背景
因为没怎么用这个网站导致 为 ,于是只能打 Div 2 了……(虽然我这么菜也肯定是不可能AK的……但是如果能打 Div 1 的话收获肯定会更大的呀)
正题
记录一下前 题的做法吧(包括原 T3),最后一题太神仙了做不动啊啊啊……
T1
发现两个人对战无论哪个人获胜结果都是一样的,因为如果将武器序列看成一个二进制数,那么每一次对战就是两个人异或起来,所以答案就是所有人异或起来之后那个数的二进制下 的个数。
代码:
#include <cstdio>
#include <cstring>
int t,n,ans=0;
char s[20];
inline int lowbit(int x){return x&(-x);}
int main()
{
scanf("%d",&t);
while(t--)
{
scanf("%d",&n);
for(int i=1,x;i<=n;i++)
{
scanf("%s",s);x=0;
for(int j=0;j<10;j++)
x=(x<<1)+(s[j]-'0');
ans^=x;
}
int tot=0;
while(ans>0)ans-=lowbit(ans),tot++;
printf("%d\n",tot);
}
}
T2
这就是一道水题啊……把序列老老实实造出来然后暴力统计答案就好了。
代码:
#include <cstdio>
#include <cstring>
int t,n;
int f[1010],sum[210][210];
int main()
{
f[1]=0;sum[1][0]++;
for(int i=2;i<=128;i++)
{
for(int j=0;j<=200;j++)
sum[i][j]=sum[i-1][j];
if(sum[i][f[i-1]]==1)f[i]=0;
else
{
for(int j=i-2;i>=1;j--)
if(f[j]==f[i-1])
{
f[i]=i-1-j;
break;
}
}
sum[i][f[i]]++;
}
scanf("%d",&t);
while(t--)
{
scanf("%d",&n);
printf("%d\n",sum[n][f[n]]);
}
}
原T3
原本是一道有意思的博弈论题目,但是我在 11.4 再看的时候没有了,因为被发现了原题……
题面大概是这样的:
现在有 行硬币,第 行有 个硬币,给出每个硬币的权值。
现在有 和 两个人轮流取硬币, 先手, 只能拿某一排硬币中最左边的那个, 只能拿最右边的,两人都足够聪明,问 能拿到的最大权值和是多少?
分类讨论:
- 假如 为奇数,那么我们将中间的那个放入堆里,然后左边的部分统计入答案中,也就是肯定会被 拿走的硬币。
- 假如 为偶数,那么我们将左边部分统计入答案。
最后对于堆里面的东西,从大到小一个一个弹出,假如它是第奇数个被弹出的,那么就统计入答案中。
堆的那一个贪心是很好理解的,肯定是选大的更优。但是有人可能会问,为什么每一行硬币都是左边一半归 ,右边一半归 ?
假如不是这样的,那么肯定存在: 牺牲了某一行的一次往后取的机会,然后选择在另一行往后取一个。那么此时 在另一行往后取一个肯定取到了后一半的硬币里面,但是这一半硬币是归 的, 能拿到的条件是 选择不要这个硬币,那么他不要这个硬币肯定是找到了更大的硬币,也就是 舍弃的那个,那么如果 舍弃的那个更大,为什么 还要舍弃它呢?所以这种情况不存在。
代码:
#include <cstdio>
#include <cstring>
#include <set>
#include <algorithm>
using namespace std;
#define maxn 100010
int t,n,a[maxn];
long long ans;
multiset<int>s;
int main()
{
scanf("%d",&t);
s.clear();
while(t--)
{
scanf("%d",&n);ans=0;
for(int i=1,c;i<=n;i++)
{
scanf("%d",&c);
for(int j=1;j<=c;j++)
scanf("%d",&a[j]);
if(c%2==1)s.insert(a[c/2+1]);
for(int j=1;j<=c/2;j++)
ans+=a[j];
}
bool v=true;
while(!s.empty())
{
if(v)ans+=*s.rbegin();
set<int>::iterator p=s.end();
p--;s.erase(p);
v^=1;
}
printf("%lld\n",ans);
}
}
现T3(原T4)
这题真的让我自闭了。
当时一看数据范围:
,那肯定是要在每组数据里面
出解,然后继续往下看,有一句话:the sum of N+M+K over all test cases does not exceed 15,000,英语爆炸的我一想,这不是废话吗?
都不大于
,加起来怎么可能大于
?
然后为了这个 做法,我 yy 了两个半小时。
最后百度翻译一下这句话,翻译出来的结果是:所有测试用例的n+m+k之和不超过15000。
:(
所以是可以跑 的做法的。
那就很简单了。
所以那两个半小时我到底在干嘛
考虑找一下离每个 最近的 ,将他们的距离记为 ,以及离每个 最近的 ,将他们的距离记为 。
然后大力枚举两个点 和 ,计算一下贡献然后求个最小值即可。
代码:
#include <cstdio>
#include <cstring>
#include <cmath>
#include <algorithm>
using namespace std;
#define maxn 5010
int t,n,m,k;
struct point{int x,y;};
point a[maxn],b[maxn],c[maxn];
point st;
double fa[maxn],fb[maxn];
double dis(point x,point y){return sqrt((long long)(x.x-y.x)*(x.x-y.x)+(long long)(x.y-y.y)*(x.y-y.y));}
int main()
{
scanf("%d",&t);
while(t--)
{
scanf("%d %d",&st.x,&st.y);
scanf("%d %d %d",&n,&m,&k);
for(int i=1;i<=n;i++)
scanf("%d %d",&a[i].x,&a[i].y),fa[i]=(1ll<<40);
for(int i=1;i<=m;i++)
scanf("%d %d",&b[i].x,&b[i].y),fb[i]=(1ll<<40);
for(int i=1;i<=k;i++)
scanf("%d %d",&c[i].x,&c[i].y);
for(int i=1;i<=k;i++)
{
for(int j=1;j<=n;j++)
fa[j]=min(fa[j],dis(a[j],c[i]));
for(int j=1;j<=m;j++)
fb[j]=min(fb[j],dis(b[j],c[i]));
}
double ans=(double)(1ll<<50);
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++)
ans=min(ans,min(dis(st,a[i])+dis(a[i],b[j])+fb[j],dis(st,b[j])+dis(b[j],a[i])+fa[i]));
printf("%.10lf\n",ans);
}
}
T4
根据这个染色方法,很容易想到第 个盒子与第 个盒子的颜色一定相同。那么我们不妨将 这些位置上的盒子打包在一起变成一个集合,表示他们的颜色是相同的。
现在我们有 个集合,问题变成:从这 个集合里面各选出一个盒子,使最大的盒子与最小的盒子的差最小。
那么考虑暴力一点的做法:枚举一个最小值,那么在最小值固定的情况下我们肯定要让最大值最小,那么考虑取每一个集合里面最小的但大于等于这个最小值的盒子,这样显然是最优的,这样就有了一个
的
分做法。
这个东西时可以优化的,我们枚举最小值的过程,肯定不是从 枚举到 ,肯定把所有盒子排个序,从小到大枚举,从第 个盒子枚举到第 盒子这个过程中,我们发现,除了第 个盒子所在的集合需要重新选一个数,其他的集合都是不用重新选的,因为它们既然都满足大于第 个盒子,那么也肯定大于第 个盒子,那么我们只需要更改第 个盒子所在的集合取出来的数即可。
这个更改也是可以优化的,不需要每次都取 ,只需要取这个集合里面盒子 的后继就好了,这个用 维护一下即可。
代码:
#include <cstdio>
#include <cstring>
#include <set>
#include <algorithm>
using namespace std;
#define it_int multiset<int>::iterator
#define it_par multiset<par>::iterator
#define maxn 100010
int t,n,m;
multiset<int> s[maxn];
struct par{
it_int x;
int y;
par(it_int xx,int yy):x(xx),y(yy){}
bool operator <(const par &b)const{return *x<*b.x;}
};
multiset<par> d;
int ans;
int main()
{
scanf("%d",&t);
while(t--)
{
scanf("%d %d",&n,&m);
for(int i=1;i<=m;i++)
s[i].clear();
for(int i=1,x;i<=n;i++)
scanf("%d",&x),s[i%m].insert(x);
d.clear();
for(int i=0;i<m;i++)
d.insert(par(s[i].begin(),i));
ans=2147483647;
while(1)
{
it_par x=d.begin(),y=d.end();y--;
if(*(y->x)-*(x->x)<ans)ans=*(y->x)-*(x->x);
it_int p=x->x;p++;if(p==s[x->y].end())break;
int pp=x->y;
d.erase(x);d.insert(par(p,pp));
}
printf("%d\n",ans);
}
}
T5
这题计算答案有点恶心……
如何判断某个字符串是 的还是 的呢?
如果是 的,那么需要满足任意子串中元音数大于辅音数。
这个限制转化一下,就是字符串中不能有形如辅辅或辅元辅的子串,证明很简单,如果没有了形如这样的子串,那么就可以保证两个任意两个辅音中间至少有两个元音,那么就可以保证任意子串中元音数量不少于辅音数量。
那么这样判断一下之后,就可以知道这个字符串是谁的,然后按题目要求统计一下。设
表示
的字符串的
,即
这个字符在多少个字符串中出现过,
表示
的,
和
则表示出现总次数,那么最后答案就是:
然而题目要求精确到小数点后 位输出,要是直接计算的话光是整数部分 都存不下来,用 的话精度都不知道丢了多少了,于是需要优化一下。
考虑对这些东西求 ,那么就可以将乘法变成加法,指数变成乘法,然后最后再逆回去,这样的话精度就比较高了,加上这题也不会卡你,这样就可以AC。
代码:
#include <cstdio>
#include <cstring>
#include <cmath>
int T,L,n,m;
char s[100010];
int tot[2][30],app[2][30];
bool v[30];
int zhan[30],t=0;
bool yuan(char x){return x=='a'||x=='e'||x=='i'||x=='o'||x=='u';}
int ch(char x){return x-'a'+1;}
int main()
{
scanf("%d",&T);
while(T--)
{
scanf("%d",&L);n=m=0;
memset(tot,0,sizeof(tot));
memset(app,0,sizeof(app));
for(int i=1,len;i<=L;i++)
{
scanf("%s",s);
len=strlen(s);
int type=0;//Alice
for(int i=0;i<len-2;i++)
if( (!yuan(s[i])&&!yuan(s[i+1])) ||
(!yuan(s[i])&&yuan(s[i+1])&&!yuan(s[i+2]))){type=1;break;}//Bob
if(!yuan(s[len-2])&&!yuan(s[len-1]))type=1;
for(int i=0;i<len;i++)
{
tot[type][ch(s[i])]++;
if(!v[ch(s[i])])
{
v[ch(s[i])]=true;
app[type][ch(s[i])]++;
zhan[++t]=ch(s[i]);
}
}
while(t>0)v[zhan[t--]]=false;
if(type==0)n++;else m++;
}
double ans=0;
for(int i=1;i<=26;i++)
{
//C++中<cmath>库里面 log 函数就是求 ln
if(app[0][i]!=0)ans+=log(app[0][i])-log(tot[0][i])*n;
if(app[1][i]!=0)ans+=log(tot[1][i])*m-log(app[1][i]);
}
if(ans>log(10000000.0))printf("Infinity\n");
else printf("%.7lf\n",exp(ans));
}
}
T6
这里有必要引用一句话:
绝对保证原创,绝对不保证正确
这题一开始想了一个小时想不出来,半点思路都没有,只有一个 的假 ……
这种时候,我们一般选择找规律。
当我们将一到十跑一遍暴力时,我们发现,这个暴力跑得飞快,然后我们可以得到这样的结果:

怪不得暴力跑得飞快,原来前面有很多
呀。
等下!这莫不就是规律!
(思考……)
(无果……)
然后我跑了一下 时的数据,发现依然跑得飞快,因为只有后面几位需要枚举(大约是 位),前面九千多位都是 ,顺便跑完 的数据,然后计算一下,可以找到一个规律:答案的每一位的平方和组成的平方数,恰好是第一个大于等于 的平方数。
思考一下,发现这几乎是必然的,因为当 到 这个级别后,假如选择让这个平方和组成的平方数变大,哪怕只是向后一个平方数,也至少需要让这些平方和变大 这么多,需要将两个位变成 才能追上,假如均摊到其他不是 的位上,也会让他们变大不少,肯定不是最优解,因为我们需要找到最小的数。
但是,有的时候可能不存在一种方案能使得平方和变成第一个比n大的平方数,这时候我们退而求其次,找第二个比n大的平方数即可,当
在
时,极端情况下,到下两个平方数大约差值为
,需要最后约
位进行改变才能满足这个差值,然而
位的变动覆盖范围是很大的,所以一般都可以找到一种方案满足要求。
那么这个方案的找法用 就好了,设 为用 个平方数相加,第 个平方数最小是多少。因为我们需要让这个数最小,所以需要这样 ,然后为了保险,我们 枚举到 , 枚举到 ,时间是完全可以接受的。
然后对于一个 ,我们枚举变动这 为中的后几位,看一下是否存在方案,满足只变动这么多位可以到达下一个平方数,假如有,那么用 数组倒推回去即可。
假如找不到方案,那么就去再下一个平方数那里找。
太神奇了这题。(虽然不知道我这种乱搞是不是正解,但是跑的飞快是真的)
代码:
//由于代码也调了好一会,所以里面可能有没用的变量,读者人工过滤一下吧qwq
#include <cstdio>
#include <cstring>
#include <cmath>
#include <algorithm>
using namespace std;
int t,n;
int a[1000010],now=0;
bool pingfang(int x){return (int)sqrt(x)*(int)sqrt(x)==x;}
//判断一个数是不是平方数
bool dfs(int x)//暴力
{
if(x==0)
{
if(pingfang(now))
{
for(int i=n;i>=1;i--)
printf("%d",a[i]);
printf("\n");
return true;
}
return false;
}
for(int i=1;i<=9;i++)
{
now+=i*i,a[x]=i;
if(dfs(x-1))return true;
now-=i*i;
}
return false;
}
int f[5010][110];
int s[10]={0,1,4,9,16,25,36,49,64,81};
void work()//dp
{
f[0][0]=1;
for(int j=1;j<=100;j++)
for(int k=1;k<=9;k++)
for(int i=s[k];i<=5000;i++)
if(f[i-s[k]][j-1]!=0)
{
if(f[i][j]==0||k<f[i][j])f[i][j]=k;
}
}
void write(int x){while(x--)putchar('1');}
int main()
{
work();
int tot=0;
scanf("%d",&t);
while(t--)
{
tot++;
scanf("%d",&n);
if(n<=10000)now=0,dfs(n);//假如小于10000,那么跑暴力
else
{
if(pingfang(n))write(n),printf("\n");//假如n就是个平方数,那么输出n个1即可
else
{
bool v=false;
int next=sqrt(n);
next++;next*=next;
for(int i=1;i<=100;i++)
if(f[next-(n-i)][i]!=0)//假如存在方案
{
write(n-i);
int tt=0;now=next-(n-i);
for(int j=i;j>=1;j--)//倒推回去
printf("%d",f[now][j]),now-=s[f[now][j]];
printf("\n");
v=true;
break;
}
if(!v)//假如找不到,去再下一个平方数那里找
{
next=(int)sqrt(next);
next++;next*=next;
for(int i=1;i<=100;i++)
if(f[next-(n-i)][i]!=0)
{
write(n-i);
int tt=0;now=next-(n-i);
for(int j=i;j>=1;j--)
printf("%d",f[now][j]),now-=s[f[now][j]];
printf("\n");
break;
}
}
}
}
}
}
T7
这题想了我好久哇……(我果然还是太菜了qwq)
这题我找了好久找不出什么性质,而且网上也没有什么高效找环的算法,于是卡了我很久……(我都从 rank 14 变成 32 了才想出来……)
背景
最近一系列神奇的事情,让我不禁对玄学做法充满信仰。
大家也知道,现在就快要考CSP了,于是,我们也开始了大量的膜你赛。
在这若干场提高信心膜你赛中,我们的信心被巨佬踩的体无完肤。
为了摆脱爆零的命运,我开始在膜你赛中 yy 玄学做法骗分。
一次第二题,神奇的字符串题,正解kmp,我用神奇的暴力跑了过去,实测飞快。
一次第三题,神奇的计数题,正解 约数个数 ,被我用 约数个数的平方 的神奇做法卡了过去,实测不慢。
一次第一题,神奇的图论题,正解迪杰斯特拉,我用神奇的 SPFA+优化 卡了过去。
然后,就是这题了。我用时间复杂度不明的神奇算法跑了过去。更神奇的是,这题时限两秒,我最慢的点只跑了 。
well,回到正题。(虽然乱搞也不算什么正题就是了……)
要找的关键点很显然满足一个性质:这个点存在于图中所有的环里。如果满足这个条件的话,删掉这个点肯定能破坏掉图中所有的环。
换句话说,我们只需要找出图中所有的环的交集就好了。
那么看到这里,有些人打开了浏览器,尝试搜索寻找图中所有环的高效做法。
但是,这是不存在的,因为你可能连遍历所有的环都做不到,环的数量是可以很多的。
卡了半天之后,我只能选择乱搞了。
我们考虑维护一个答案集合,一开始所有点都在这里面。
每次取出编号最小的点,然后尝试寻找一个不包含该点的环,假如找得到,那么我们将答案集合与这个环取一个交集。
如果找不到,那么这个点就是答案。
如果到最后,答案集合变成了空,就直接输出 。
找环的过程用广搜 找就好了,用广搜找出来的环会尽可能小,这样的话答案集合缩小得很快,所以我觉得这是能够AC的原因。
代码:
#include <cstdio>
#include <cstring>
#include <set>
#include <algorithm>
using namespace std;
#define maxn 100010
#define it set<int>::iterator
int t,n,m;
struct edge{int y,next;};
edge e[maxn*2];
int first[maxn],len;
void buildroad(int x,int y)
{
e[++len]=(edge){y,first[x]};
first[x]=len;
}
set<int> ans,cycle;
int deep[maxn],fa[maxn];
int q[maxn],st,ed;
bool bfs(int tou,int cannot)
{
deep[tou]=1;
st=1,ed=2;
q[st]=tou;
while(st!=ed)
{
int x=q[st++];if(st>maxn-10)st=1;
for(int i=first[x];i;i=e[i].next)
{
int y=e[i].y;
if(y==cannot||y==fa[x])continue;
if(deep[y]!=0)
{
if(deep[y]>deep[x])cycle.insert(y),y=fa[y];
if(deep[x]>deep[y])cycle.insert(x),x=fa[x];
while(x!=y)
{
cycle.insert(x);cycle.insert(y);
x=fa[x];y=fa[y];
}
cycle.insert(x);
return true;
}
else
{
deep[y]=deep[x]+1;fa[y]=x;
q[ed++]=y;if(ed>maxn-10)ed=1;
}
}
}
return false;
}
bool find_cycle(int cannot=0)
{
memset(fa,0,sizeof(fa));
memset(deep,0,sizeof(deep));
cycle.clear();
for(int i=1;i<=n;i++)
if(i!=cannot&&deep[i]==0&&bfs(i,cannot))return true;
return false;
}
int main()
{
scanf("%d",&t);
while(t--)
{
scanf("%d %d",&n,&m);
memset(first,0,sizeof(first));len=0;
for(int i=1,x,y;i<=m;i++)
scanf("%d %d",&x,&y),buildroad(x,y),buildroad(y,x);
ans.clear();
for(int i=1;i<=n;i++)
ans.insert(i);
if(!find_cycle()){printf("-1\n");continue;}//如果图中没有环,显然无解
while(!ans.empty())
{
int x=*ans.begin();
if(find_cycle(x))
{
for(it i=ans.begin();i!=ans.end();)//取交集
if(!cycle.count(*i))
{
it p=i++;
ans.erase(p);
}
else i++;
}
else
{
printf("%d\n",x);
break;
}
}
if(ans.empty())printf("-1\n");
}
}
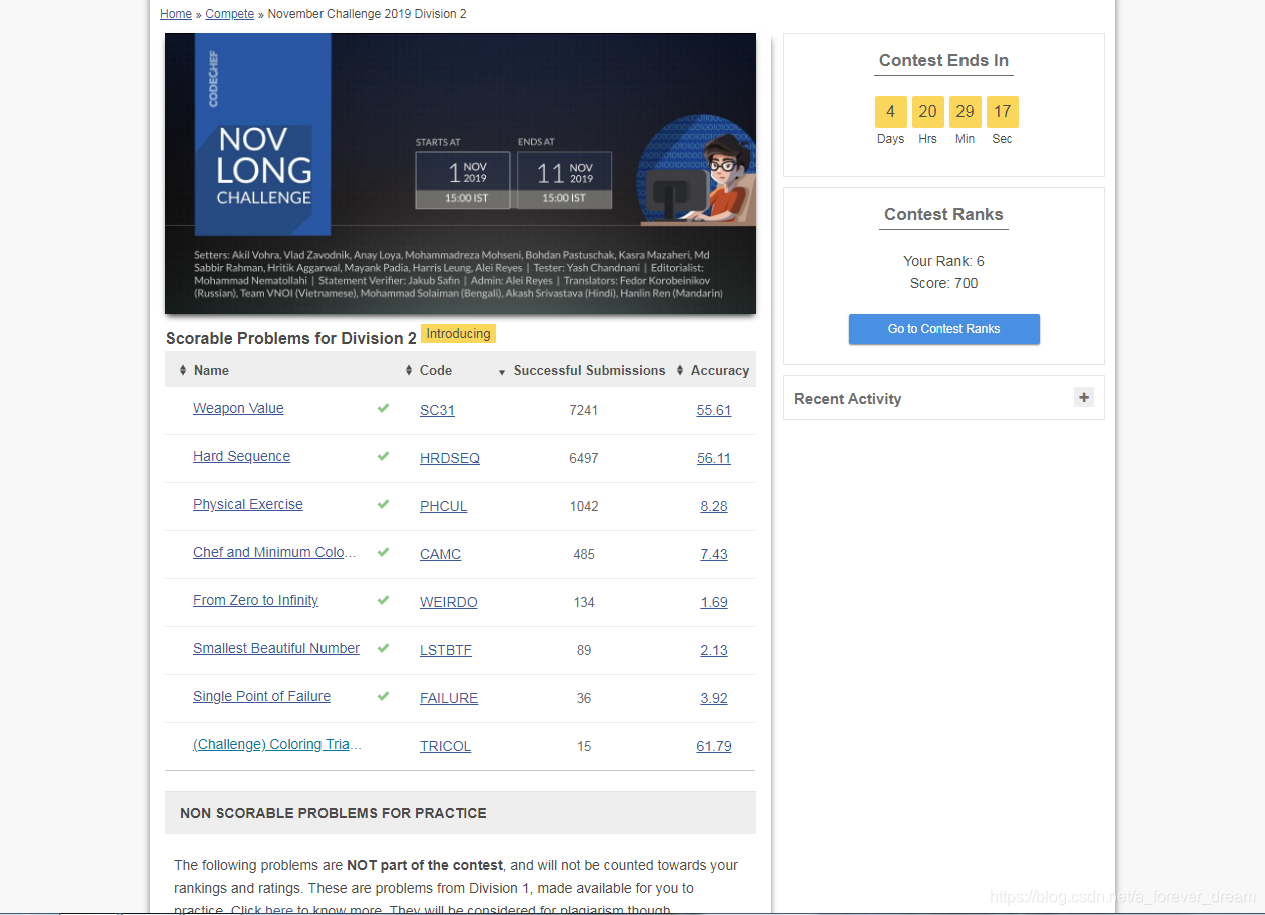
rank 6 纪念一下
T8 太神仙了……完全想不到搞法,只能咕掉了。
小结
这就是打比赛和平常刷题的区别吧……被比赛逼疯了又没有题解的时候什么做法都想得出来。
多打打比赛还是很有助于锻炼思维能力的,因为没有题解,所以只能拼命肝qwq
(下次争取AK) 当然是不可能的qwq
