分词器顾名思义,就是对文本分词。目前es给我们提供了standard(对西方语言比较好),icu(对东南亚等地区),ik(中文),还有一些不常用的如,Letter Tokenizer(对非字符切分),whitespace Analyzer(每当遇到whitespace分割)。
分词器种类:
- Standard: 单字切分法,一个字切分成一个词。 (es默认分词器)
- CJKAnalyzer: 二元切分法, 把相邻的两个字, 作为一个词.
- SmartChineseAnalyzer: 对中文支持较好, 但是扩展性差, 针对扩展词库、停用词均不好处理.
- paoding`: 庖丁解牛分词器, 没有持续更新, 只支持到lucene3.0。
- mmseg4`: 支持Lucene4.10, 且在github中有持续更新, 使用的是mmseg算法.
- Whitespace分词器:去除空格,不支持中文,对生成的词汇单元不进行其他标准化处理。
- language分词器:特定语言的分词器,不支持中文。
- IK-analyzer: 最受欢迎的中文分词器。
安装IK-analyzer
- 下载ik中文分词器
- 解压到/usr/share/elasticsearch/plugins/ik目录
unzip elasticsearch-analysis-ik-7.9.3.zip -d /data/local/elasticsearch/9200/plugins/ik
3. 重启elasticsearch
4.测试分词效果
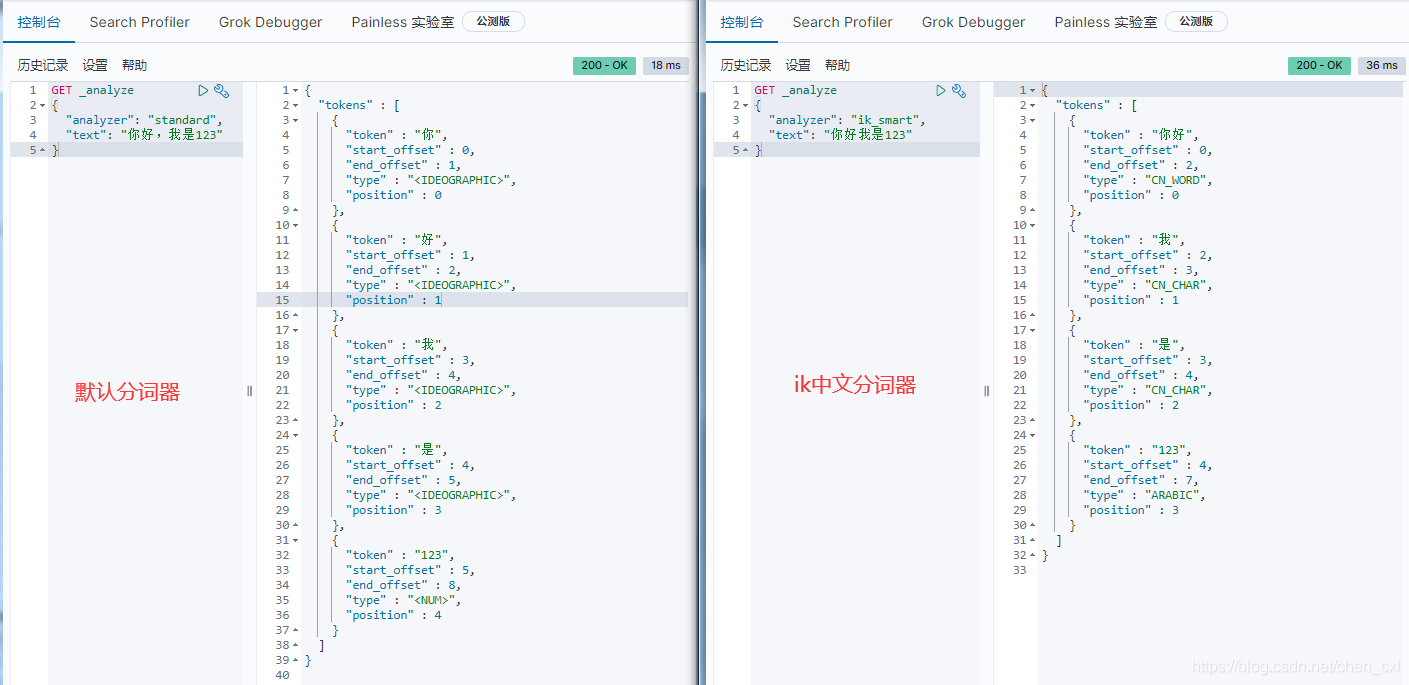
使用IK-analyzer
索引时用ik_max_word(细粒度)
#建立索引时使用ik_max_word分词
PUT _template/request_log
{
"index": {
"refresh_interval": "5s",
"analysis": {
"analyzer": {
"ik": {
"tokenizer": "ik_max_word"
}
}
}
}
}
单个字段设置分词器
"字段名称": {
"type": "text",
"analyzer": "ik_max_word"
}
在搜索时用ik_smart(粗粒度)
GET /request_log-app-2020.06.08/_search
{
"query": {
"match_phrase" : {
"operation" : {
"query" : "发货",
"analyzer" : "ik_smart"
}
}
}
}
相关命令
#测试分词结果
GET _analyze
{
"analyzer": "ik_smart", //指定分词器
"text": ["要测试的字符串"]
}
#获取document中的某个field内的各个term的统计信息。
GET /索引/_termvectors/文档id
{
"fields":["字段1"]
}