本文是针对Linux kernel2.6.10的源码而分析其进程模型,主要内容如下:
(1)什么是进程
(2)操作系统是怎么组织进程的
(3)进程状态如何转换
(4)进程是如何调度的
(5)对Linux kernel2.6.10操作系统的进程模型的看法
2.什么是进程?
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。(摘自百度百科)
在win10系统中的查看进程只需打开任务管理器就可以看到:

在 Linux 系统中可以用 ps 指令来查看当前正在运行的进程的一些基本信息:

3.操作系统是怎么组织进程的
在Linux系统中,进程在 include/linux/sched.h 的头文件中定义为 task_struct 的结构体来描述进程,每一次的调用即为一个进程。
(1)进程标识符PID
每个进程都有自己唯一的PID,在linux/config.h的头文件中PID的最大值被定义为:
#define PID_MAX_DEFAULT 0x8000
转成十进制就是32768,即PID的取值范围为0~32768(十进制)。PID 0和PID 1对于系统有特点的意义,其他的进程标识符都被认为是普通进程。
(2)进程状态
进程状态在 task_struct 中的定义为:
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
state 的取值如下:(定义在 asm/processor.h 头文件中)
#define TASK_RUNNING 0 #define TASK_INTERRUPTIBLE 1 #define TASK_UNINTERRUPTIBLE 2 #define TASK_STOPPED 4 #define TASK_TRACED 8 #define EXIT_ZOMBIE 16 #define EXIT_DEAD 32
linux系统所运行的进程是以上的某一种。
RUNNING表示是可运行或正在运行的,INTERRUPTIBLE表示进程被阻塞处于睡眠状态,UNINTERRUPTIBLE与INTERRUPTIBLE类似,STOPPED表示进程被停止运行,TRACED表示该进程被另一个进程所监视,ZOMBIE表示进程的执行被终止。
(3)进程描述
1.内核把进程的列表存放在叫做任务队列(task list)的双向循环链表中。链表中每一项都是类型为 task_struct ,称为进程描述符(process descriptor)的结构,该结构定义在 include/linux/sched.h 头文件中。进程描述符中包含了一个具体进程的所有信息。2.所有运行在系统中的进程都以 task_struct 链表的形式存在内核中;
让我们来看看 task_struct 结构体代码:
struct task_struct { volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ struct thread_info *thread_info; atomic_t usage; unsigned long flags; /* per process flags, defined below */ unsigned long ptrace; int lock_depth; /* Lock depth */ int prio, static_prio; struct list_head run_list; prio_array_t *array; unsigned long sleep_avg; long interactive_credit; unsigned long long timestamp, last_ran; int activated; unsigned long policy; cpumask_t cpus_allowed; unsigned int time_slice, first_time_slice; #ifdef CONFIG_SCHEDSTATS struct sched_info sched_info; #endif struct list_head tasks; /* * ptrace_list/ptrace_children forms the list of my children * that were stolen by a ptracer. */ struct list_head ptrace_children; struct list_head ptrace_list; struct mm_struct *mm, *active_mm; /* task state */ struct linux_binfmt *binfmt; long exit_state; int exit_code, exit_signal; int pdeath_signal; /* The signal sent when the parent dies */ /* ??? */ unsigned long personality; unsigned did_exec:1; pid_t pid; pid_t tgid; /* * pointers to (original) parent process, youngest child, younger sibling, * older sibling, respectively. (p->father can be replaced with * p->parent->pid) */ struct task_struct *real_parent; /* real parent process (when being debugged) */ struct task_struct *parent; /* parent process */ /* * children/sibling forms the list of my children plus the * tasks I'm ptracing. */ struct list_head children; /* list of my children */ struct list_head sibling; /* linkage in my parent's children list */ struct task_struct *group_leader; /* threadgroup leader */ /* PID/PID hash table linkage. */ struct pid pids[PIDTYPE_MAX]; wait_queue_head_t wait_chldexit; /* for wait4() */ struct completion *vfork_done; /* for vfork() */ int __user *set_child_tid; /* CLONE_CHILD_SETTID */ int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */ unsigned long rt_priority; unsigned long it_real_value, it_prof_value, it_virt_value; unsigned long it_real_incr, it_prof_incr, it_virt_incr; struct timer_list real_timer; unsigned long utime, stime; unsigned long nvcsw, nivcsw; /* context switch counts */ struct timespec start_time; /* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */ unsigned long min_flt, maj_flt; /* process credentials */ uid_t uid,euid,suid,fsuid; gid_t gid,egid,sgid,fsgid; struct group_info *group_info; kernel_cap_t cap_effective, cap_inheritable, cap_permitted; unsigned keep_capabilities:1; struct user_struct *user; #ifdef CONFIG_KEYS struct key *session_keyring; /* keyring inherited over fork */ struct key *process_keyring; /* keyring private to this process (CLONE_THREAD) */ struct key *thread_keyring; /* keyring private to this thread */ #endif unsigned short used_math; char comm[16]; /* file system info */ int link_count, total_link_count; /* ipc stuff */ struct sysv_sem sysvsem; /* CPU-specific state of this task */ struct thread_struct thread; /* filesystem information */ struct fs_struct *fs; /* open file information */ struct files_struct *files; /* namespace */ struct namespace *namespace; /* signal handlers */ struct signal_struct *signal; struct sighand_struct *sighand; sigset_t blocked, real_blocked; struct sigpending pending; unsigned long sas_ss_sp; size_t sas_ss_size; int (*notifier)(void *priv); void *notifier_data; sigset_t *notifier_mask; void *security; struct audit_context *audit_context; /* Thread group tracking */ u32 parent_exec_id; u32 self_exec_id; /* Protection of (de-)allocation: mm, files, fs, tty, keyrings */ spinlock_t alloc_lock; /* Protection of proc_dentry: nesting proc_lock, dcache_lock, write_lock_irq(&tasklist_lock); */ spinlock_t proc_lock; /* context-switch lock */ spinlock_t switch_lock; /* journalling filesystem info */ void *journal_info; /* VM state */ struct reclaim_state *reclaim_state; struct dentry *proc_dentry; struct backing_dev_info *backing_dev_info; struct io_context *io_context; unsigned long ptrace_message; siginfo_t *last_siginfo; /* For ptrace use. */ /* * current io wait handle: wait queue entry to use for io waits * If this thread is processing aio, this points at the waitqueue * inside the currently handled kiocb. It may be NULL (i.e. default * to a stack based synchronous wait) if its doing sync IO. */ wait_queue_t *io_wait; #ifdef CONFIG_NUMA struct mempolicy *mempolicy; short il_next; /* could be shared with used_math */ #endif };
(4)操作系统执行程序图
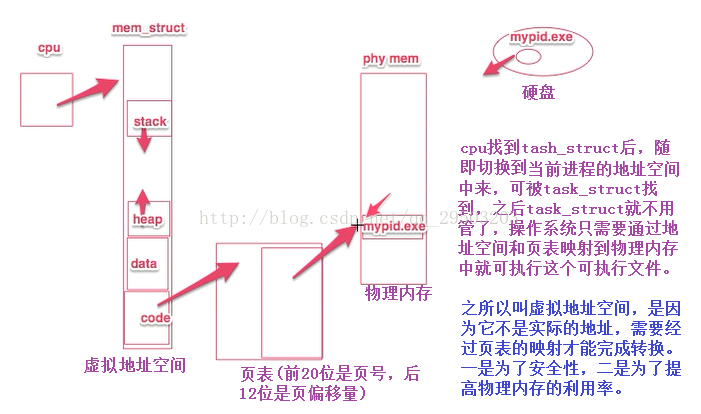
4.进程状态的转换
引用一张描述简单的进程状态之间是如何转换的图(图片来源于网络)

5.进程是如何进行调度的
(1)概述
由于Linux kernel2.6.10的调度算法是O(1)的算法,直到2.6.23的内核系统才采用CFS算法,所以这里我只介绍关于O(1)的调度算法。
(2)O(1)调度算法简介
O(1)调度算法的进程优先级的最大值为139,因此MAX_PRIO的最大值取140(具体是普通进程使用100到139的优先级,实施进程使用0到99的优先级)。所以该调度算法为每一个优先级都设置了一个可运行队列,即包含140个可运行状态的进程链表,每一条优先级链表上的进程都具有相同的优先级,而不同进程链表上的进程都拥有不同的优先级。
除此之外, 还包括一个优先级位图bitmap。该位图使用一个位(bit)来代表一个优先级,而140个优先级最少需要5个32位来表示, 因此只需要一个int[5]就可以表示位图,该位图中的所有位都被置0,当某个优先级的进程处于可运行状态时,该优先级所对应的位就被置1。
如果确定了优先级,那么选取下一个进程就简单了,只需在queue数组中对应的链表上选取一个进程即可。
最后,在早期的内核中,抢占是不可能的;这意味着如果有一个低优先级的任务在执行,高优先级的任务只能等待它完成。
由于O(1)算法是有O(n)改进而来的,所以O(1)解决了O(n)里的扩展性问题。
(3)O(1)算法
优先级计算
普通进程的优先级计算
不同类型的进程应该有不同的优先级。每个进程与生俱来(即从父进程那里继承而来)都有一个优先级,我们将其称为静态优先级。普通进程的静态优先级范围从100到139,100为最高优先级,139 为最低优先级,0-99保留给实时进程。当进程用完了时间片后,系统就会为该进程分配新的时间片(即基本时间片),静态优先静态优先级和基本时间片的关系:
静态优先级<120,基本时间片=max((140-静态优先级)*20, MIN_TIMESLICE)
静态优先级>=120,基本时间片=max((140-静态优先级)*5, MIN_TIMESLICE)
其中MIN_TIMESLICE为系统规定的最小时间片。从该计算公式可以看出,静态优先级越高(值越低),进程得到的时间片越长。其结果是,优先级高的进程会获得更长的时间片,而优先级低的进程得到的时间片则较短。进程除了拥有静态优先级外,还有动态优先级,其取值范围是100到139。当调度程序选择新进程运行时就会使用进程的动态优先级,动态优先级和静态优先级的关系可参考下面的公式:
动态优先级=max(100 , min(静态优先级 – bonus + 5) , 139)
从上面看出,动态优先级的生成是以静态优先级为基础,再加上相应的惩罚或奖励(bonus)。这个bonus并不是随机的产生,而是根据进程过去的平均睡眠时间做相应的惩罚或奖励。
实时进程的优先级计算
实时进程的优先级由sys_sched_setscheduler()设置。该值不会动态修改,而且总是比普通进程的优先级高。在进程描述符中用rt_priority域表示。
普通进程的调度选择算法基于进程的优先级,拥有最高优先级的进程被调度器选中。
6.对操作系统进程模型的看法
我觉得进程模型运用链表的优先级有很大缺陷,因为他无法对每一个进程保持相对的公平。所以我觉得操作系统的进程模型应该向着对每个进程相对完全公平的方向发展,并且能够处于高效状态。但是鱼与熊掌不可兼得,有时候两者是无法同时照顾到的,所以应该对于每个场景进行最优化处理,从而提高效率。
7.参考资料
1.https://blog.csdn.net/gatieme/article/details/51701149
2.https://www.cnblogs.com/Nancy5104/p/5338062.html
3.https://baike.baidu.com/item/%E8%BF%9B%E7%A8%8B/382503?fr=aladdin