1.什么是分词
分词就是指将一个文本转化成一系列单词的过程,也叫文本分析,在Elasticsearch中称之为Analysis。
举例:我是中国人 --> 我/是/中国人
2.分词api
#指定分词器进行分词
POST /_analyze
{
"analyzer": "standard",
"text": "hello world"
}
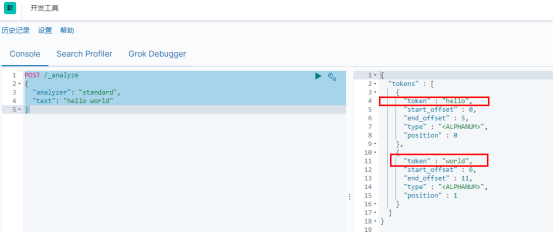
在结果中不仅可以看出分词的结果,还返回了该词在文本中的位置。
#指定索引分词
POST /itcast/_analyze
{
"analyzer": "standard",
"field": "hobby",
"text": "听音乐"
}

3.中文分词
常用中文分词器,IK、jieba、THULAC等,推荐使用IK分词器。
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IK Analyzer 3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
采用了特有的“正向迭代最细粒度切分算法“,具有80万字/秒的高速处理能力 采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。 优化的词典存储,更小的内存占用。
IK分词器 Elasticsearch插件下载地址:https://github.com/medcl/elasticsearch-analysis-ik
#安装方法
#三台elasticsearch主机都要配置
#cd /usr/share/elasticsearch/plugins
#mkdir -pv ik
#unzip elasticsearch-analysis-ik-7.2.0.zip
#ll
#重启elasticsearch
#systemctl restart elasticsearch
#测试
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
