浅拷贝和深拷贝
浅拷贝: 不管多么复杂的数据结构,浅拷贝都只会copy一层 ,对一方文件做出修改,会影响原文件
深拷贝 : 深拷贝会完全复制原变量相关的所有数据,在内存中生成一套完全一样的内容,我们对这两个变量中任意一个修改都不会影响其他变量
import copy
sourceList = [1,2,3,[4,5,6]]
copyList = copy.copy(sourceList)
deepcopyList = copy.deepcopy(sourceList)
sourceList[3][0]=100
print(sourceList) # [1, 2, 3, [100, 5, 6]]
print(copyList) # [1, 2, 3, [100, 5, 6]]
print(deepcopyList) # [1, 2, 3, [4, 5, 6]]
python垃圾回收机制
引用计数
-
原理
1)当一个对象的引用被创建或者复制时,对象的引用计数加1;当一个对象的引用被销毁时,对象的引用计数减1.
2)当对象的引用计数减少为0时,就意味着对象已经再没有被使用了,可以将其内存释放掉。 -
优点
引用计数有一个很大的优点,即实时性,任何内存,一旦没有指向它的引用,就会被立即回收,而其他的垃圾收集技术必须在某种特殊条件下才能进行无效内存的回收。 -
缺点
1)引用计数机制所带来的维护引用计数的额外操作与Python运行中所进行的内存分配和释放,引用赋值的次数是成正比的,
2)这显然比其它那些垃圾收集技术所带来的额外操作只是与待回收的内存数量有关的效率要低。
3)同时,因为对象之间相互引用,每个对象的引用都不会为0,所以这些对象所占用的内存始终都不会被释放掉。
标记-清除
1.说明
1)它分为两个阶段:第一阶段是标记阶段,GC会把所有的活动对象打上标记,第二阶段是把那些没有标记的对象非活动对象进行回收。
2)对象之间通过引用(指针)连在一起,构成一个有向图
3)从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象
根对象就是全局变量、调用栈、寄存器。
注:像是PyIntObject、PyStringObject这些不可变对象是不可能产生循环引用的,因为它们内部不可能持有其它对象的引用。
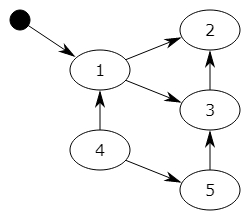
- 在上图中,可以从程序变量直接访问块1,并且可以间接访问块2和3,程序无法访问块4和5
- 第一步将标记块1,并记住块2和3以供稍后处理。
- 第二步将标记块2,第三步将标记块3,但不记得块2,因为它已被标记。
- 扫描阶段将忽略块1,2和3,因为它们已被标记,但会回收块4和5。
2.缺点:
1)标记清除算法作为Python的辅助垃圾收集技术,主要处理的是一些容器对象,比如list、dict、tuple等 因为对于字符串、数值对象是不可能造成循环引用问题。
2)清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
分代回收
- 分代回收是建立在标记清除技术基础之上的,是一种以空间换时间的操作方式。
- Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代)
- 他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。
- 新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发
- 把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推
- 老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。
高阶函数
filter()函数可以对序列做过滤处理
l1= [11,22,33,44,55]
a = filter(lambda x: x<33, l1)
print(list(a))
Map是对序列根据设定条件进行操作后返回他设置的是操作方法
l1= [11,22,33,44,55]
ret = map(lambda x:x if x % 2 != 0 else x + 100,l1)
print(list(ret))
# 运行结果: [11, 122, 33, 144, 55]
reduce函数使用reduce进行求和运算
- reduce()函数即为化简函数,它的执行过程为:每一次迭代,都将上一次的迭代结果与下一个元素一同传入二元func函数中去执行。
- 在reduce()函数中,init是可选的,如果指定,则作为第一次迭代的第一个元素使用,如果没有指定,就取seq中的第一个元素。
from functools import reduce
def f(x, y):
return x + y
print(reduce(f, [1, 3, 5, 7, 9])) # 25
# 1、先计算头两个元素:f(1, 3),结果为4;
# 2、再把结果和第3个元素计算:f(4, 5),结果为9;
# 3、再把结果和第4个元素计算:f(9, 7),结果为16;
# 4、再把结果和第5个元素计算:f(16, 9),结果为25;
# 5、由于没有更多的元素了,计算结束,返回结果25。
print( reduce(lambda x, y: x + y, [1, 3, 5, 7, 9]) ) # 25
3、再把结果和第4个元素计算:f(9, 7),结果为16;
sorted函数,sorted对字典排序
d = {'k1':1, 'k3': 3, 'k2':2}
# d.items() = [('k1', 1), ('k3', 3), ('k2', 2)]
a = sorted(d.items(), key=lambda x: x[1])
print(a) # [('k1', 1), ('k2', 2), ('k3', 3)]
lambda基本使用
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda表达式是起到一个函数速写的作用。允许在代码内嵌入一个函数的定义。
- 格式:lambda的一般形式是关键字lambda后面跟一个或多个参数,紧跟一个冒号,之后是一个表达式。
f = lambda x,y,z:x+y+z
print(f(1,2,3)) # 6
my_lambda = lambda arg : arg + 1
print(my_lambda(10)) # 11
