1.1.概述:Linux是一个基于POSIX和UNIX的多用户、多任务、支持多线程和多CPU的操作系统。
1.2.介绍:Linux继承了Unix以网络为核心的设计思想,能运行主要的UNIX工具软件、应用程序和网络协议;它支持32位和64位硬件。同时,也是一个性能稳定的多用户网络操作系统。并且可免费使用并自由传播。linux操作系统大部分用来架设服务器,提供高负载数据处理。
1.3.特点:Linux具有开源,免费,高效,安全等特点,更为重要的是Linux是一款免费的操作系统,用户可以通过网络或其他途径免费获得,并可以任意修改其源代码。这使得Linux始终与时俱进。
在理解Linux之后我们来谈谈:
2.什么是进程
2.1进程的定义:
狭义定义:进程是正在运行的程序的实例(an instance of a computer program that is being executed)。
广义定义:进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是基本的分配单元,也是基本的执行单元。
进程不只是程序的代码,还包括当前的活动,通过程序计数器的值和处理寄存器的内容来示。
2.2进程的概念:
主要有两点:第一,进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region)、数据区域(data region)和堆栈(stack region)。文本区域存储处理器执行的代码;数据区域存储变量和进程执行期间使用的动态分配的内存;堆栈区域存储着活动过程调用的指令和本地变量。第二,进程是一个“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时(操作系统执行之),它才能成为一个活动的实体,我们称其为进程。
2.3进程的特征:
·动态性:进程的实质是程序在多道程序系统中的一次执行过程,进程是动态产生,动态消亡的。
·并发性:任何进程都可以同其他进程一起并发执行
·独立性:进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位;
·异步性:由于进程间的相互制约,使进程具有执行的间断性,即进程按各自独立的、不可预知的速度向前推进
·结构特征:进程由程序、数据和进程控制块三部分组成。
接下来让我们看看 在Linux操作系统下一些运行的进程( ps 指令来查看):
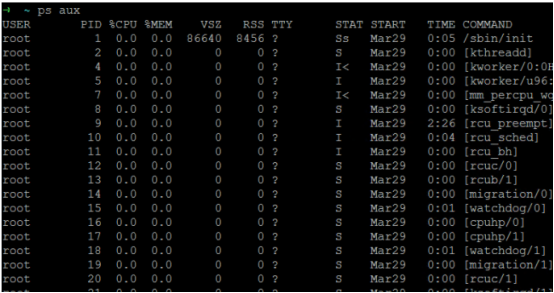
在我们常用的windows系统中的进程:
3.进程是如何创建的
3.1创建进程
(1) 系统初始化会创建新的进程
(2) 当一个正在运行的进程中,若执行了创建进程的系统调用,那么也会创建新的进程
(3) 用户发出请求,创建一个进程
(4) 初始化一个批处理作业时,也会创建新的线程
在Linux中主要提供了fork、vfork、clone三个进程创建方法。
Linux中可以使用fork函数来创建新进程。如下列代码所示:(2) 当一个正在运行的进程中,若执行了创建进程的系统调用,那么也会创建新的进程
(3) 用户发出请求,创建一个进程
(4) 初始化一个批处理作业时,也会创建新的线程
在Linux中主要提供了fork、vfork、clone三个进程创建方法。
Linux中可以使用fork函数来创建新进程。如下列代码所示:
#include<stdio.h> #include<sys/types.h> #include<unistd.h> int main(){ pid_t ret = fork(); printf("hello proc:%d,ret = %d\n",getpid(),ret); return 0; }
fork函数调用的用途 :一个进程希望复制自身,从而父子进程能同时执行不同段的代码。
3.2进程终止
(1) 正常退出
(2)错误退出
(3) 致命错误
(4) 被其他进程杀死
3.3进程控制块
广义义上,所有的进程信息被放在⼀个叫做进程控制块的数据结构中,可以理解为进程属性的集合,该控制块由操作系统创建和管理。
进程控制块是操作系统能够支持多线程和提供多重处理技术的关键工具。每个进程在内核中都有⼀个进程控制块(PCB)来维护进程相关的信息,
在Linux内核中 进程控制块是task_struct结构体,它包含了一个进程的所有信息。
该结构体被定义在" include/linux/sched.h" 文件中。
task_struct主要包含了下面这些内容:
标识符:描述本进程的唯一标识符,用来区别其他进程。
状态:任务状态、退出代码、退出信号等。
优先级:相对于其他进程的优先级。
程序计数器(PC):程序中即将被执行的下一条指令的地址。
内存指针:包括程序代码和进程相关数据的指针,还有和其它进程共享的内存块的指针。
上下文数据:进程执行时处理器的寄存器中的数据。
I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
记账信息:可能包括处理器时间总和,使用的时钟数综合、时间限制、记账号等。
3.4进程的标识符
进程标识符(PID)是一个进程的基本属性,其作用类似于每个人的身份证号码。
每个进程在系统中都有唯一的一个ID标识它。正是因为其唯一,所以系统可以根据它准确定位到一个进程。
在Linux shell中,可以使用ps命令查看当前用户所使用的进程。
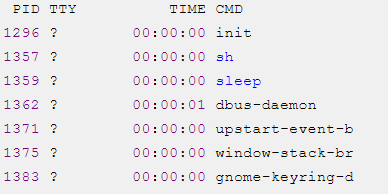
第一列内容是进程标识符(PID),这个标识符是唯一的.
4.进程的状态是如何转换的
4.1进程的状态:
进程状态反映进程执行过程的变化,这些状态随着进程的执行和外界条件的变化而转换。
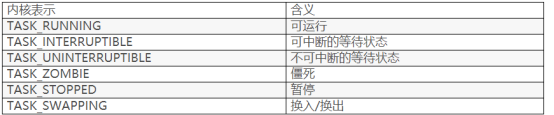
·可运行状态 处于这种状态的进程的包括正在运行和要么正准备运行的进程正在运行的进程就是当前进程(由current所指向的进程),而准备运行的进程只要得到CPU就可以立即投入运行,CPU是这些进程唯一等待的系统资源。系统中有一个运行队列(run_queue),用来容纳所有处于可运行状态的进程,调度程序执行时,从中选择一个进程投入运行。
·等待状态 处于该状态的进程正在等待某个事件(event)或某个资源,它肯定位于系统中的某个等待队列(wait_queue)中。Linux中处于等待状态的进程分为两种:可中断的等待状态和不可中断的等待状态。
·暂停状态 此时的进程暂时停止运行来接受某种特殊处理。通常当进程接收到SIGSTOP、SIGTSTP、SIGTTIN或 SIGTTOU信号后就处于这种状态。
·僵死状态 顾名思义,处于该状态的进程就是死进程,这种进程实际上是系统中的垃圾,必须进行相应处理以释放其占用的资源。
接着,让我们先来看看linux进程的状态图
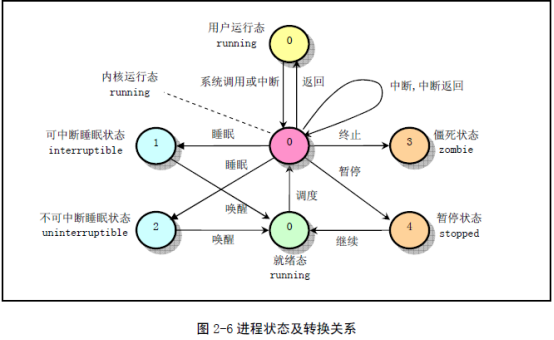
4.2进程的调度
4.2.1进程调度的概述:
无论是在批处理系统还是分时系统中,用户进程数一般都多于处理机数、这将导致它们互相争夺处理机。另外,系统进程也同样需要使用处理机。这就要求进程调度程序按一定的策略,动态地把处理机分配给处于就绪队列中的某一个进程,以使之执行。
那么就需要调度程序利用一部分信息决定系统中哪个进程最应该运行,并结合进程的状态信息以保证系统运转的公平和高效。
目的:调度程序运行时,要在所有可运行状态的进程中选择最值得运行的进程投入运行。
4.2.2进程调度发生在什么时候呢?
(1)正在执行的进程执行完毕。这时,如果不选择新的就绪进程执行,将浪费处理机资源。
(2)执行中进程自己调用阻塞原语将自己阻塞起来进入睡眠等状态。
(3)执行中进程调用了P原语操作,从而因资源不足而被阻塞;或调用了v原语操作激活了等待资源的进程队列。
(4)执行中进程提出I/O请求后被阻塞。
(5)在分时系统中时间片已经用完。
(6)在执行完系统调用等系统程序后返回用户进程时,这时可看作系统进程执行完毕,从而可调度选择一新的用户进程执行。
(7)就绪队列中的某进程的优先级变得高于当前执行进程的优先级,从而也将引发进程调度。
4.2.3两种占用CPU的方式
可剥夺式 (可抢占式preemptive):就绪队列中一旦有优先级高于当前执行进程优先级的进程存在时,便立即发生进程调度,转让处理机。
不可剥夺式 (不可抢占式non_preemptive):即使在就绪队列存在有优先级高于当前执行进程时,当前进程仍将占用处理机直到该进程自己因调用原语操作或等待I/O而进入阻塞、睡眠状态,或时间片用完时才重新发生调度让出处理机。
4.3进程调度的管理
这么多的进程需要占用CPU,那么哪个进程优先占用CPU就饿尤为重要了。
操作系统需要一个管理单元,负责调度进程,由管理单元来决定下一刻应该由谁使用CPU,这里充当管理单元的就是进程调度器。进程调度器的任务就是合理分配CPU时间给运行的进程。
5.什么是调度器?
5.1简介
通常来说,操作系统是应用程序和可用资源之间的媒介。
典型的资源有内存和物理设备。但是CPU也可以认为是一个资源,调度器可以临时分配一个任务在上面执行(单位是时间片)。调度器使得我们同时执行多个程序成为可能,因此可以与具有各种需求的用户共享CPU。
内核必须提供一种方法, 在各个进程之间尽可能公平地共享CPU时间, 而同时又要考虑不同的任务优先级.
调度器的一个重要目标是有效地分配 CPU 时间片,同时提供很好的用户体验。调度器还需要面对一些互相冲突的目标,例如既要为关键实时任务最小化响应时间, 又要最大限度地提高 CPU 的总体利用率.
5.2优先级

5.3调度策略

5.4 linux调度器的演变
开始的调度器是复杂度为O(n)O(n)的始调度算法(实际上每次会遍历所有任务,所以复杂度为O(n)), 这个算法的缺点是当内核中有很多任务时,调度器本身就会耗费不少时间,所以,从linux2.5开始引入赫赫有名的O(1)O(1)调度器
然而,linux是集全球很多程序员的聪明才智而发展起来的超级内核,没有最好,只有更好,在O(1)O(1)调度器风光了没几天就又被另一个更优秀的调度器取代了,它就是CFS调度器(Completely Fair Scheduler.) 这个也是在2.6内核中引入的,具体为2.6.23。
5.5 CFS 调度器
CFS设计思路很简单,就是根据各个进程的权重分配运行时间。
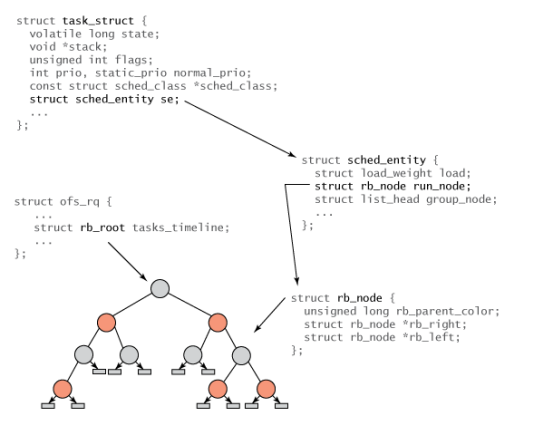
重点是红黑树。
红黑树 (Red–black tree) 是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构。
在 CFS 调度器中将 sched_entity 存储在以时间为顺序的红黑树中,vruntime 最低的进程存储在树的左侧,vruntime 最高的进程存储在树的右侧。
其实CFS 调度器的就绪队列就是一棵以 vruntime 为键值的红黑树, vruntime 越小的进程就越靠近整棵红黑树的最左端。因此,调度器只需要每次都选择位于红黑树最左端的那个进程即可,因为该进程的 vruntime 最小,即该进程最值得运行。
5.6CFS 调度器的基本原理:
1.设定一个调度周期 (sched_latency_ns),目的是让每个进程在这个周期内至少有机会运行一次.
2.然后根据进程的数量,各个进程平均分配这个调度周期内的 CPU 使用权。这时由于各个进程的优先级 (即 nice 值不同),分割调度周期的时候需要加权分配.
3.每个进程的累计运行时间保存在自己的 vruntime 字段内,哪个进程的 vruntime 最小就能获得运行的权利。
4.总的来说,所有进程的vruntime增长速度宏观上看应该是同时推进的.
那么就可以用这个vruntime来选择运行的进程,谁的vruntime值较小就说明它以前占用cpu的时间较短,受到了“不公平”对待,因此下一个运行进程就是它。这样既能公平选择进程,又能保证高优先级进程获得较多的运行时间。这就是CFS的主要思想了。
6.如何调度进程
6.1主调度器
一旦确定了要进行进程调度,那么schedule函数被调用。
主调度器被定义在 kernel/sched.c 文件中,由 schedule() 函数实现。
调度实体
/* * CFS stats for a schedulable entity (task, task-group etc) * * Current field usage histogram: * * 4 se->block_start * 4 se->run_node * 4 se->sleep_start * 4 se->sleep_start_fair * 6 se->load.weight * 7 se->delta_fair * 15 se->wait_runtime */ struct sched_entity { long wait_runtime; unsigned long delta_fair_run; unsigned long delta_fair_sleep; unsigned long delta_exec; s64 fair_key; struct load_weight load; /* for load-balancing */ struct rb_node run_node; unsigned int on_rq; u64 exec_start; u64 sum_exec_runtime; u64 prev_sum_exec_runtime; u64 wait_start_fair; u64 sleep_start_fair; #ifdef CONFIG_SCHEDSTATS u64 wait_start; u64 wait_max; s64 sum_wait_runtime; u64 sleep_start; u64 sleep_max; s64 sum_sleep_runtime; u64 block_start; u64 block_max; u64 exec_max; unsigned long wait_runtime_overruns; unsigned long wait_runtime_underruns; #endif
运行实体结构为sched_entity,所有的调度器都必须对进程运行时间做记账,以确保每个进程在这个周期内至少有机会运行一次
运行队列
struct cfs_rq { struct load_weight load;/*运行负载*/ unsigned long nr_running;/*运行进程个数*/ u64 exec_clock; u64 min_vruntime;/*保存的最小运行时间*/ struct rb_root tasks_timeline;/*运行队列树根*/ struct rb_node *rb_leftmost;/*保存的红黑树最左边的节点,这个为最小运行时间的节点,当进程选择下一个来运行时,直接选择这个*/ struct list_head tasks; struct list_head *balance_iterator; /* * 'curr' points to currently running entity on this cfs_rq. * It is set to NULL otherwise (i.e when none are currently running). */ struct sched_entity *curr, *next, *last; unsigned int nr_spread_over; #ifdef CONFIG_FAIR_GROUP_SCHED struct rq *rq; /* cpu runqueue to which this cfs_rq is attached */ /* * leaf cfs_rqs are those that hold tasks (lowest schedulable entity in * a hierarchy). Non-leaf lrqs hold other higher schedulable entities * (like users, containers etc.) * * leaf_cfs_rq_list ties together list of leaf cfs_rq's in a cpu. This * list is used during load balance. */ struct list_head leaf_cfs_rq_list; struct task_group *tg; /* group that "owns" this runqueue */ #ifdef CONFIG_SMP /* * the part of load.weight contributed by tasks */ unsigned long task_weight; /* * h_load = weight * f(tg) * * Where f(tg) is the recursive weight fraction assigned to * this group. */ unsigned long h_load; /* * this cpu's part of tg->shares */ unsigned long shares; /* * load.weight at the time we set shares */ unsigned long rq_weight; #endif #endif };
虚拟运行时间
struct sched_entity { struct load_weight load; /* for load-balancing负荷权重,这个决定了进程在CPU上的运行时间和被调度次数 */ struct rb_node run_node; unsigned int on_rq; /* 是否在就绪队列上 */ u64 exec_start; /* 上次启动的时间*/ u64 sum_exec_runtime; u64 vruntime; u64 prev_sum_exec_runtime; /* rq on which this entity is (to be) queued: */ struct cfs_rq *cfs_rq; ... };
虚拟运行时间是通过进程的实际运行时间和进程的权重(weight)计算出来的。CFS通过每个进程的虚拟运行时间(vruntime)来衡量哪个进程最值得被调度。CFS中的就绪队列是一棵以vruntime为键值的红黑树,虚拟时间越小的进程越靠近整个红黑树的最左端。因此,调度器每次选择位于红黑树最左端的那个进程,该进程的vruntime最小。
static struct task_struct *pick_next_task_fair(struct rq *rq) { struct task_struct *p; struct cfs_rq *cfs_rq = &rq->cfs; struct sched_entity *se; if (unlikely(!cfs_rq->nr_running)) return NULL; do {/*此循环为了考虑组调度*/ se = pick_next_entity(cfs_rq); set_next_entity(cfs_rq, se);/*设置为当前运行进程*/ cfs_rq = group_cfs_rq(se); } while (cfs_rq); p = task_of(se); hrtick_start_fair(rq, p); return p; }
调用_pick_next_entity完成实质工作
/*函数本身并不会遍历数找到最左叶子节点(是 所有进程中vruntime最小的那个),因为该值已经缓存 在rb_leftmost字段中*/ static struct sched_entity *__pick_next_entity(struct cfs_rq *cfs_rq) { /*rb_leftmost为保存的红黑树的最左边的节点*/ struct rb_node *left = cfs_rq->rb_leftmost; if (!left) return NULL; return rb_entry(left, struct sched_entity, run_node);
_pick_next_entity其实就是挑选了红黑树最左端的子节点作为下一个调度执行的进程,即挑选当前 vruntime 最小的进程作为下一个调度执行的进程。
7.对操作系统进程模型的看法
这次对于linux的进程的学习,由linux开始了解,再到进程的创建,转换,组织,管理,调度的效率,再去深入了解CFS 调度器,才感到创建一种新的算法来让当前系统所有的进程更高效地运行是多么难。也从中了解到,进程是操作系统的重要组成部分。
可能在生活,我 们并不会去深入进程的作用也看不到操作系统在这背后对进程的优化以及调度做了多大的努力。但是那些不断追求进程的效率与公平的努力始终在背后推动着我们的生活。
在将从一开始的非抢占式单任务运行系统到现在的抢占式多任务并行系统,进程的调度算法一次又一次的优化创新,到学到CFS 调度器2.6版。在未来我们研究出更好的算法去提高效率。