第一次作业内容
挑选一个开源的操作系统,深入源码分析其进程模型,具体包含如下内容:
- 操作系统是怎么组织进程的
- 进程状态如何转换(给出进程状态转换图)
- 进程是如何调度的
- 谈谈自己对该操作系统进程模型的看法
1. 前言
本文基于Linux Kernel 2.6.28 的源代码,分析本版本linux的进程模型和CFS调度器的基本算法。
源码浏览地址:https://elixir.bootlin.com/linux/v2.6.28/source
2. 进程
2.1 进程的定义
《计算机操作系统》这门课对进程有这样的描述:进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
2.2 进程的概念
进程的概念主要有两点:
第一,进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region)、数据区域(data region)和堆栈(stack region)。文本区域存储处理器执行的代码;数据区域存储变量和进程执行期间使用的动态分配的内存;堆栈区域存储着活动过程调用的指令和本地变量。
第二,进程是一个“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时,它才能成为一个活动的实体,我们称其为进程。
进程是操作系统中最基本、重要的概念。是多道程序系统出现后,为了刻画系统内部出现的动态情况,描述系统内部各道程序的活动规律引进的一个概念,所有多道程序设计操作系统都建立在进程的基础上。
操作系统引入进程的概念的原因:
1)从理论角度看,是对正在运行的程序过程的抽象;
2)从实现角度看,是一种数据结构,目的在于清晰地刻划动态系统的内在规律,有效管理和调度进入计算机系统主存储器运行的程序。
2.3 查看进程
2.3.1 Windows上的进程
2.3.2 Linux上的进程
3. 进程的组织
Linux进程通过一个task_struct结构体描述,在linux/sched.h中定义,通过理解该结构,可更清楚的理解linux进程模型。
3.1 进程状态(State)
进程执行时,它会根据具体情况改变状态。进程状态是调度和对换的依据。Linux中的进程主要有如下状态,如下表所示:
Linux进程的状态
| 内核表示 |
含义 |
| TASK_RUNNING |
可运行 |
| TASK_INTERRUPTIBLE |
可中断的等待状态 |
| TASK_UNINTERRUPTIBLE |
不可中断的等待状态 |
| TASK_ZOMBIE |
僵死 |
| TASK_STOPPED |
暂停 |
| TASK_SWAPPING |
换入/换出 |
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define __TASK_STOPPED 4
#define __TASK_TRACED 8
/* in tsk->exit_state */
#define EXIT_ZOMBIE 16
#define EXIT_DEAD 32
/* in tsk->state again */
#define TASK_DEAD 64
#define TASK_WAKEKILL 128
1).可运行状态:处于这种状态的进程,要么正在运行、要么正准备运行。正在运行的进程就是当前进程(由current所指向的进程),而准备运行的进程只要得到CPU就可以立即投入运行,CPU是这些进程唯一等待的系统资源。
2).等待状态:处于该状态的进程正在等待某个事件(event)或某个资源,它肯定位于系统中的某个等待队列(wait_queue)中。
3).暂停状态:此时的进程暂时停止运行来接受某种特殊处理。通常当进程接收到SIGSTOP、SIGTSTP、SIGTTIN或 SIGTTOU信号后就处于这种状态。例如,正接受调试的进程就处于这种状态。
4).僵死状态:进程虽然已经终止,但由于某种原因,父进程还没有执行wait()系统调用,终止进程的信息也还没有回收。顾名思义,处于该状态的进程就是死进程,这种进程实际上是系统中的垃圾,必须进行相应处理以释放其占用的资源。
3.2 进程标识符(Identifiers)
每个进程有进程标识符、用户标识符、组标识符,如下表所示。
各种标识符
| 域名 |
含义 |
| Pid |
进程标识符 |
| Uid、gid |
用户标识符、组标识符 |
| Euid、egid |
有效用户标识符、有效组标识符 |
| Suid、sgid |
备份用户标识符、备份组标识符 |
| Fsuid、fsgid |
文件系统用户标识符、文件系统组标识符 |
进程标识符是用来唯一地标识一个进程的一个数值,进程也可以根据PID来识别其他的进程。
#define PID_MAX_DEFAULT (CONFIG_BASE_SMALL ? 0x1000 : 0x8000)
PID的取值范围是0到32767,即系统中的进程数最大为32768个,基本上能够满足普通用户的日常使用。
3.3 进程转换图
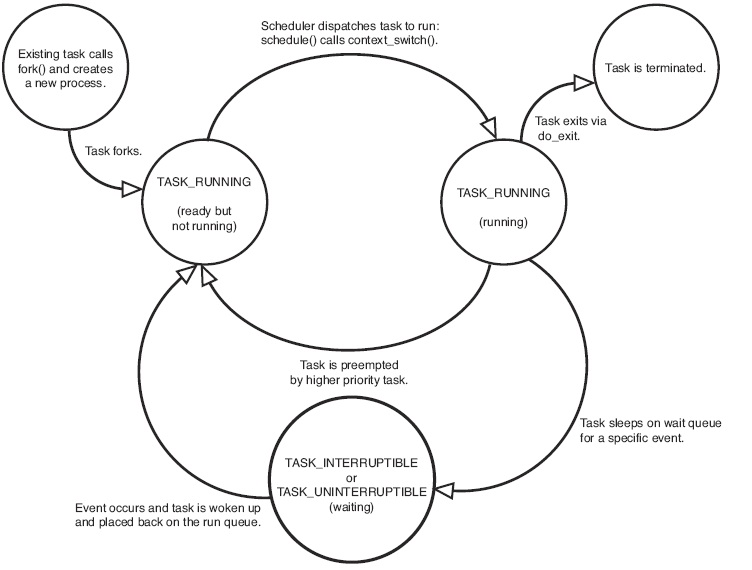
当一个进程的运行时间片用完,系统就会使用调度程序强制切换到其它的进程去执行。另外,如果进程在内核态执行时需要等待系统的某个资源,此时该进程就会调用sleep_on()或sleep_on_interruptible()自愿地放弃CPU的使用权,而让调度程序去执行其它进程。进程则进入睡眠状态(TASK_UNINTERRUPTIBLE或TASK_INTERRUPTIBLE)。
只有当进程从“内核运行态”转移到“睡眠状态”时,内核才会进行进程切换操作。在内核态下运行的进程不能被其它进程抢占,而且一个进程不能改变另一个进程的状态。为了避免进程切换时造成内核数据错误,内核在执行临界区代码时会禁止一切中断。
4. 进程的调度
随着时代的发展,linux也从其初始版本稳步发展到今天,从2.4的非抢占内核发展到今天的可抢占内核,调度器无论从代码结构还是设计思想上也都发生了翻天覆地的变化,其普通进程的调度算法也从O(1)到现在的CFS,一个好的调度算法应当考虑以下几个方面:
- 公平:保证每个进程得到合理的CPU时间。
- 高效:使CPU保持忙碌状态,即总是有进程在CPU上运行。
- 响应时间:使交互用户的响应时间尽可能短。
- 周转时间:使批处理用户等待输出的时间尽可能短。
- 吞吐量:使单位时间内处理的进程数量尽可能多。
- 负载均衡:在多核多处理器系统中提供更高的性能
4.1 调度器实体结构
CFS中用于记录进程运行时间的数据结构为“调度实体”,这个结构体被定义在include/linux/sched.h中:
struct sched_entity {
/* 用于进行调度均衡的相关变量,主要跟红黑树有关 */
struct load_weight load; // 权重,跟优先级有关
unsigned long runnable_weight; // 在所有可运行进程中所占的权重
struct rb_node run_node; // 红黑树的节点
struct list_head group_node; // 所在进程组
unsigned int on_rq; // 标记是否处于红黑树运行队列中
u64 exec_start; // 进程开始执行的时间
u64 sum_exec_runtime; // 进程总运行时间
u64 vruntime; // 虚拟运行时间,下面会给出详细解释
u64 prev_sum_exec_runtime; // 进程在切换CPU时的sum_exec_runtime,简单说就是上个调度周期中运行的总时间
u64 nr_migrations;
struct sched_statistics statistics;
// 以下省略了一些在特定宏条件下才会启用的变量
}
4.2 虚拟实时 (vruntime)
现在我们来谈谈上面结构体中的vruntime变量所表示的意义。我们称它为“虚拟运行时间”,该运行时间的计算是经过了所有可运行进程总数的标准化(简单说就是加权的)。它以ns为单位,与定时器节拍不再相关。
可以认为这是CFS为了能够实现理想多任务处理而不得不虚拟的一个新的时钟,具体地讲,一个进程的vruntime会随着运行时间的增加而增加,但这个增加的速度由它所占的权重来决定。
结果就是权重越高,增长越慢:所得到的调度时间也就越小 —— CFS用它来记录一个程序到底运行了多长时间以及还应该运行多久。
下面我们来看一下这个记账功能的实现源码:
/*
* Update the current task's runtime statistics.
*/
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
if (unlikely(!curr))
return;
// 获得从最后一次修改负载后当前任务所占用的运行总时间
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
// 更新执行开始时间
curr->exec_start = now;
schedstat_set(curr->statistics.exec_max,
max(delta_exec, curr->statistics.exec_max));
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq->exec_clock, delta_exec);
// 计算虚拟时间,具体的转换算法写在clac_delta_fair函数中
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cgroup_account_cputime(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
account_cfs_rq_runtime(cfs_rq, delta_exec);
}
这个函数是由系统定时器周期性调用的(无论进程的状态是什么),因此vruntime可以准确地测量给定进程的运行时间,并以此为依据推断出下一个要运行的进程是什么。
4.3 进程选择
这里便是调度的核心部分,用一句话来梗概CFS算法的核心就是选择具有最小vruntime的进程作为下一个需要调度的进程。为了实现选择,当然要维护一个可运行的进程队列(教科书上常说的ready队列),CFS使用了红黑树来组织这个队列。
4.3.1 找到下一个任务节点
先假设一个红黑树储存了系统中所有的可运行进程,节点的键值就是它们的vruntime,CFS现在要找到下一个需要调度的进程,那么就是要找到这棵红黑树上键值最小的那个节点:就是最左叶子节点。
实现此过程的源码如下:
static struct sched_entity *
pick_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
struct sched_entity *left = __pick_first_entity(cfs_rq);
struct sched_entity *se;
/*
* If curr is set we have to see if its left of the leftmost entity
* still in the tree, provided there was anything in the tree at all.
*/
if (!left || (curr && entity_before(curr, left)))
left = curr;
se = left; /* ideally we run the leftmost entity */
/*
* 下面的过程主要针对一些特殊情况,我们在此不做讨论
*/
if (cfs_rq->skip == se) {
struct sched_entity *second;
if (se == curr) {
second = __pick_first_entity(cfs_rq);
} else {
second = __pick_next_entity(se);
if (!second || (curr && entity_before(curr, second)))
second = curr;
}
if (second && wakeup_preempt_entity(second, left) < 1)
se = second;
}
if (cfs_rq->last && wakeup_preempt_entity(cfs_rq->last, left) < 1)
se = cfs_rq->last;
if (cfs_rq->next && wakeup_preempt_entity(cfs_rq->next, left) < 1)
se = cfs_rq->next;
clear_buddies(cfs_rq, se);
return se;
}
4.4 红黑树
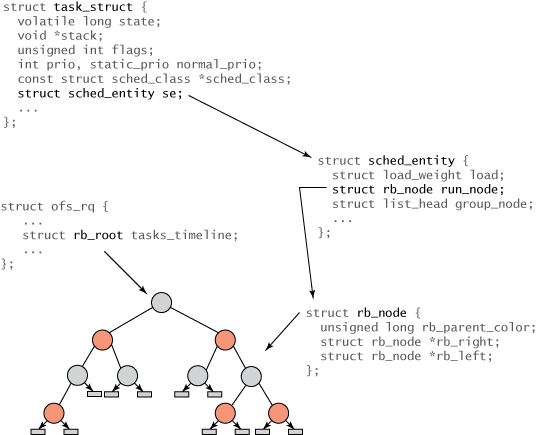
与之前的 Linux 调度器不同,它没有将任务维护在运行队列中,CFS 维护了一个以时间为顺序的红黑树(参见下图)。 红黑树 是一个树,具有很多有趣、有用的属性。首先,它是自平衡的,这意味着树上没有路径比任何其他路径长两倍以上。 第二,树上的运行按 O(log n) 时间发生(其中 n 是树中节点的数量)。这意味着您可以快速高效地插入或删除任务。
5. 谈谈自己对该操作系统进程模型的看法
操作系统中最核心的概念是进程, 进程也是并发程序设计中的一个最重要、 最基本的概念。进程是一个动态的过程, 即进程有生命周期, 它拥有资源, 是程序的执行过程, 其状态是变化的。操作系统的CFS调度算法还有一个重要特点,即调度粒度小。CFS之前的调度器中,除了进程调用了某些阻塞函数而主动参与调度之外,每个进程都只有在用完了时间片或者属于自己的时间配额之后才被抢占。而CFS则在每次tick都进行检查,如果当前进程不再处于红黑树的左边,就被抢占。在高负载的服务器上,通过调整调度粒度能够获得更好的调度性能。但是人们对操作系统的调度算法并不会休止于此,未来会有更多优秀的调度算法如雨后春笋般涌现出来。
6. 参考资料
2. linux调度器源码分析
3. Linux进程模型总结
4. Linux内核设计与实现