特别注意,onnx-tensorrt项目目前发布了几个版本
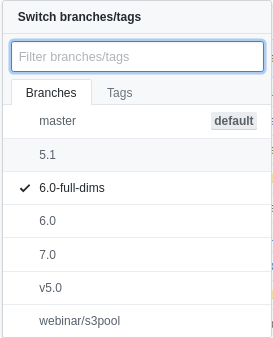
TensorRT5对应的版本是5.1,TensorRT6对应的版本是6.0而不是6.0-full-dims,6.0-full-dims支持的是早期发布的tensorrt7.0测试版,同时也支持tensorrt7.0正式版(我没有找到下载源,但是用tensorrt7.0正式版编译测试通过了),7.0对应的是tensorrt7.0正式版。
错误点
使用pytorch1.2,1.3导出的ONNX模型,如下面这个resnet18的代码:
import torch
import torch.nn as nn
import math
dummy_input = torch.randn(10, 3, 224, 224, device='cuda')
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
#x = x.view([int(x.size(0)), -1])
x = x.flatten(1)
x = self.fc(x)
return x
def resnet18(pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
model = resnet18(pretrained=False).cuda()
# Providing input and output names sets the display names for values
# within the model's graph. Setting these does not change the semantics
# of the graph; it is only for readability.
#
# The inputs to the network consist of the flat list of inputs (i.e.
# the values you would pass to the forward() method) followed by the
# flat list of parameters. You can partially specify names, i.e. provide
# a list here shorter than the number of inputs to the model, and we will
# only set that subset of names, starting from the beginning.
input_names = [ "actual_input_1" ] + [ "learned_%d" % i for i in range(16) ]
output_names = [ "output1" ]
torch.onnx.export(model, dummy_input, "resnet.onnx", verbose=True, opset_version=8, input_names=input_names, output_names=output_names)
使用TensorRT5或者TensorRT6就会报这个错误,需要特别注意的是TensorRT7没有这个错误:
./trtexec --onnx=/home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx --saveEngine=/home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
&&&& RUNNING TensorRT.trtexec # ./trtexec --onnx=/home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx --saveEngine=/home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
[I] onnx: /home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx
[I] saveEngine: /home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
----------------------------------------------------------------
Input filename: /home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx
ONNX IR version: 0.0.4
Opset version: 8
Producer name: pytorch
Producer version: 1.2
Domain:
Model version: 0
Doc string:
----------------------------------------------------------------
WARNING: ONNX model has a newer ir_version (0.0.4) than this parser was built against (0.0.3).
[I] Engine has been successfully saved to /home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
[I] Average over 10 runs is 2.11649 ms (host walltime is 2.29903 ms, 99% percentile time is 4.69494).
[I] Average over 10 runs is 1.83926 ms (host walltime is 2.16407 ms, 99% percentile time is 1.86864).
[I] Average over 10 runs is 1.85446 ms (host walltime is 2.00289 ms, 99% percentile time is 1.9159).
[I] Average over 10 runs is 1.86921 ms (host walltime is 2.02806 ms, 99% percentile time is 1.9281).
[I] Average over 10 runs is 1.6989 ms (host walltime is 2.01449 ms, 99% percentile time is 1.91136).
[I] Average over 10 runs is 1.59095 ms (host walltime is 1.89619 ms, 99% percentile time is 1.66589).
[I] Average over 10 runs is 1.57186 ms (host walltime is 1.77435 ms, 99% percentile time is 1.59123).
[I] Average over 10 runs is 1.58843 ms (host walltime is 1.78037 ms, 99% percentile time is 1.65168).
[I] Average over 10 runs is 1.57083 ms (host walltime is 1.81921 ms, 99% percentile time is 1.58486).
[I] Average over 10 runs is 1.58289 ms (host walltime is 1.86758 ms, 99% percentile time is 1.62566).
&&&& PASSED TensorRT.trtexec # ./trtexec --onnx=/home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx --saveEngine=/home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
(base) ➜ bin ./trtexec --onnx=/home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx --saveEngine=/home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
&&&& RUNNING TensorRT.trtexec # ./trtexec --onnx=/home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx --saveEngine=/home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
[I] onnx: /home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx
[I] saveEngine: /home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
----------------------------------------------------------------
Input filename: /home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx
ONNX IR version: 0.0.4
Opset version: 8
Producer name: pytorch
Producer version: 1.3
Domain:
Model version: 0
Doc string:
----------------------------------------------------------------
WARNING: ONNX model has a newer ir_version (0.0.4) than this parser was built against (0.0.3).
While parsing node number 0 [Conv]:
ERROR: ModelImporter.cpp:288 In function importModel:
[5] Assertion failed: tensors.count(input_name)
[E] failed to parse onnx file
[E] Engine could not be created
[E] Engine could not be created
&&&& FAILED TensorRT.trtexec # ./trtexec --onnx=/home/shining/work/Optimization/maskrcnn-benchmark/demo/resnet.onnx --saveEngine=/home/shining/work/Optimization/maskrcnn-benchmark/demo/test.trt
简言之就是:
Assertion failed: tensors.count(input_name)
错误原因
For the assertion failure, I checked the ModelImport.cpp. I assume it’s because the code finds that one of the nodes have 0 input? Though I checked the graph of my model, don’t think that’s the case.
for( size_t node_idx : topological_order ) {
_current_node = node_idx;
::ONNX_NAMESPACE::NodeProto const& node = graph.node(node_idx);
std::vector<TensorOrWeights> inputs;
for( auto const& input_name : node.input() ) {
ASSERT(tensors.count(input_name), ErrorCode::kINVALID_GRAPH);
inputs.push_back(tensors.at(input_name));
}
// ...
}
On a separate note, have you run the onnx checker after exporting?
import onnx
onnx.checker.check_model(onnx_model)
The checker threw a warning for me:
Nodes in a graph must be topologically sorted, however input 'conv2d_31_Relu_0' of node:
input: "conv2d_31_Relu_0" output: "transpose_output7" name: "Transpose21" op_type: "Transpose" attribute { name: "perm" ints: 0 ints: 2 ints: 3 ints: 1 type: INTS } doc_string: "" domain: ""
is not output of any previous nodes.
感谢https://github.com/pango99 提供解决方案

首先,进入https://github.com/onnx/onnx-tensorrt/tree/5.1下载源码(注意根据自己的tensorrt版本选择对应版本号的branch),修改onnx-tensorrt项目的ModelImport.cpp源码,然后根据源码提示进行编译。
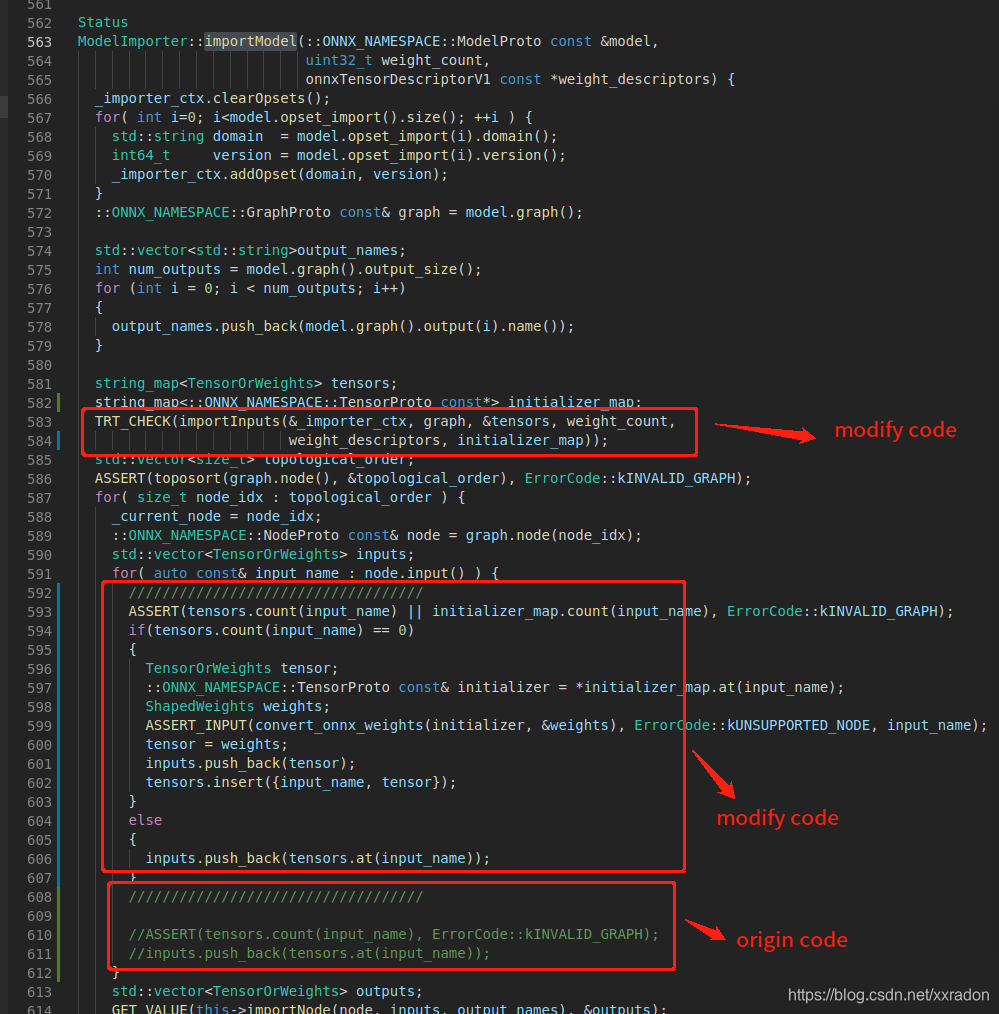
以下是修改过后的ModelImport.cpp源码:
/*
* Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
*
* Permission is hereby granted, free of charge, to any person obtaining a
* copy of this software and associated documentation files (the "Software"),
* to deal in the Software without restriction, including without limitation
* the rights to use, copy, modify, merge, publish, distribute, sublicense,
* and/or sell copies of the Software, and to permit persons to whom the
* Software is furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in
* all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
* THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
* FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
* DEALINGS IN THE SOFTWARE.
*/
#include "ModelImporter.hpp"
#include "toposort.hpp"
#include "onnx_utils.hpp"
#include "onnx2trt_utils.hpp"
#include <google/protobuf/io/coded_stream.h>
#include <google/protobuf/io/zero_copy_stream_impl.h>
#include <google/protobuf/text_format.h>
#include <limits>
namespace onnx2trt {
//Status const& ModelImporter::setInput(const char* name, nvinfer1::ITensor* input) {
// _importer_ctx.setUserInput(name, input);
// _last_error = Status::success();
// return _last_error;
//}
//
//Status const& ModelImporter::setOutput(const char* name, nvinfer1::ITensor** output) {
// _importer_ctx.setUserOutput(name, output);
// _last_error = Status::success();
// return _last_error;
//}
Status importInput(ImporterContext* importer_ctx,
::ONNX_NAMESPACE::ValueInfoProto const& input,
nvinfer1::ITensor** tensor) {
auto const& onnx_tensor_type = input.type().tensor_type();
nvinfer1::DataType trt_dtype;
ASSERT_INPUT(convert_input_dtype(onnx_tensor_type.elem_type(), &trt_dtype),
ErrorCode::kUNSUPPORTED_NODE, input.name());
ASSERT_INPUT(onnx_tensor_type.shape().dim().size() > 0,
ErrorCode::kUNSUPPORTED_NODE, input.name());
nvinfer1::Dims trt_dims;
TRT_CHECK(convert_dims(onnx_tensor_type.shape().dim(), trt_dims));
nvinfer1::ITensor* user_input = importer_ctx->getUserInput(input.name().c_str());
if( user_input ) {
ASSERT_INPUT(user_input, ErrorCode::kINVALID_VALUE, input.name());
// Note: We intentionally don't check dimensions/dtype here so that users
// can change the input shape/type if they want to.
//ASSERT(trt_dims == user_input->getDimensions(), ErrorCode::kINVALID_VALUE);
//ASSERT(trt_dtype == user_input->getType(), ErrorCode::kINVALID_VALUE);
*tensor = user_input;
return Status::success();
}
#if NV_TENSORRT_MAJOR < 4
// WAR for TRT not supporting < 3 input dims
for( int i=trt_dims.nbDims; i<3; ++i ) {
// Pad with unitary dims
++trt_dims.nbDims;
trt_dims.d[i] = 1;
trt_dims.type[i] = (i == 0 ?
nvinfer1::DimensionType::kCHANNEL :
nvinfer1::DimensionType::kSPATIAL);
}
ASSERT_INPUT(trt_dims.nbDims <= 3, ErrorCode::kUNSUPPORTED_NODE, input.name());
#endif // NV_TENSORRT_MAJOR < 4
ASSERT_INPUT(*tensor = importer_ctx->network()->addInput(
input.name().c_str(), trt_dtype, trt_dims),
ErrorCode::kUNSUPPORTED_NODE, input.name());
return Status::success();
}
#if 0
Status importInputs(ImporterContext* importer_ctx,
::ONNX_NAMESPACE::GraphProto const& graph,
string_map<TensorOrWeights>* tensors,
uint32_t weights_count,
onnxTensorDescriptorV1 const* weight_descriptors) {
// The weights may come from two sources:
// either Initializer list in onnx graph
// or User specified weight through onnxifi
string_map<::ONNX_NAMESPACE::TensorProto const*> initializer_map;
for( ::ONNX_NAMESPACE::TensorProto const& initializer : graph.initializer() ) {
ASSERT(!initializer_map.count(initializer.name()), ErrorCode::kINVALID_GRAPH);
initializer_map.insert({initializer.name(), &initializer});
}
ASSERT(weights_count == 0 || initializer_map.empty(),
ErrorCode::kINVALID_VALUE);
ASSERT(weights_count == 0 || weight_descriptors, ErrorCode::kINVALID_VALUE);
string_map<onnxTensorDescriptorV1 const*> weight_map;
for (uint32_t i = 0; i < weights_count; ++i) {
onnxTensorDescriptorV1 const* desc = weight_descriptors + i;
ASSERT(weight_map.emplace(desc->name, desc).second,
ErrorCode::kINVALID_VALUE);
}
for( ::ONNX_NAMESPACE::ValueInfoProto const& input : graph.input() ) {
TensorOrWeights tensor;
if( initializer_map.count(input.name()) ) {
::ONNX_NAMESPACE::TensorProto const& initializer = *initializer_map.at(input.name());
ShapedWeights weights;
ASSERT_INPUT(convert_onnx_weights(initializer, &weights),
ErrorCode::kUNSUPPORTED_NODE,input.name());
tensor = weights;
} else if (weight_map.count(input.name())) {
onnxTensorDescriptorV1 const& weight_desc = *weight_map.at(input.name());
ShapedWeights weights;
// We only support grabbing weight from CPU memory now
ASSERT_INPUT(weight_desc.memoryType == ONNXIFI_MEMORY_TYPE_CPU,
ErrorCode::kINVALID_VALUE, input.name());
ASSERT_INPUT(convert_weight_descriptor(weight_desc, &weights),
ErrorCode::kUNSUPPORTED_NODE, input.name());
tensor = weights;
} else {
nvinfer1::ITensor* tensor_ptr;
TRT_CHECK(importInput(importer_ctx, input, &tensor_ptr));
tensor = tensor_ptr;
}
ASSERT_INPUT(!tensors->count(input.name()), ErrorCode::kINVALID_GRAPH,input.name());
tensors->insert({input.name(), tensor});
}
return Status::success();
}
#else
Status importInputs(ImporterContext* importer_ctx,
::ONNX_NAMESPACE::GraphProto const& graph,
string_map<TensorOrWeights>* tensors,
uint32_t weights_count,
onnxTensorDescriptorV1 const* weight_descriptors,
string_map<::ONNX_NAMESPACE::TensorProto const*> &initializer_map) {
// The weights may come from two sources:
// either Initializer list in onnx graph
// or User specified weight through onnxifi
//string_map<::ONNX_NAMESPACE::TensorProto const*> initializer_map;
for( ::ONNX_NAMESPACE::TensorProto const& initializer : graph.initializer() ) {
ASSERT(!initializer_map.count(initializer.name()), ErrorCode::kINVALID_GRAPH);
initializer_map.insert({initializer.name(), &initializer});
}
ASSERT(weights_count == 0 || initializer_map.empty(),
ErrorCode::kINVALID_VALUE);
ASSERT(weights_count == 0 || weight_descriptors, ErrorCode::kINVALID_VALUE);
string_map<onnxTensorDescriptorV1 const*> weight_map;
for (uint32_t i = 0; i < weights_count; ++i) {
onnxTensorDescriptorV1 const* desc = weight_descriptors + i;
ASSERT(weight_map.emplace(desc->name, desc).second,
ErrorCode::kINVALID_VALUE);
}
for( ::ONNX_NAMESPACE::ValueInfoProto const& input : graph.input() ) {
TensorOrWeights tensor;
if( initializer_map.count(input.name()) ) {
::ONNX_NAMESPACE::TensorProto const& initializer = *initializer_map.at(input.name());
ShapedWeights weights;
ASSERT_INPUT(convert_onnx_weights(initializer, &weights),
ErrorCode::kUNSUPPORTED_NODE,input.name());
tensor = weights;
} else if (weight_map.count(input.name())) {
onnxTensorDescriptorV1 const& weight_desc = *weight_map.at(input.name());
ShapedWeights weights;
// We only support grabbing weight from CPU memory now
ASSERT_INPUT(weight_desc.memoryType == ONNXIFI_MEMORY_TYPE_CPU,
ErrorCode::kINVALID_VALUE, input.name());
ASSERT_INPUT(convert_weight_descriptor(weight_desc, &weights),
ErrorCode::kUNSUPPORTED_NODE, input.name());
tensor = weights;
} else {
nvinfer1::ITensor* tensor_ptr;
TRT_CHECK(importInput(importer_ctx, input, &tensor_ptr));
tensor = tensor_ptr;
}
ASSERT_INPUT(!tensors->count(input.name()), ErrorCode::kINVALID_GRAPH,input.name());
tensors->insert({input.name(), tensor});
}
return Status::success();
}
#endif
NodeImportResult ModelImporter::importNode(::ONNX_NAMESPACE::NodeProto const& node,
std::vector<TensorOrWeights>& inputs,
std::vector<std::string>& output_names) {
if( !_op_importers.count(node.op_type()) ) {
return MAKE_ERROR("No importer registered for op: " + node.op_type(),
ErrorCode::kUNSUPPORTED_NODE);
}
NodeImporter const& node_importer = _op_importers.at(node.op_type());
std::vector<TensorOrWeights> outputs;
GET_VALUE(node_importer(&_importer_ctx, node, inputs), &outputs);
ASSERT(outputs.size() <= (size_t)node.output().size(), ErrorCode::kINTERNAL_ERROR);
// Check if output's node name is a graph's output.
bool is_graph_output = false;
for (size_t i = 0; i < (size_t)node.output().size(); i++)
{
for (size_t j = 0; j < output_names.size(); j++)
{
if (node.output(i) == output_names[j])
{
is_graph_output = true;
break;
}
}
}
for( size_t i=0; i<outputs.size(); ++i ) {
std::string node_output_name = node.output(i);
TensorOrWeights& output = outputs.at(i);
if( output ) {
if( output.is_tensor() ) {
output.tensor().setName(node_output_name.c_str());
}
else
{
// If a Weights object is a graph output, convert it into a tensor.
if (is_graph_output)
{
outputs.at(i) = TensorOrWeights(&convert_output_weight_to_tensor(output, &_importer_ctx));
TensorOrWeights& output = outputs.at(i);
output.tensor().setName(node_output_name.c_str());
}
}
}
}
return outputs;
}
Status deserialize_onnx_model(void const* serialized_onnx_model,
size_t serialized_onnx_model_size,
bool is_serialized_as_text,
::ONNX_NAMESPACE::ModelProto* model) {
google::protobuf::io::ArrayInputStream raw_input(serialized_onnx_model,
serialized_onnx_model_size);
if( is_serialized_as_text ) {
ASSERT(google::protobuf::TextFormat::Parse(&raw_input, model),
ErrorCode::kMODEL_DESERIALIZE_FAILED);
} else {
google::protobuf::io::CodedInputStream coded_input(&raw_input);
// Note: This WARs the very low default size limit (64MB)
coded_input.SetTotalBytesLimit(std::numeric_limits<int>::max(),
std::numeric_limits<int>::max() / 4);
ASSERT(model->ParseFromCodedStream(&coded_input),
ErrorCode::kMODEL_DESERIALIZE_FAILED);
}
return Status::success();
}
Status deserialize_onnx_model(int fd,
bool is_serialized_as_text,
::ONNX_NAMESPACE::ModelProto* model) {
google::protobuf::io::FileInputStream raw_input(fd);
if( is_serialized_as_text ) {
ASSERT(google::protobuf::TextFormat::Parse(&raw_input, model),
ErrorCode::kMODEL_DESERIALIZE_FAILED);
} else {
google::protobuf::io::CodedInputStream coded_input(&raw_input);
// Note: This WARs the very low default size limit (64MB)
coded_input.SetTotalBytesLimit(std::numeric_limits<int>::max(),
std::numeric_limits<int>::max()/4);
ASSERT(model->ParseFromCodedStream(&coded_input),
ErrorCode::kMODEL_DESERIALIZE_FAILED);
}
return Status::success();
}
bool ModelImporter::parseFromFile(const char* onnxModelFile, int verbosity) {
GOOGLE_PROTOBUF_VERIFY_VERSION;
::ONNX_NAMESPACE::ModelProto onnx_model;
bool is_binary = common::ParseFromFile_WAR(&onnx_model, onnxModelFile);
if (!is_binary && !common::ParseFromTextFile(&onnx_model, onnxModelFile))
{
cerr << "Failed to parse ONNX model from file "<< onnxModelFile << endl;
return EXIT_FAILURE;
}
if (verbosity >= (int) nvinfer1::ILogger::Severity::kWARNING)
{
int64_t opset_version = (onnx_model.opset_import().size() ? onnx_model.opset_import(0).version() : 0);
cout << "----------------------------------------------------------------" << endl;
cout << "Input filename: " << onnxModelFile << endl;
cout << "ONNX IR version: " << common::onnx_ir_version_string(onnx_model.ir_version()) << endl;
cout << "Opset version: " << opset_version << endl;
cout << "Producer name: " << onnx_model.producer_name() << endl;
cout << "Producer version: " << onnx_model.producer_version() << endl;
cout << "Domain: " << onnx_model.domain() << endl;
cout << "Model version: " << onnx_model.model_version() << endl;
cout << "Doc string: " << onnx_model.doc_string() << endl;
cout << "----------------------------------------------------------------" << endl;
}
if (onnx_model.ir_version() > ::ONNX_NAMESPACE::IR_VERSION)
{
cerr << "WARNING: ONNX model has a newer ir_version ("
<< common::onnx_ir_version_string(onnx_model.ir_version())
<< ") than this parser was built against ("
<< common::onnx_ir_version_string(::ONNX_NAMESPACE::IR_VERSION) << ")." << endl;
}
// Read input file
std::ifstream onnx_file(onnxModelFile, std::ios::binary | std::ios::ate);
std::streamsize file_size = onnx_file.tellg();
onnx_file.seekg(0, std::ios::beg);
std::vector<char> onnx_buf(file_size);
// Handle error messages when parsing has failed
if (!onnx_file.read(onnx_buf.data(), onnx_buf.size()))
{
cerr << "ERROR: Failed to read from file " << onnxModelFile << endl;
return false;
}
// If the parsing hits an assertion, print failure information
if (!parse(onnx_buf.data(), onnx_buf.size()))
{
int nerror = getNbErrors();
for (int i = 0; i < nerror; ++i)
{
nvonnxparser::IParserError const* error = getError(i);
if (error->node() != -1)
{
::ONNX_NAMESPACE::NodeProto const& node = onnx_model.graph().node(error->node());
cerr << "While parsing node number " << error->node()
<< " [" << node.op_type();
if (node.output().size() && verbosity >= (int) nvinfer1::ILogger::Severity::kINFO)
{
cerr << " -> \"" << node.output(0) << "\"";
}
cerr << "]:" << endl;
cerr << (int) nvinfer1::ILogger::Severity::kINFO << endl;
if (verbosity >= (int) nvinfer1::ILogger::Severity::kINFO)
{
cout << "--- Begin node ---" << endl;
cout << node << endl;
cout << "--- End node ---" << endl;
}
}
cerr << "ERROR: "
<< error->file() << ":" << error->line()
<< " In function " << error->func() << ":\n"
<< "[" << static_cast<int>(error->code()) << "] " << error->desc()
<< endl;
}
return false;
}
// Parsing success
if (verbosity >= (int) nvinfer1::ILogger::Severity::kINFO)
{
cout << " ----- Parsing of ONNX model " << onnxModelFile << " is Done ---- " << endl;
}
return true;
}
bool ModelImporter::supportsModel(void const *serialized_onnx_model,
size_t serialized_onnx_model_size,
SubGraphCollection_t &sub_graph_collection) {
::ONNX_NAMESPACE::ModelProto model;
bool is_serialized_as_text = false;
Status status =
deserialize_onnx_model(serialized_onnx_model, serialized_onnx_model_size,
is_serialized_as_text, &model);
if (status.is_error()) {
_errors.push_back(status);
return false;
}
bool newSubGraph(true), allSupported(true);
// Parse the graph and see if we hit any parsing errors
allSupported = parse(serialized_onnx_model, serialized_onnx_model_size);
size_t error_node = std::numeric_limits<size_t>::max();
std::string input_node = "";
if (!allSupported)
{
int nerror = getNbErrors();
for (int i = 0; i < nerror; ++i)
{
nvonnxparser::IParserError const* error = getError(i);
if (error->node() != -1)
{
cout << "Found unsupport node: " << error->node() << endl;
error_node = error->node();
allSupported = false;
}
// The node that we failed on is one of the input nodes (-1). Get the name of the input node
// that we failed on and remove all nodes that spawn out of it.
else
{
// Node name is extracted through error->file as all errors thrown on input nodes are wrapped
// around MAKE_INPUT_ERROR.
cout << "Found unsupported input: " << error->file() << endl;
input_node = error->file();
}
}
}
// Sort and partition supported subgraphs
NodesContainer_t topological_order;
if (!toposort(model.graph().node(), &topological_order)) {
cout << "Failed to sort model topologically, exiting ..." << endl;
return false;
}
for (int node_idx : topological_order)
{
::ONNX_NAMESPACE::NodeProto const& node = model.graph().node(node_idx);
// Check for connecting nodes to faulty input nodes and mark them as unsupported
bool contains_input = (input_node == "") ? false : check_for_input(node, input_node);
if (this->supportsOperator(node.op_type().c_str()) && !contains_input)
{
if (newSubGraph)
{
// If it is the beginning of a new subGraph, we start a new vector
sub_graph_collection.emplace_back();
// Mark all new graphs as "unknown"
sub_graph_collection.back().second = false;
newSubGraph = false;
}
// We add the new node to the last graph
sub_graph_collection.back().first.emplace_back(node_idx);
}
else
{
// This is not a supported node, reset the newSubGraph
newSubGraph = true;
allSupported = false;
}
}
if (!allSupported)
{
// We hit some errors when parsing. Iterate through them to find the failing node.
int nerror = getNbErrors();
for (int i = 0; i < nerror; ++i)
{
nvonnxparser::IParserError const* error = getError(i);
if (error->node() != -1)
{
error_node = error->node();
allSupported = false;
}
// The node that we failed on is one of the input nodes (-1). Since TRT cannot parse the
// inputs return false.
else
{
return allSupported;
}
}
// Update the subgraph collection.
for (size_t graph_index = 0; graph_index < sub_graph_collection.size(); graph_index++)
{
NodesContainer_t subgraph = sub_graph_collection[graph_index].first;
// If we've already iterated past the error_node, all future graphs are unknown, so break
if (subgraph[0] > error_node)
{
break;
}
// Mark this subgraph as supported in case we do not touch it.
sub_graph_collection[graph_index].second = true;
for (size_t node_index = 0; node_index < subgraph.size(); node_index++)
{
// Split the graph at the node we hit an assertion at when parsing.
if (subgraph[node_index] == error_node)
{
// Case where subgraph has only one node and it's unsupported, simply delete it.
if (node_index == 0 && subgraph.size() == 1)
{
sub_graph_collection.erase(sub_graph_collection.begin() + graph_index);
}
// Case where subgraph has more than one node and the first node is unsupported. No "split_before" graph.
else if (node_index == 0)
{
NodesContainer_t split_after (subgraph.begin() + node_index + 1, subgraph.end());
sub_graph_collection[graph_index].first = split_after;
}
// Case where subgraph has more than one node and the last node is unsupported. No "split_after" graph.
else if (node_index == subgraph.size() - 1)
{
NodesContainer_t split_before (subgraph.begin(), subgraph.begin() + node_index);
sub_graph_collection[graph_index].first = split_before;
sub_graph_collection[graph_index].second = true;
}
// Case where unsupported node is somewhere in the middle. Split the subgraph at that point into two.
else
{
NodesContainer_t split_before (subgraph.begin(), subgraph.begin() + node_index);
NodesContainer_t split_after (subgraph.begin() + node_index + 1, subgraph.end());
sub_graph_collection[graph_index].first = split_before;
sub_graph_collection[graph_index].second = true;
sub_graph_collection.insert(sub_graph_collection.begin() + graph_index + 1, std::make_pair(split_after, false));
}
break;
}
}
}
}
// After everything if allSupported is true, there is only one subgraph so mark it as supported.
if (allSupported)
{
sub_graph_collection.back().second = true;
}
return allSupported;
}
bool ModelImporter::supportsOperator(const char* op_name) const {
return _op_importers.count(op_name);
}
bool ModelImporter::parseWithWeightDescriptors(
void const *serialized_onnx_model, size_t serialized_onnx_model_size,
uint32_t weight_count, onnxTensorDescriptorV1 const *weight_descriptors) {
_current_node = -1;
// TODO: This function (and its overload below) could do with some cleaning,
// particularly wrt error handling.
// Note: We store a copy of the model so that weight arrays will persist
_onnx_models.emplace_back();
::ONNX_NAMESPACE::ModelProto &model = _onnx_models.back();
bool is_serialized_as_text = false;
Status status =
deserialize_onnx_model(serialized_onnx_model, serialized_onnx_model_size,
is_serialized_as_text, &model);
if (status.is_error()) {
_errors.push_back(status);
return false;
}
status = this->importModel(model, weight_count, weight_descriptors);
if (status.is_error()) {
status.setNode(_current_node);
_errors.push_back(status);
return false;
}
return true;
}
bool ModelImporter::parse(void const *serialized_onnx_model,
size_t serialized_onnx_model_size) {
return this->parseWithWeightDescriptors(
serialized_onnx_model, serialized_onnx_model_size, 0, nullptr);
}
Status
ModelImporter::importModel(::ONNX_NAMESPACE::ModelProto const &model,
uint32_t weight_count,
onnxTensorDescriptorV1 const *weight_descriptors) {
_importer_ctx.clearOpsets();
for( int i=0; i<model.opset_import().size(); ++i ) {
std::string domain = model.opset_import(i).domain();
int64_t version = model.opset_import(i).version();
_importer_ctx.addOpset(domain, version);
}
::ONNX_NAMESPACE::GraphProto const& graph = model.graph();
std::vector<std::string>output_names;
int num_outputs = model.graph().output_size();
for (int i = 0; i < num_outputs; i++)
{
output_names.push_back(model.graph().output(i).name());
}
string_map<TensorOrWeights> tensors;
string_map<::ONNX_NAMESPACE::TensorProto const*> initializer_map;
TRT_CHECK(importInputs(&_importer_ctx, graph, &tensors, weight_count,
weight_descriptors, initializer_map));
std::vector<size_t> topological_order;
ASSERT(toposort(graph.node(), &topological_order), ErrorCode::kINVALID_GRAPH);
for( size_t node_idx : topological_order ) {
_current_node = node_idx;
::ONNX_NAMESPACE::NodeProto const& node = graph.node(node_idx);
std::vector<TensorOrWeights> inputs;
for( auto const& input_name : node.input() ) {
///////////////////////////////////
ASSERT(tensors.count(input_name) || initializer_map.count(input_name), ErrorCode::kINVALID_GRAPH);
if(tensors.count(input_name) == 0)
{
TensorOrWeights tensor;
::ONNX_NAMESPACE::TensorProto const& initializer = *initializer_map.at(input_name);
ShapedWeights weights;
ASSERT_INPUT(convert_onnx_weights(initializer, &weights), ErrorCode::kUNSUPPORTED_NODE, input_name);
tensor = weights;
inputs.push_back(tensor);
tensors.insert({input_name, tensor});
}
else
{
inputs.push_back(tensors.at(input_name));
}
///////////////////////////////////
//ASSERT(tensors.count(input_name), ErrorCode::kINVALID_GRAPH);
//inputs.push_back(tensors.at(input_name));
}
std::vector<TensorOrWeights> outputs;
GET_VALUE(this->importNode(node, inputs, output_names), &outputs);
for( size_t i=0; i<outputs.size(); ++i ) {
std::string node_output_name = node.output(i);
TensorOrWeights& output = outputs.at(i);
// Note: This condition is to allow ONNX outputs to be ignored
if( output ) {
ASSERT(!tensors.count(node_output_name), ErrorCode::kINVALID_GRAPH);
tensors.insert({node_output_name, output});
}
}
if( node.output().size() > 0 ) {
std::stringstream ss;
ss << node.output(0) << ":"
<< node.op_type() << " -> "
<< outputs.at(0).shape();
_importer_ctx.logger().log(
nvinfer1::ILogger::Severity::kINFO, ss.str().c_str());
}
}
_current_node = -1;
// Mark outputs defined in the ONNX model (unless tensors are user-requested)
for( ::ONNX_NAMESPACE::ValueInfoProto const& output : graph.output() ) {
ASSERT(tensors.count(output.name()), ErrorCode::kINVALID_GRAPH);
ASSERT(tensors.at(output.name()).is_tensor(), ErrorCode::kUNSUPPORTED_GRAPH);
nvinfer1::ITensor* output_tensor_ptr = &tensors.at(output.name()).tensor();
if( output_tensor_ptr->isNetworkInput() ) {
// HACK WAR for TRT not allowing input == output
// TODO: Does this break things by changing the name of the input tensor?
output_tensor_ptr->setName(("__" + output.name()).c_str());
output_tensor_ptr = &identity(&_importer_ctx, output_tensor_ptr).tensor();
ASSERT(output_tensor_ptr, ErrorCode::kUNSUPPORTED_NODE);
output_tensor_ptr->setName(output.name().c_str());
}
nvinfer1::ITensor** user_output = _importer_ctx.getUserOutput(output.name().c_str());
if( !user_output ) {
_importer_ctx.network()->markOutput(*output_tensor_ptr);
nvinfer1::DataType output_trt_dtype;
ASSERT(convert_dtype(
output.type().tensor_type().elem_type(), &output_trt_dtype),
ErrorCode::kUNSUPPORTED_NODE);
#if NV_TENSORRT_MAJOR >= 4
// For INT32 data type, output type must match tensor type
ASSERT(output_tensor_ptr->getType() != nvinfer1::DataType::kINT32 ||
output_trt_dtype == nvinfer1::DataType::kINT32,
ErrorCode::kUNSUPPORTED_NODE);
#endif // NV_TENSORRT_MAJOR >= 4
// Note: Without this, output type is always float32
output_tensor_ptr->setType(output_trt_dtype);
}
}
// Return user-requested output tensors
for( auto user_output_entry : _importer_ctx.getUserOutputs() ) {
std::string user_output_name = user_output_entry.first;
nvinfer1::ITensor** user_output_ptr = user_output_entry.second;
ASSERT(tensors.count(user_output_name), ErrorCode::kINVALID_VALUE);
TensorOrWeights user_output = tensors.at(user_output_name);
ASSERT(user_output.is_tensor(), ErrorCode::kINVALID_VALUE);
*user_output_ptr = &user_output.tensor();
}
return Status::success();
}
} // namespace onnx2trt
