一.浅拷贝和深拷贝
- 浅拷贝: 不管多么复杂的数据结构,浅拷贝都只会copy一层
- 深拷贝 : 深拷贝会完全复制原变量相关的所有数据,在内存中生成一套完全一样的内容,我们对这两个变量中任意一个修改都不会影响其他变量
import copy
sourceList = [1,2,3,[4,5,6]]
copyList = copy.copy(sourceList)
deepcopyList = copy.deepcopy(sourceList)
sourceList[3][0]=100
print(sourceList) # [1, 2, 3, [100, 5, 6]]
print(copyList) # [1, 2, 3, [100, 5, 6]]
print(deepcopyList) # [1, 2, 3, [4, 5, 6]]
二. python垃圾回收机制
2.1. 引用计数
1)当一个对象的引用被创建或者复制时,对象的引用计数加1;当一个对象的引用被销毁时,对象的引用计数减1.
2)当对象的引用计数减少为0时,就意味着对象已经再没有被使用了,可以将其内存释放掉。
2. 2标记-清除
1)它分为两个阶段:第一阶段是标记阶段,GC会把所有的活动对象打上标记,第二阶段是把那些没有标记的对象非活动对象进行回收。
2)对象之间通过引用(指针)连在一起,构成一个有向图
3)从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象,根对象就是全局变量、调用栈、寄存器。
注:像是PyIntObject、PyStringObject这些不可变对象是不可能产生循环引用的,因为它们内部不可能持有其它对象的引用。
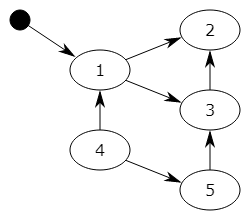
1.在上图中,可以从程序变量直接访问块1,并且可以间接访问块2和3,程序无法访问块4和5
2. 第一步将标记块1,并记住块2和3以供稍后处理。
3. 第二步将标记块2,第三步将标记块3,但不记得块2,因为它已被标记。
4. 扫描阶段将忽略块1,2和3,因为它们已被标记,但会回收块4和5。
2.3 分代回收
- 分代回收是建立在标记清除技术基础之上的,是一种以空间换时间的操作方式。
- Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代)
- 他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。
- 新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发
- 把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推
- 老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。
三.高阶函数
3.1. lambda基本使用
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda表达式是起到一个函数速写的作用。允许在代码内嵌入一个函数的定义。
- 格式:lambda的一般形式是关键字lambda后面跟一个或多个参数,紧跟一个冒号,之后是一个表达式。
f = lambda x,y,z:x+y+z
print(f(1,2,3)) # 6
my_lambda = lambda arg : arg + 1
print(my_lambda(10)) # 11
3.2. 三元运算
- 三元运算格式: result=值1 if x<y else 值2 if条件成立result=1,否则result=2
- 作用:三元运算,又称三目运算,主要作用是减少代码量,是对简单的条件语句的缩写
name = 'Tom' if 1 == 1 else 'fly'
print(name)
# 运行结果: Tom
f = lambda x:x if x % 2 != 0 else x + 100
print(f(10)) # 110
1).map函数:map()函数接收两个参数,一个是函数,一个是序列,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回。
l1= [11,22,33,44,55]
ret = map(lambda x:x if x % 2 != 0 else x + 100,l1)
print(list(ret))
# 运行结果: [11, 122, 33, 144, 55]
2).reduce函数:reduce把一个函数作用在一个序列[x1,x2,x3…]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做计算。
from functools import reduce
def f(x, y):
return x + y
print(reduce(f, [1, 3, 5, 7, 9])) # 25
# 1、先计算头两个元素:f(1, 3),结果为4;
# 2、再把结果和第3个元素计算:f(4, 5),结果为9;
# 3、再把结果和第4个元素计算:f(9, 7),结果为16;
# 4、再把结果和第5个元素计算:f(16, 9),结果为25;
# 5、由于没有更多的元素了,计算结束,返回结果25。
print( reduce(lambda x, y: x + y, [1, 3, 5, 7, 9]) ) # 25
3).filter函数:filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
l1= [11,22,33,44,55]
a = filter(lambda x: x<33, l1)
print(list(a))
4).sorted() 函数对所有可迭代的对象进行排序操作。sort(key,reverse)
这个是列表的方法
d = {'k1':1, 'k3': 3, 'k2':2}
# d.items() = [('k1', 1), ('k3', 3), ('k2', 2)]
a = sorted(d.items(), key=lambda x: x[1])
print(a) # [('k1', 1), ('k2', 2), ('k3', 3)]
