这四个哈希表一共占16个页框,也就是每个哈希表占4个页框,他们每个可以拥有2048个表项,内核会把把这四个哈希表的地址保存到pid_hash数组中。现在问题来了,拿pids[PIDTYPE_TGID]为例,怎么在2048个表项中保存32767个PID值,其实内核会对每个已经分配的PID值进行一个处理,得到的结果的数值就是对应的表项,处理结果相同的PID被串成一个链表,如下:
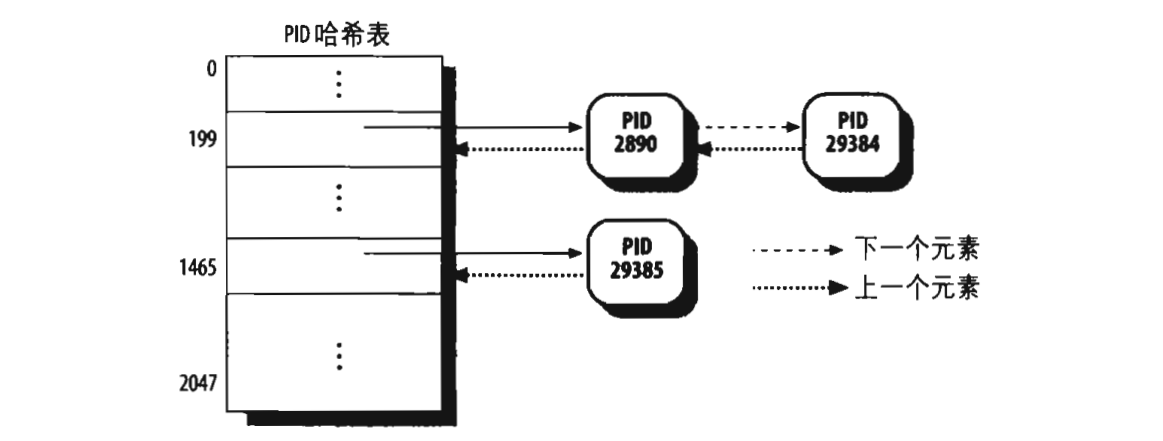
当我们使用"kill 29384"命令时,内核会根据29384处理得出199,然后以199为下标,获取PID哈希表中对应的链表头,并在此链表中找出PID=29384的进程。在进程描述符(thread_info)的*task中使用struct pid_link pids[PIDTYPE_MAX]链入这四个哈希表。对于另外三个哈希表,道理一样。
1.4进程状态的转换:
进程的状态用state表示,简单表示有以下3种:
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
其中详细有以下状态:
1 /* 2 * Task state bitmask. NOTE! These bits are also 3 * encoded in fs/proc/array.c: get_task_state(). 4 * 5 * We have two separate sets of flags: task->state 6 * is about runnability, while task->exit_state are 7 * about the task exiting. Confusing, but this way 8 * modifying one set can't modify the other one by 9 * mistake. 10 */ 11 #define TASK_RUNNING 0 12 #define TASK_INTERRUPTIBLE 1 13 #define TASK_UNINTERRUPTIBLE 2 14 #define __TASK_STOPPED 4 15 #define __TASK_TRACED 8 16 17 /* in tsk->exit_state */ 18 #define EXIT_DEAD 16 19 #define EXIT_ZOMBIE 32 20 #define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD) 21 22 /* in tsk->state again */ 23 #define TASK_DEAD 64 24 #define TASK_WAKEKILL 128 /** wake on signals that are deadly **/ 25 #define TASK_WAKING 256 26 #define TASK_PARKED 512 27 #define TASK_NOLOAD 1024 28 #define TASK_STATE_MAX 2048 29 30 /* Convenience macros for the sake of set_task_state */ 31 #define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE) 32 #define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED) 33 #define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED)
1.4.1五种互斥状态:
state域能够取5个互为排斥的值(简单来说就是这五个值任意两个不能一起使用,只能单独使用):
| 状态 | 描述 |
| TASK_RUNNING | 表示进程要么正在执行,要么正要准备执行(已经就绪),正在等待cpu时间片的调度 |
| TASK_INTERRUPTIBLE | 进程因为等待一些条件而被挂起(阻塞)而所处的状态。这些条件主要包括:硬中断、资源、一些信号……,一旦等待的条件成立,进程就会从该状态(阻塞)迅速转化成为就绪状态TASK_RUNNING |
| TASK_UNINTERRUPTIBLE | 意义与TASK_INTERRUPTIBLE类似,除了不能通过接受一个信号来唤醒以外,对于处于TASK_UNINTERRUPIBLE状态的进程,哪怕我们传递一个信号或者有一个外部中断都不能唤醒他们。只有它所等待的资源可用的时候,他才会被唤醒。这个标志很少用,但是并不代表没有任何用处,其实他的作用非常大,特别是对于驱动刺探相关的硬件过程很重要,这个刺探过程不能被一些其他的东西给中断,否则就会让进城进入不可预测的状态 |
| TASK_STOPPED | 进程被停止执行,当进程接收到SIGSTOP、SIGTTIN、SIGTSTP或者SIGTTOU信号之后就会进入该状态 |
| TASK_TRACED | 表示进程被debugger等进程监视,进程执行被调试程序所停止,当一个进程被另外的进程所监视,每一个信号都会让进城进入该状态 |
1.4.2二种终止状态:
这两个附加的进程状态既可以被添加到state域中,又可以被添加到exit_state域中。只有当进程终止的时候,才会达到这两种状态:
| 状态 | 描述 |
| EXIT_ZOMBIE | 进程的执行被终止,但是其父进程还没有使用wait()等系统调用来获知它的终止信息,此时进程成为僵尸进程 |
| EXIT_DEAD | 进程的最终状态 |
1.4.3睡眠状态:
正常只需将state域的值设为以下两种状态就可进入睡眠状态:
| 状态 | 描述 |
| TASK_INTERRUPTIBLE | 进程处于睡眠状态,正在等待某些事件发生。进程可以被信号中断。接收到信号或被显式的唤醒呼叫唤醒之后,进程将转变为 TASK_RUNNING 状态。 |
| TASK_UNINTERRUPTIBLE | 此进程状态类似于 TASK_INTERRUPTIBLE,只是它不会处理信号。中断处于这种状态的进程是不合适的,因为它可能正在完成某些重要的任务。 当它所等待的事件发生时,进程将被显式的唤醒呼叫唤醒。 |
而在Linux2.6.25以后,新增了一条睡眠状态 : “TASK_KILLABLE”:
| 状态 | 描述 |
| TASK_KILLABLE | 当进程处于这种可以终止的新睡眠状态中,它的运行原理类似于 TASK_UNINTERRUPTIBLE,只不过可以响应致命信号。 |
由代码的line 31可以看出,TASK_UNINTERRUPTIBLE + TASK_WAKEKILL = TASK_KILLABLE。
1.4.4进程转换图:
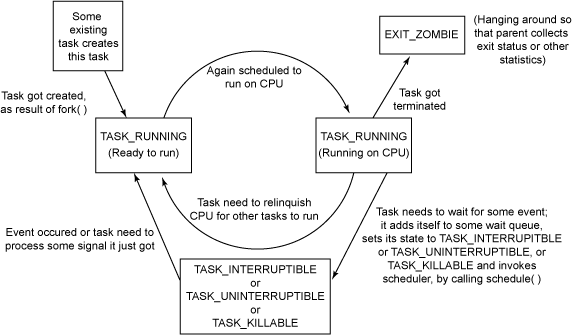
因此,通过对以上数据的操作,操作系统便可以对进程进行组织和管理。
2.进程是怎么被调度的?
2.1什么是调度器?
一台个人电脑,最直观的资源便是你的硬盘、磁盘、内存等等,但其实CPU也是一个资源,每个程序在跑的时候都需要占用CPU一定时间。因此,如何让每个程序合理、公平地跑一定的时间,是一个很重要的问题,需要设计一个专门的地方去分配,这就是调度器。调度器的一个重要目标是有效地分配 CPU 时间片,同时提供很好的用户体验。调度器还需要面对一些互相冲突的目标,例如既要为关键实时任务最小化响应时间, 又要最大限度地提高 CPU 的总体利用率。
2.2进程的分类.
当涉及有关调度的问题时, 传统上把进程分类为”I/O受限(I/O-dound)”或”CPU受限(CPU-bound)”.
| 类型 | 别称 | 描述 | 示例 |
| I/O受限型 | I/O密集型 | 频繁的使用I/O设备, 并花费很多时间等待I/O操作的完成 | 数据库服务器, 文本编辑器 |
| CPU受限型 | 计算密集型 | 花费大量CPU时间进行数值计算 | 图形绘制程序 |
另外一种分类法把进程区分为三类:
| 类型 | 描述 | 示例 |
| 交互式进程(interactive process) | 此类进程经常与用户进行交互, 因此需要花费很多时间等待键盘和鼠标操作. 当接受了用户的输入后, 进程必须很快被唤醒, 否则用户会感觉系统反应迟钝 | shell, 文本编辑程序和图形应用程序 |
| 批处理进程(batch process) | 此类进程不必与用户交互, 因此经常在后台运行. 因为这样的进程不必很快相应, 因此常受到调度程序的怠慢 | 程序语言的编译程序, 数据库搜索引擎以及科学计算 |
| 实时进程(real-time process) | 这些进程由很强的调度需要, 这样的进程绝不会被低优先级的进程阻塞. 并且他们的响应时间要尽可能的短 | 视频音频应用程序, 机器人控制程序以及从物理传感器上收集数据的程序 |
2.3调度器的演变.
一开始的调度器是复杂度为O(n)的始调度算法(实际上每次会遍历所有任务,所以复杂度为O(n)), 这个算法的缺点是当内核中有很多任务时,调度器本身就会耗费不少时间,所以,从linux2.5开始引入赫赫有名的O(1)调度器。然而,linux是集全球很多程序员的聪明才智而发展起来的超级内核,没有最好,只有更好,在O(1)调度器风光了没几天就又被另一个更优秀的调度器取代了,它就是CFS调度器(Completely Fair Scheduler). 这个也是在2.6内核中引入的,具体为2.6.23,即从此版本开始,内核使用CFS作为它的默认调度器,O(1)调度器被抛弃了, 其实CFS的发展也是经历了很多阶段,最早期的楼梯算法(SD), 后来逐步对SD算法进行改进出RSDL(Rotating Staircase Deadline Scheduler), 这个算法已经是”完全公平”的雏形了, 直至CFS是最终被内核采纳的调度器, 它从RSDL/SD中吸取了完全公平的思想,不再跟踪进程的睡眠时间,也不再企图区分交互式进程。它将所有的进程都统一对待,这就是公平的含义。CFS的算法和实现都相当简单,众多的测试表明其性能也非常优越。
| 调度器 | Linux版本 |
| O(n)的始调度算法 | linux-0.11~2.4 |
| O(1)调度器 | linux-2.5 |
| CFS调度器 | linux-2.6~至今 |
2.4调度器的设计.
Linux的2种调度器:
| 调度器 | 描述 |
| 主调度器 | 直接根据进程的状态进行调度,比如当其打算睡眠或出于其他原因放弃占用CPU时 |
| 周期调度器 | 通过周期性的机制, 以固定的频率运行, 不时地去检测是否有必要进行调度 |
其中这两者统称为通用调度器(generic scheduler)或核心调度器(core scheduler)。
每个调度器包括两个内容:调度框架(其实质就是两个函数框架)及调度器类。
Linux的6种调度策略:
| 调度策略 | 描述 | 所在调度器类 |
| SCHED_NORMAL | (也叫SCHED_OTHER)用于普通进程,通过CFS调度器实现。SCHED_BATCH用于非交互的处理器消耗型进程。SCHED_IDLE是在系统负载很低时使用 | CFS |
| SCHED_BATCH | SCHED_NORMAL普通进程策略的分化版本。采用分时策略,根据动态优先级(可用nice()API设置),分配CPU运算资源。注意:这类进程比上述两类实时进程优先级低,换言之,在有实时进程存在时,实时进程优先调度。但针对吞吐量优化, 除了不能抢占外与常规任务一样,允许任务运行更长时间,更好地使用高速缓存,适合于成批处理的工作 | CFS |
| SCHED_IDLE | 优先级最低,在系统空闲时才跑这类进程(如利用闲散计算机资源跑地外文明搜索,蛋白质结构分析等任务,是此调度策略的适用者) | CFS-IDLE |
| SCHED_FIFO | 先入先出调度算法(实时调度策略),相同优先级的任务先到先服务,高优先级的任务可以抢占低优先级的任务 | RT |
| SCHED_RR | 轮流调度算法(实时调度策略),后者提供 Roound-Robin 语义,采用时间片,相同优先级的任务当用完时间片会被放到队列尾部,以保证公平性,同样,高优先级的任务可以抢占低优先级的任务。不同要求的实时任务可以根据需要用sched_setscheduler() API设置策略 | RT |
| SCHED_DEADLINE | 新支持的实时进程调度策略,针对突发型计算,且对延迟和完成时间高度敏感的任务适用。基于Earliest Deadline First (EDF) 调度算法 | DL |
Linux的5种调度类:
| 调度器类 | 描述 | 对应调度策略 |
| stop_sched_class | 优先级最高的线程,会中断所有其他线程,且不会被其他任务打断作用 1.发生在cpu_stop_cpu_callback 进行cpu之间任务migration 2.HOTPLUG_CPU的情况下关闭任务 |
无, 不需要调度普通进程 |
| dl_sched_class | 采用EDF最早截至时间优先算法调度实时进程 | SCHED_DEADLINE |
| rt_sched_class | 采用提供 Roound-Robin算法或者FIFO算法调度实时进程 具体调度策略由进程的task_struct->policy指定 |
SCHED_FIFO, SCHED_RR |
| fair_sched_clas | 采用CFS算法调度普通的非实时进程 | SCHED_NORMAL, SCHED_BATCH |
| idle_sched_class | 采用CFS算法调度idle进程, 每个cup的第一个pid=0线程:swapper,是一个静态线程。调度类属于:idel_sched_class,所以在ps里面是看不到的。一般运行在开机过程和cpu异常的时候做dump | SCHED_IDLE |
其所属进程的优先级顺序为:
stop_sched_class -> dl_sched_class -> rt_sched_class -> fair_sched_class -> idle_sched_class
Linux的3种调度实体:
调度器不限于调度进程, 还可以调度更大的实体, 比如实现组调度: 可用的CPUI时间首先在一半的进程组(比如, 所有进程按照所有者分组)之间分配, 接下来分配的时间再在组内进行二次分配,这种一般性要求调度器不直接操作进程, 而是处理可调度实体, 因此需要一个通用的数据结构描述这个调度实体,即seched_entity结构, 其实际上就代表了一个调度对象,可以为一个进程,也可以为一个进程组。linux中针对当前可调度的实时和非实时进程, 定义了类型为seched_entity的3个调度实体:
| 调度实体 | 名称 | 描述 | 对应调度器类 |
| sched_dl_entity | DEADLINE调度实体 | 采用EDF算法调度的实时调度实体 | dl_sched_class |
| sched_rt_entity | RT调度实体 | 采用Roound-Robin或者FIFO算法调度的实时调度实体 | rt_sched_class |
| sched_entity | CFS调度实体 | 采用CFS算法调度的普通非实时进程的调度实体 | fair_sched_class |
2.5CFS调度器.
CFS完全公平调度器的调度器类叫fair_sched_class,下面是linux 4.5中的数据结构:
1 /* 2 * All the scheduling class methods: 3 */ 4 const struct sched_class fair_sched_class = { 5 .next = &idle_sched_class, 6 .enqueue_task = enqueue_task_fair, 7 .dequeue_task = dequeue_task_fair, 8 .yield_task = yield_task_fair, 9 .yield_to_task = yield_to_task_fair, 10 11 .check_preempt_curr = check_preempt_wakeup, 12 13 .pick_next_task = pick_next_task_fair, 14 .put_prev_task = put_prev_task_fair, 15 16 #ifdef CONFIG_SMP 17 .select_task_rq = select_task_rq_fair, 18 .migrate_task_rq = migrate_task_rq_fair, 19 20 .rq_online = rq_online_fair, 21 .rq_offline = rq_offline_fair, 22 23 .task_waking = task_waking_fair, 24 .task_dead = task_dead_fair, 25 .set_cpus_allowed = set_cpus_allowed_common, 26 #endif 27 28 .set_curr_task = set_curr_task_fair, 29 .task_tick = task_tick_fair, 30 .task_fork = task_fork_fair, 31 32 .prio_changed = prio_changed_fair, 33 .switched_from = switched_from_fair, 34 .switched_to = switched_to_fair, 35 36 .get_rr_interval = get_rr_interval_fair, 37 38 .update_curr = update_curr_fair, 39 40 #ifdef CONFIG_FAIR_GROUP_SCHED 41 .task_move_group = task_move_group_fair, 42 #endif 43 };
其中一些成员变量的含义为:
| 成员 | 描述 |
| next | 下个优先级的调度类, 让所有的调度类通过next链接在一个链表中 |
| enqueue_task | 向就绪队列中添加一个进程, 某个任务进入可运行状态时,该函数将得到调用。它将调度实体(进程)放入红黑树中,并对 nr_running 变量加 1 |
| dequeue_task | 将一个进程从就就绪队列中删除, 当某个任务退出可运行状态时调用该函数,它将从红黑树中去掉对应的调度实体,并从 nr_running 变量中减 1 |
| yield_task | 在进程想要资源放弃对处理器的控制权的时, 可使用在sched_yield系统调用, 会调用内核API yield_task完成此工作. compat_yield sysctl 关闭的情况下,该函数实际上执行先出队后入队;在这种情况下,它将调度实体放在红黑树的最右端 |
| check_preempt_curr | 该函数将检查当前运行的任务是否被抢占。在实际抢占正在运行的任务之前,CFS 调度程序模块将执行公平性测试。这将驱动唤醒式(wakeup)抢占 |
| pick_next_task | 该函数选择接下来要运行的最合适的进程 |
| put_prev_task | 用另一个进程代替当前运行的进程 |
| set_curr_task | 当任务修改其调度类或修改其任务组时,将调用这个函数 |
| task_tick | 在每次激活周期调度器时, 由周期性调度器调用, 该函数通常调用自 time tick 函数;它可能引起进程切换。这将驱动运行时(running)抢占 |
| task_fork | 内核调度程序为调度模块提供了管理新任务启动的机会, 用于建立fork系统调用和调度器之间的关联, 每次新进程建立后, 则用new_task通知调度器, CFS 调度模块使用它进行组调度,而用于实时任务的调度模块则不会使用这个函数 |
CFS的就绪队列:
1 struct cfs_rq { 2 struct load_weight load;/*CFS队列中所有进程的总负载*/ 3 unsigned int nr_running, h_nr_running; 4 5 u64 exec_clock;/**/ 6 u64 min_vruntime; /*最小虚拟运行时间*/ 7 #ifndef CONFIG_64BIT 8 u64 min_vruntime_copy; 9 #endif 10 /*红黑树的根root*/ 11 struct rb_root tasks_timeline;
12 /*红黑树最左边的节点,也是下一个调度节点*/ 13 struct rb_node *rb_leftmost; 14 15 /* 16 * 'curr' points to currently running entity on this cfs_rq. 17 * It is set to NULL otherwise (i.e when none are currently running). 18 */ 19 struct sched_entity *curr, *next, *last, *skip; 20 21 #ifdef CONFIG_SCHED_DEBUG 22 unsigned int nr_spread_over; 23 #endif 24 25 #ifdef CONFIG_SMP 26 /* 27 * CFS load tracking 28 */ 29 struct sched_avg avg; 30 u64 runnable_load_sum; 31 unsigned long runnable_load_avg; 32 #ifdef CONFIG_FAIR_GROUP_SCHED 33 unsigned long tg_load_avg_contrib; 34 #endif 35 atomic_long_t removed_load_avg, removed_util_avg; 36 #ifndef CONFIG_64BIT 37 u64 load_last_update_time_copy; 38 #endif 39 40 #ifdef CONFIG_FAIR_GROUP_SCHED 41 /* 42 * h_load = weight * f(tg) 43 * 44 * Where f(tg) is the recursive weight fraction assigned to 45 * this group. 46 */ 47 unsigned long h_load; 48 u64 last_h_load_update; 49 struct sched_entity *h_load_next; 50 #endif /* CONFIG_FAIR_GROUP_SCHED */ 51 #endif /* CONFIG_SMP */ 52 53 #ifdef CONFIG_FAIR_GROUP_SCHED 54 struct rq *rq; /* cpu runqueue to which this cfs_rq is attached */ 55 56 /* 57 * leaf cfs_rqs are those that hold tasks (lowest schedulable entity in 58 * a hierarchy). Non-leaf lrqs hold other higher schedulable entities 59 * (like users, containers etc.) 60 * 61 * leaf_cfs_rq_list ties together list of leaf cfs_rq's in a cpu. This 62 * list is used during load balance. 63 */ 64 int on_list; 65 struct list_head leaf_cfs_rq_list; 66 struct task_group *tg; /* group that "owns" this runqueue */ 67 68 #ifdef CONFIG_CFS_BANDWIDTH 69 int runtime_enabled; 70 u64 runtime_expires; 71 s64 runtime_remaining; 72 73 u64 throttled_clock, throttled_clock_task; 74 u64 throttled_clock_task_time; 75 int throttled, throttle_count; 76 struct list_head throttled_list; 77 #endif /* CONFIG_CFS_BANDWIDTH */ 78 #endif /* CONFIG_FAIR_GROUP_SCHED */ 79 };
一些成员变量的含义:
| 成员 | 描述 |
| nr_running | 队列上可运行进程的数目 |
| h_nr_running | 只对进程组有效,其下所有进程组中cfs_rq的nr_running总和 |
| load | 就绪队列上可运行进程的累计负荷权重(总负载) |
| min_vruntime | 跟踪记录队列上所有进程的最小虚拟运行时间. 这个值是实现与就绪队列相关的虚拟时钟的基础。当更新当前运行任务的累计运行时间时或者当任务从队列删除去,如任务睡眠或退出,这时候会查看剩下的任务的vruntime是否大于min_vruntime,如果是则更新该值。 |
| tasks_timeline | 用于在按时间排序的红黑树中管理所有进程(红黑树的root) |
| rb_leftmost | 总是设置为指向红黑树最左边的节点, 即需要被调度的进程. 该值其实可以可以通过病例红黑树获得, 但是将这个值存储下来可以减少搜索红黑树花费的平均时间 |
| curr | 当前正在运行的sched_entity(对于组虽然它不会在cpu上运行,但是当它的下层有一个task在cpu上运行,那么它所在的cfs_rq就把它当做是该cfs_rq上当前正在运行的sched_entity |
| next | 表示有些进程急需运行,即使不遵从CFS调度也必须运行它,调度时会检查是否next需要调度,有就调度next |
| skip | 略过进程(不会选择skip指定的进程调度) |
CFS调度的原理:
CFS思路很简单,就是根据各个进程的权重分配运行时间。
进程的运行时间计算公式为 : 分配给进程的运行时间 = 调度周期 * 进程权重 / 所有进程权重之和;
| 描述 | |
| 调度周期 | 所有处于TASK_RUNNING态进程都调度一遍的时间 |
| 进程权重 | 被调度进程的权重 |
| 所有进程权重之和 | 所有处于TASK_RUNNING状态进程的权重总和 |
所以我们可以举一个例子:比如某程序A的权重为1,而程序B的权重为2,调度周期为60ms,可以得到:
- 程序A所分配到的运行时间 = 60ms * 1 / (1+2) = 20ms
- 程序B所分配到的运行时间 = 60ms * 2 / (1+2) = 40ms
前面说过,调度还有一个重要的意义在于要对所有进程尽可能地公平分配时间,可是从分配时间来看,并没有让人感觉到公平,于是CFS引入了另一个变量 : 虚拟运行时间(virtual runtime) ,它记录着进程已经运行的时间,
但是并不是直接记录,而是要根据进程的权重将运行时间放大或者缩小一个比例。
而虚拟运行时间计算公式为:一次调度间隔的vruntime = 实际运行时间 * NICE_0_LOAD / 进程权重;
其中代码NICE_0_LOAD对应的是nice为0的进程的权重值为1024,而所有进程都以nice为0的进程的权重1024作为基准,计算自己的vruntime增加速度。(见后面公式)
/*nice和权重值的转换表*/ static const int prio_to_weight[40] = { /* -20 */ 88761, 71755, 56483, 46273, 36291, /* -15 */ 29154, 23254, 18705, 14949, 11916, /* -10 */ 9548, 7620, 6100, 4904, 3906, /* -5 */ 3121, 2501, 1991, 1586, 1277, /* 0 */ 1024, 820, 655, 526, 423, /* 5 */ 335, 272, 215, 172, 137, /* 10 */ 110, 87, 70, 56, 45, /* 15 */ 36, 29, 23, 18, 15, };
因为CFS中的就绪队列是一棵以vruntime为键值的红黑树,虚拟时间越小的进程越靠近整个红黑树的最左端。因此,调度器每次选择位于红黑树最左端的那个进程,该进程的vruntime最小。(对应之前的min_vruntime)
其中vruntime以下公式计算它的增长数值:
| 条件 | 公式 |
| 当前进程的nice != NICE_0_LOAD | vruntime += delta_exec * NICE_0_LOAD / 进程权重 |
| 当前进程的nice == NICE_0_LOAD | vruntime += delta_exec |
- 其中delta_exce为"内核计算当前和上一次更新负荷权重时两次的时间的差值", 计算公式为:delta_exec = 当前时间 - 上次更新时间
因此权重越大的进程的vruntime的增长率会越小,更容易排在红黑树偏左端,进而更容易被调度,而权重小的则相反。
计算完vruntime之后,就要进行设置红黑树。
2.6红黑树
2.6.1什么是红黑树?
红黑树是一种在插入或删除结点时都需要维持平衡的二叉查找树,并且每个结点都具有颜色属性:
- 一个结点要么是红色的,要么是黑色的。
- 根结点是黑色的。
- 如果一个结点是红色的,那么它的子结点必须是黑色的,也就是说在沿着从根结点出发的任何路径上都不会出现两个连续的红色结点。
- 从一个结点到一个NULL指针的每条路径上必须包含相同数目的黑色结点。
如下图所示:
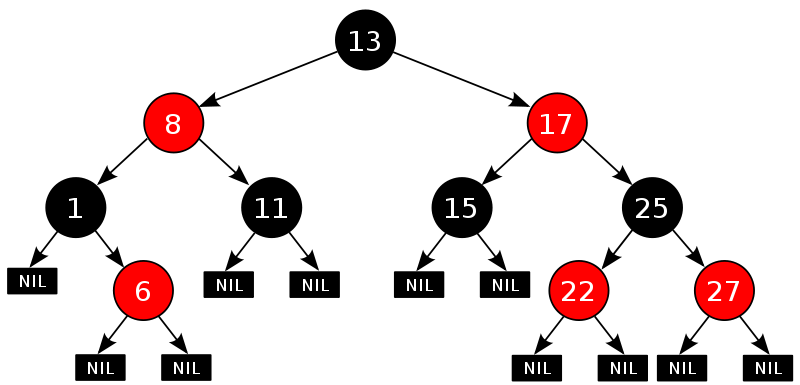
可以很明显的看出,该树的最左端的值是最小的。取走最左端的端点后,需要重新平衡红黑树。
2.6.2重新设置min_vruntime的红黑树
代码如下:
static void update_min_vruntime(struct cfs_rq *cfs_rq) {
/*初始化vruntime的值
*相当于如下的代码
*if (cfs_rq->curr != NULL)
* vruntime = cfs_rq->curr->vruntime;
*else
* vruntime = cfs_rq->min_vruntime;
*/ u64 vruntime = cfs_rq->min_vruntime; if (cfs_rq->curr) vruntime = cfs_rq->curr->vruntime;
/* 检测红黑树是都有最左的节点, 即是否有进程在树上等待调度
* cfs_rq->rb_leftmost(struct rb_node *)存储了进程红黑树的最左节点
* 这个节点存储了即将要被调度的结点 */
/* 获取最左结点的调度实体信息se, se中存储了其vruntime
* rb_leftmost的vruntime即树中所有节点的vruntiem中最小的那个 */
struct sched_entity *se = rb_entry(cfs_rq->rb_leftmost, struct sched_entity, run_node); /* 如果就绪队列上没有curr进程
* 则vruntime设置为树种最左结点的vruntime
* 否则设置vruntiem值为cfs_rq->curr->vruntime和se->vruntime的最小值 */ if (!cfs_rq->curr) /* 此时vruntime的原值为cfs_rq->min_vruntime*/ vruntime = se->vruntime; else /* 此时vruntime的原值为cfs_rq->curr->vruntime*/ vruntime = min_vruntime(vruntime, se->vruntime); } /* ensure we never gain time by being placed backwards.
* 为了保证min_vruntime单调不减
* 只有在vruntime超出的cfs_rq->min_vruntime的时候才更新 */ cfs_rq->min_vruntime = max_vruntime(cfs_rq->min_vruntime, vruntime); #ifndef CONFIG_64BIT smp_wmb(); cfs_rq->min_vruntime_copy = cfs_rq->min_vruntime; #endif }
重新平衡完min_vruntime的红黑树之后,就可以继续通过CFS去调度进程了,并以此循环。
3.体会
这些只是Linux下的一小部分罢了,源码的代码量大到吓人,基于无数大牛们的努力写出了现在的Linux,而Linux永远在不断的更新,这些代码算法等等永远不会是最好的,我还需要不断的学习新的知识,继续探索这个充斥着01的世界。