线性可分
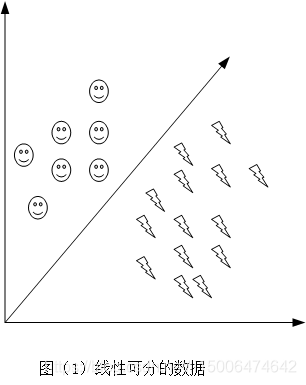
SVM关于二分类问题的算法,也就是将一组数据线性的分成两类,什么是线性的分成两类呢?就是像图(1)这样的数据用一条线可以进行一分为二。
像图(2)这种数据使用一条线是分不开的,那么这种数据就成为线性不可分的数据,对于这种数据SVM就没有办法了吗?当然有办法了不然也不会在早期这么流行的。

SVM
margin的概念
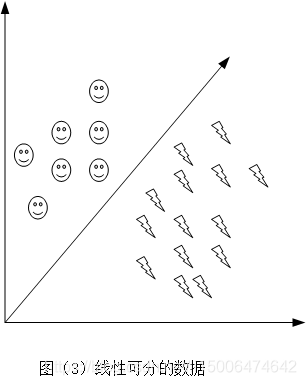
假设现在有这样一组数据,
D={(x1,y1),(x2,y2),(x3,y3)...(xn,yn)},其中
x表示数据,
y表示对应的标签,
y∈{1,−1}现在用图(3)来表示:
现在用一条线来区分,假设这条线为:
WTxi+b来表示,也就是说
WTxi+b≥0时
,y=1,
WTxi+b≤0时
,y=−1也可以用
(WTxi+b)⋅y≥0来表示。
图(4)表示的是我们使用了 ①,②和③条作为决策边界来进行将数据分类,从图中我们明显看到这三条线都成功的将数据进行了分类,但是那个分类的最好呢,答案是②,①和③距离数据太近了,有可能造成误判,并且很容易过拟合,对于②来说我们离数据的距离比较远,增加一些噪音的话也是可以保证分类的正确性。
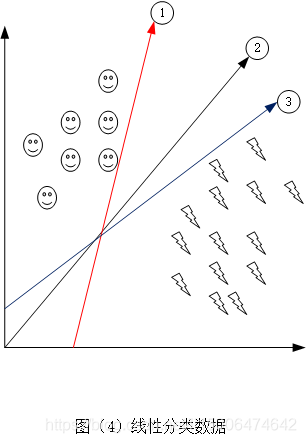
因此我们通常把这个距离叫做margin。我们的分类器离数据的距离越大越好,所以margin的目标就是最大化margin。
margin的计算
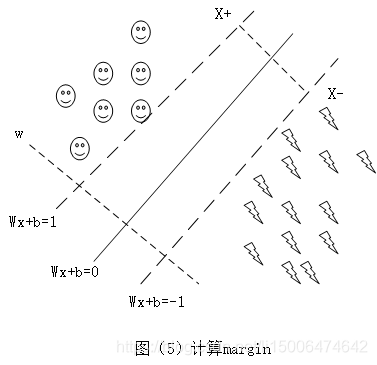
那么margin该怎么计算呢?由图(5)我们可以看到
Wx+b=0表示决策边界另外我们设置两条线
WTx+b=1和
WTx+b=−1表示分别表示数据集中最外围,所以margin就是这两条线之间的距离,这里因为有
W和b的存在,所以我们将其设置为1和-1
假设
x+表示
WTx+b=1上的点,
x−表示
WTx+b=−1上的点,
margin=∣x+−x−∣,
w表示与这三条线垂直的方向
我们可以得到三个公式:
⎩⎪⎨⎪⎧WTx++b=1①WTx−+b=−1②x+=x−+λw③
现在我们来计算
margin将③式代入①中得:
WT(x−+λw)+b=1
WTx−+WTλw+b=1④
将④-②得
λWTw=2
λ=WTw2
margin=∣x+−x−∣由③可知:
margin=∣λw∣=∣WTw2⋅w∣=∣WT2∣
所以最后
margin=∣WT2∣
SVM的目标函数
svm的目标就是最大化
margin也就是:
maxmize∣∣WT∣∣2
st:WTx+b≥1if:y=1
WTx+b≤−1if:y=−1
我们来简单改变一下公式:
minemize∣∣WT∣∣2
st:WTx+b≥1if:y=1
WTx+b≤−1if:y=−1
把条件整合一下
minemize∣∣WT∣∣2
st:(WTx+b)⋅y≥1
这个就是SVM的目标函数
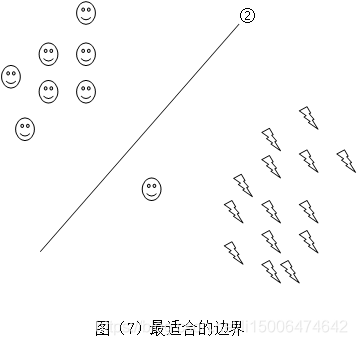
但是现在有一个问题:现实情况下往往会出现如图(6)

这种情况按照我们的算法最后计算出来的边界是①,但是我们可以看出其实 ①并不是最适合的,往往图(7)中的②才是最适合的
也就是说在svm算法中我们允许一些误差的存在,如图(8)
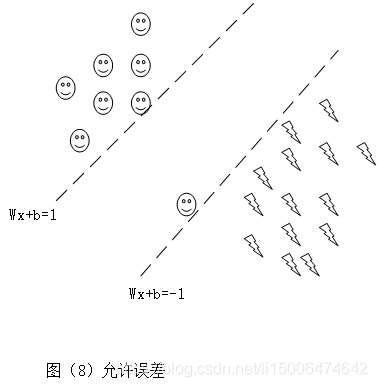
在margin范围内存在一些误差:
所以我们软化SVM的目标函数:
软化SVM的目标函数
minemize∣∣WT∣∣2
st:(WTxi+b)⋅yi≥1−εi
εi≥0
εi表示误差的程度
虽然我们允许有误差,但是我们也不能让误差太多了,所以我们在公式中增加了
ε正则项:
minemize∣∣WT∣∣2+λ∑i=1nεi
st:(WTxi+b)⋅yi≥1−εi
εi≥0
当然了我们希望误差越小越好所以根据:
(WTxi+b)⋅yi≥1−εi
我们可以得出:
εi≥1−(WTxi+b)⋅yi
也就是说:
εi最小为
1−(WTxi+b)⋅yi所以我们确保:
εi=1−(WTxi+b)⋅yi也就保证了误差最小,那么我们把这种信息放到公式里:
minemize∣∣WT∣∣2+λ∑i=1nmax[0,1−(WTxi+b)⋅yi]
如果
εi小于0的时候为0,大于0的时候为
1−(WTxi+b)⋅yi
这里的
λ也就是超参数,如果
λ特别大的话,那么我们要求的误差就越小。
max[0,1−(WTxi+b)⋅yi]也就是比较有名的hinge-loss
梯度下降优化参数
这样我们做梯度下降的时候就得判断一下
梯度下降法:
w,b的初始化
循环:1…n:
if1−(WTxi+b)≤0:
W=W−η2W
else:
W=W−η(2W+λ∂W∂(1−(WTxi+b)))
b=b−η(λ∂b∂(1−(WTxi+b)))
你以为就这样完啦?No NO nO 现在这种算法只能计算线性可分的数据,我在开头说了,它也可以计算非线性的数据,下面计算一下SVM的由primal-form到dual-form
SVM的由primal-form到dual-form
primal-form指的是用正常的逻辑思维进行构建的目标函数,那么为什么转换到dual-form(对偶的问题)一般情况下有两种原因:
1、primal-form的问题比较难以解决因此转换到dual-form
2、在dual-form中可以看到一些有趣的现象
在SVM中我们使用dual-form主要是因为传统的primal-form没有办法计算非线性的数据
假设我们遇到一个非线性的数据我们有两种解决方式
1、放弃SVM模型使用非线性模型:神经网络
2、将数据映射到高维然后进行线性分类
那么将数据映射到高维怎么能先行可分呢?如图(9)

有些数据在二维的时候并不能线性可分,我们将数据映射到三维甚至更高的的时候就可以了:
这就是一种把数据映射到高维的形式;
x=(x1x2)⇒u⎝⎜⎜⎜⎜⎛x1x2x2+x1x1− x2x1⋅x2⎠⎟⎟⎟⎟⎞
但是这样构建模型就有一个问题:
假设原来的复杂度:O(n),那么映射到100维那么计算的复杂度将是原来的100倍所以为了解决这个问题我们使用了kernel Trick
首先我们将SVM由primal-form转变成dual-form
拉格朗日等号和不等号的处理
对于等号:
minf(x)
st.g(x)=0
因为在求f(x)的最优解时一定是
∇f(x)∣∣∇g(x)因此
∇f(x)=λ∇g(x)
可以直接写成
minf(x)+λg(x)
因此
minf(x)
st.gi(x)=0i=1,2,3...n
直接写成
minf(x)+∑i=1nλigi(x)
这是根据拉格朗日的定理
对于不等号:
minf(x)
st.h(x)≤0
对于不等号的处理一般有两种方式:
1、没有限制条件下的最优解正好满足
h(x)≤0
这个时候我们就直接
minf(x)的结果接可以了,我们也可以写成:
minf(x)+λh(x)
此时
λ=0
h(x)≤0
2、没有限制条件下的最优解不满足满足
h(x)≤0
这个时候的最优解只能是当
h(x)=0的时候了也就是:
minf(x)+λh(x)
此时
λ≥0
h(x)=0
我们将两者的情况结合起来就是
λ⋅h(x)=0
也就是:
minf(x)+λh(x)
st.
λ⋅h(x)=0
KKT条件
假设我们现在有这样的一个公式:
minf(x)
st.h(x)j≤0j=1,2,3...n
gi(x)=0i=1,2,3...n
我们可以写成:
minf(x)+∑i=1nλigi(x)++∑j=1nMjhj(x)
st.λi,Mj≥0
Mjhj(x)=0,∀j
hj(x)≤0,∀j
上面就是比较有名的KKT条件
SVM对应的KKT条件
这个是上面我们讨论的SVM硬目标函数(不允许有误差)
minemize∣∣WT∣∣2
st:(WTx+b)⋅y≥1
我们可以转变一下:
minemize21∣∣WT∣∣2
st:1−(WTx+b)⋅y≤0
根据拉格朗日不等式的处理过程:
min21∣∣W∣∣2+∑i=1nλi[1−(WTxi+b)⋅yi]
st.λi≥0
λi[1−(WTxi+b)⋅yi]=0,∀i
1−(WTxi+b)⋅yi≤0,∀i
SVM的dual-form
上面我们已经得到SVM的KKT表达式:
min21∣∣W∣∣2+∑i=1nλi[1−(WTxi+b)⋅yi]
我们先来求出此时的梯度:
∂w∂L=0⇒W−∑i=1nλiyixi=0⇒W=∑i=1nλiyixi
∂b∂L=0⇒∑i=1nλiy=0
由上式我们可以知道:
21∣∣W∣∣2=21WT⋅W=21(∑i=1nλiyixi)⋅(∑j=1nλjyjxj)=21∑i=1n∑j=1nλiλjyiyjxiTxj
∑i=1nλi[1−(WTxi+b)⋅yi=∑i=1nλi−∑i=1nλi(WTxi+b)⋅yi
=∑i=1nλi−∑i=1nλiWTxiyi−∑i=1nλiyib
=∑i=1nλi−∑i=1nλi(∑j=1nλjyjxj)Txiyi=∑i=1nλi−∑i=1n∑j=1nλiλjyiyjxiTxj
因此我们的公式就变成:
min21∣∣W∣∣2+∑i=1nλi[1−(WTxi+b)⋅yi]=−21∑i=1n∑j=1nλiλjyiyjxiTxj+∑i=1nλi
st.λi≥0
λi[1−(WTxi+b)⋅yi]=0,∀i
1−(WTxi+b)⋅yi≤0,∀i
W=∑i=1nλiyixi
∑i=1nλiy=0
上面就是将SVM转换成dual-from的形式
为什么要转换成这个样子呢?或者为什么要这样转换呢?
主要是因为在我们的目的让dual-from的公式中出现了
xiTxj
在上面我们讲过如果我们将公式映射到高维后时间复杂度会增加很多但是将数据写成
xiTxj我们就可以使用Kernel-Trick减少时间复杂度,甚至不增加复杂度:
举个例子:
现在有两个2维向量:
x=(x1,x2),z=(z1,z2)
那么我们计算
xT⋅z=(x1⋅z1+x2⋅z2)
现在我们将向量映射到3维后:
ϕ(x)=(x12,x22,2
x1x2),ϕ(z)=(z12,z22,2
z1z2)
计算
ϕ(x)T⋅ϕ(z)=(x12z12+x22z22,+2x1x2)=(x1⋅z1+x2⋅z2)2=(xT⋅z)2
我们可以很清楚的看出虽然维度增加了但是复杂度还是原来的那个样子。
所以我们现在还有一个任务就是怎么设计
ϕ(x)和ϕ(z)使得
o(ϕ(x)T⋅ϕ(z))≈o(xT⋅z)
这是一个比较复杂的过程啦,感兴趣的话可以自己查阅一下
最后我们将上面公式的推导成带有
xTx的这种形式,也就是;
k(x,y)=xTy,我们称这种为线性核函数,其实还有很多核函数
例如
多项式核(Polynomial Kernel)
k(x,y)=(1+xTy)d
高斯核(Gaussian Kernel)
k(x,y)=e(2σ2−∣∣x−y∣∣2)
