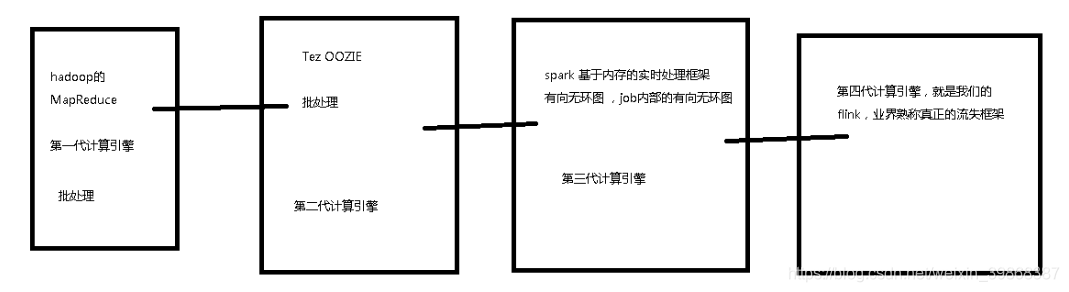
1、大数据计算引擎发展的四个阶段
-
第一代
Hadoop 承载的 MapReduce -
第二代
持 DAG(有向无环图) 的框架: Tez 、 Oozie,主要还是批处理任务 -
第三代
Job 内部的 DAG(有向无环图) 支持(不跨越 Job),以及强调的实时计算:Spark -
第四代
对流计算的支持,以及更一步的实时性:Flink
如图表示:
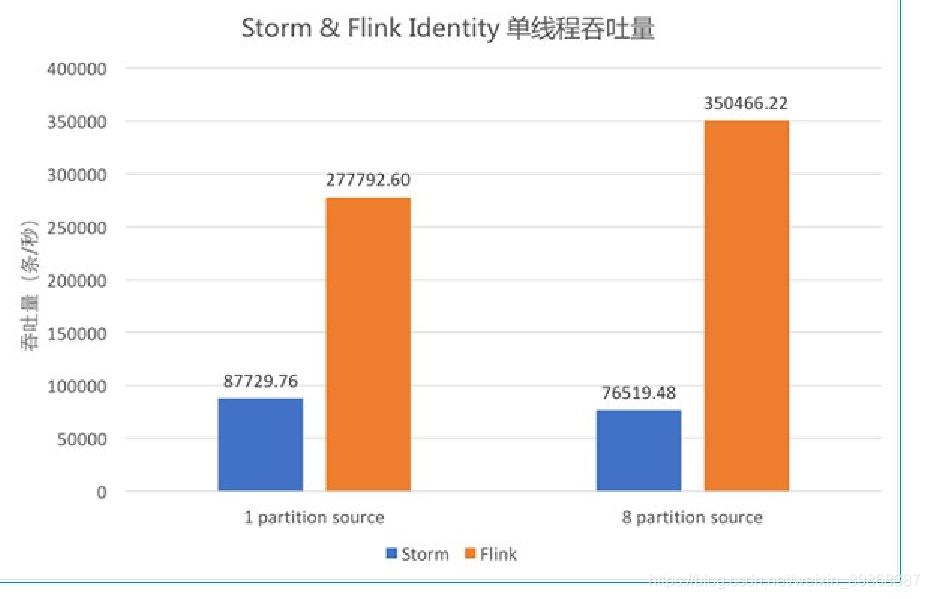
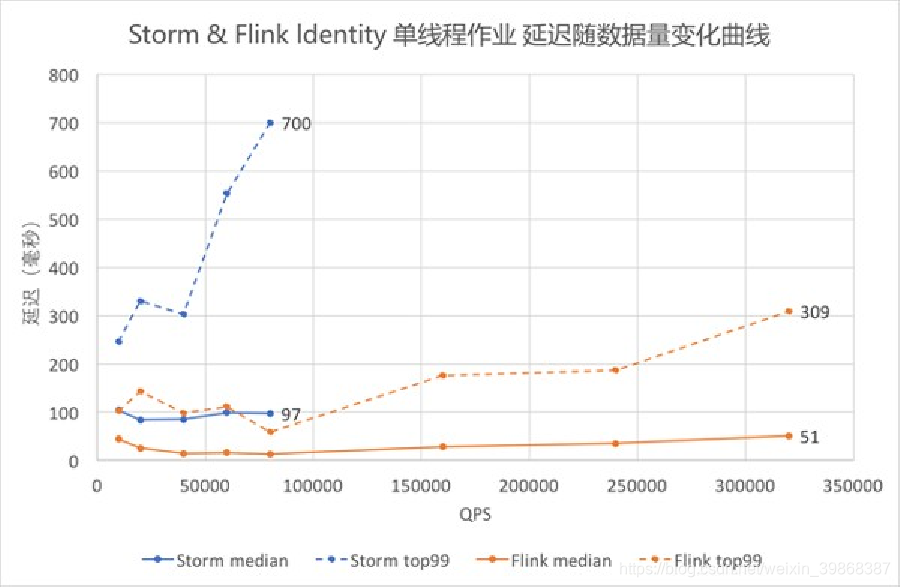
2、flink特性
(1)高吞吐 & 低延时
(2)支持 Event Time & 乱序事件
Flink 支持了流处理和 Event Time 语义的窗口机制。Event time 使得计算乱序到达的事件或可能延迟到达的事件更加简单
(3)高度灵活的流式窗口
Flink 支持在时间窗口,统计窗口,session 窗口,以及数据驱动的窗口,窗口可以通过灵活的触发条件来定制,以支持复杂的流计算模式。
(4)容错性
Flink 的容错机制是基于 Chandy-Lamport distributed snapshots 来实现的。这种机制是非常轻量级的,允许系统拥有高吞吐率的同时还能提供强一致性的保障。
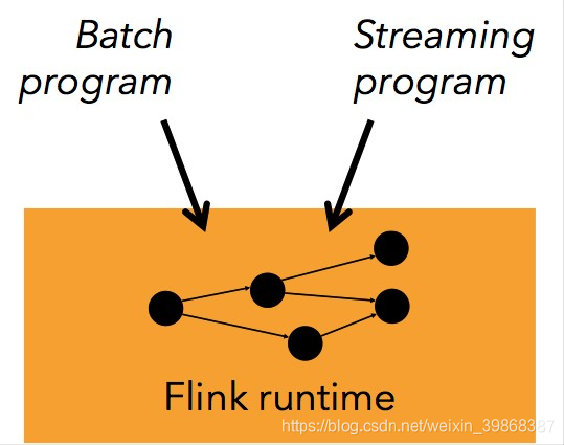
(5)流处理和批处理共用一个引擎
Flink 为流处理和批处理应用公用一个通用的引擎。批处理应用可以以一种特殊的流处理应用高效地运行。
(6)内存管理
Flink 在 JVM 中实现了自己的内存管理。应用可以超出主内存的大小限制,并且承受更少的垃圾收集的开销。
(7)程序调优
批处理程序会自动地优化一些场景,比如避免一些昂贵的操作(如 shuffles 和 sorts),还有缓存一些中间数据。
(8)类库生态
Flink 栈中提供了很多高级 API 和满足不同场景的类库:机器学习、图分析、关系式数据处理
(9)广泛集成
Flink 与开源大数据处理生态系统中的许多项目都有集成。Flink 可以运行在 YARN 上,与 HDFS 协同工作,从 Kafka 中读取流数据,可以执行 Hadoop 程序代码,可以连接多种数据存储系统
3、分析指标
-
频道分析:频道浏览pv,uv,热门频道top10,频道成交分析,频道新鲜度,频道浏览地区分布分析,频道用户群体分析
-
产品分析:产品地区分布分析,产品商家分析,产品浏览top10 产品类别浏览top10 产品成交分析 产品停留时长分析
-
用户分析:用户浏览器使用分析 用户网络分析 用户年龄群里分析 用户地区分布 用户性别分析 新增用户分析 活跃用户分析
-
活动效果分析:活动时间分布分析 活动成交率分析 活动浏览率分析 活动top10 活动用户分布分析 活动浏览地区分布分析
-
营销分析:代金券使用分析 红包使用分析 代金券,红包使用地区分布,代金券,红包使用用户年龄分布分析 代金券,红包使用商家分析
-
购物车分析:用户购物车产品类别分布,用户购物车搁置未购买分析 ,用户购物车产品数量分析,购物车用户地区分布分析,购物车用户年龄分布分析
-
订单分析: