TensorFlow2 学习——图像分类
导包
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
原始数据
- 加载数据集
# 衣物类图片数据集 fashion_mnist # 训练集All,测试集 (X_train_all, y_train_all),(X_test, y_test) = tf.keras.datasets.fashion_mnist.load_data() # 手写数字数据集mnist # tf.keras.datasets.mnist.load_data() - 查看数据集
# 查看数据维度 print(X_train_all.shape) # 查看标签种类 print(set(y_train_all))
数据作图
- 单个图片数据分析
# 其中一张图片的数据 print(X_train_all[0])- 此处会打印一个28*28的矩阵
- 矩阵内的值表示0-255的灰度值(即代表图片的一个像素)
- 展示单张图片
def show_single_image(img_arr): plt.imshow(img_arr, cmap="binary") plt.show() show_single_image(X_train_all[1])
- 展示多张图片
def show_images(n_rows, n_cols, x_data, y_data, class_names): assert len(x_data) == len(y_data) assert n_rows * n_cols < len(x_data) plt.figure(figsize=(n_cols * 1.5, n_rows * 1.5)) for row in range(n_rows): for col in range(n_cols): index = row * n_cols + col plt.subplot(n_rows, n_cols, index + 1) plt.imshow(x_data[index], cmap="binary", interpolation="nearest") plt.axis("off") plt.title(class_names[y_data[index]]) plt.show() class_names = ["T-shirt", "Trouser", "Pullover", "Dress", "Coat", "Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"] show_images(3, 5, X_train_all, y_train_all, class_names)
数据划分与标准化
- 训练集、验证集拆分
# X_train, X_valid = X_train_all[:50000], X_train_all[50000:] # y_train, y_valid = y_train_all[:50000], y_train_all[50000:] X_train, X_valid, y_train, y_valid = train_test_split(X_train_all, y_train_all, test_size=0.25) print("train: ", X_train.shape, y_train.shape) print("valid: ", X_valid.shape, y_valid.shape) print(" test: ", X_test.shape, y_test.shape) - 数据标准化
scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train.reshape(-1, 28 * 28)).reshape(-1, 28, 28) X_valid_scaled = scaler.transform(X_valid.reshape(-1, 28 * 28)).reshape(-1, 28, 28) X_test_scaled = scaler.transform(X_test.reshape(-1, 28 * 28)).reshape(-1, 28, 28) print(X_train_scaled.max(), X_train_scaled.min())
构建模型并训练
-
搭建神经网络层
# relu: y = max(0, x) # softmax: 用于解决多分类问题,将向量变成概率分布 # x = [x1, x2, x3] # sum = e^x1 + e^x2 + e^x3 # y = [e^x1/sum, e^x2/sum, e^x3/sum] # 方法1 # model = tf.keras.models.Sequential() # model.add(tf.keras.layers.Flatten(input_shape=[28, 28])) # model.add(tf.keras.layers.Dense(300, activation="relu")) # model.add(tf.keras.layers.Dense(100, activation="relu")) # model.add(tf.keras.layers.Dense(10, activation="softmax")) # 方法2 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=[28, 28]), tf.keras.layers.Dense(200, activation="relu"), tf.keras.layers.Dense(150, activation="relu"), # tf.keras.layers.Dropout(0.5), # 添加Dropout层,可以抑制过拟合。0.5表示丢弃50%单元 tf.keras.layers.Dense(100, activation="relu"), tf.keras.layers.Dense(10, activation="softmax") ]) # 方法3 函数式 # input = tf.keras.Input(shape=(28, 28)) # x = tf.keras.layers.Flatten()(input) # x = tf.keras.layers.Dense(200, activation="relu")(x) # x = tf.keras.layers.Dense(150, activation="relu")(x) # x = tf.keras.layers.Dense(100, activation="relu")(x) # output = tf.keras.layers.Dense(10, activation="softmax")(x) # model = tf.keras.Model(inputs=input, outputs=output)- Flatten用于降维,例如此处将28*28的矩阵打散为784个特征的一维向量
- Dense是全连接层,接收上一层的所有参数
- 第一个参数,指的是本层有多少个神经元节点
- 第二个参数,activation是激活函数,用于处理接收到的数据,包括relu、sigmoid、softmax等
- 最后一个Dense,节点数被设置为10,因为本数据标签只有10类,因此最后只有10种输出
-
模型编译
model.compile(loss = "sparse_categorical_crossentropy", optimizer = "adam", metrics = ["accuracy"])- loss 代表损失函数的计算方式
- 例如还可以写成mse、categorical_crossentropy等
- 此处因为是多分类问题,所以可以采用sparse_categorical_crossentropy或categorical_crossentropy
- 如要使用categorical_crossentropy,需要将标签数据转换为onehot编码形式,代码如下
y_train_onehot = tf.keras.utils.to_categorical(y_train) y_valid_onehot = tf.keras.utils.to_categorical(y_valid) y_test_onehot = tf.keras.utils.to_categorical(y_test)
- optimizer 代表优化的方式
- 例如sgd、rmsprop、adam等
- 需要调节其内部参数,可以写成
tf.keras.optimizers.Adam(lr=0.001)
- metrics 代表了模型评判标准,会随着训练时打印
- loss 代表损失函数的计算方式
-
模型总览
model.summary()Model: "sequential_13" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten_13 (Flatten) (None, 784) 0 _________________________________________________________________ dense_46 (Dense) (None, 200) 157000 _________________________________________________________________ dense_47 (Dense) (None, 150) 30150 _________________________________________________________________ dense_48 (Dense) (None, 100) 15100 _________________________________________________________________ dense_49 (Dense) (None, 10) 1010 ================================================================= Total params: 203,260 Trainable params: 203,260 Non-trainable params: 0- Layer列 - 是我们构建的网络层
- Output Shape列 - 是当前网络层的信息
- 第一个参数None是样本数,因为构建模型时并不知道等会儿需要训练多少数据,因此是None
- 第二个参数是该层神经元节点的个数
- Param # - 是该网络层待训练参数的个数
- 计算公式:上一层节点个数 * 本层节点个数 + 本层节点个数 = 本层参数个数
- 例如 784 * 200 + 200 = 157000,200 * 150 + 150 = 30150
- 其实就是说,本层每个节点针对上一层的所有节点分别都有一个权重w,最后本层每个节点还有一个偏置值b
-
开始训练模型
# X_train_scaled 即训练集特征 # y_train 即训练集标签 # epochs 是训练的批次数 # validation_data 用于指定验证集 history = model.fit(X_train_scaled, y_train, epochs=10, validation_data=(X_valid_scaled, y_valid))- 训练过程较慢,需等待
- 其中 loss: 0.2208 - accuracy: 0.9171 代表了训练集的损失值、准确的
- 其中 val_loss: 0.3333 - val_accuracy: 0.8916 代表了验证集的损失值、准确的
模型评估与预测
- 查看模型训练历史记录
pd.DataFrame(history.history) - 利用历史记录作图
pd.DataFrame(history.history).plot(figsize=(8, 5)) plt.grid(True) #plt.gca().set_ylim(0, 1) plt.show()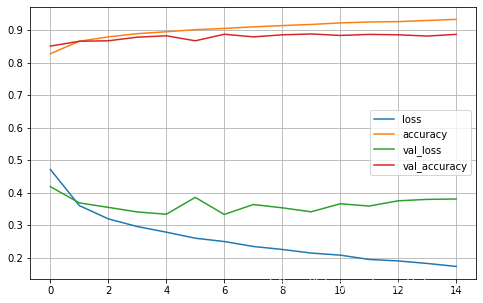
- 使用测试集进行模型评估
model.evaluate(X_test_scaled, y_test)- 输出结果示例
[0.35619084103703497, 0.8747] - 第一个是损失值,第二个是准确率
- 输出结果示例
- 利用模型进行预测
- 使用predict进行预测
# 使用predict进行预测 result = model.predict(X_test_scaled[0:1]) print(result) # 10个类别,每个类别都有一个概率 print(result.sum()) # 所有类别概率和为1 print(result.max(), np.argmax(result)) # 概率最大的就是预测的类别[[4.1775929e-09 4.8089838e-10 9.2707603e-10 7.3885815e-08 5.2114243e-11 2.4399082e-03 1.8424946e-09 9.9424636e-03 2.9137237e-12 9.8761755e-01]] 1.0 0.98761755 9 - 使用predict_classes直接得到预测的类别
# 使用predict_classes直接得到预测的类别 print(model.predict_classes(X_test_scaled)[:30]) print(y_test[:30])[9 2 1 1 6 1 4 6 5 7 4 5 8 3 4 1 2 2 8 0 2 5 7 5 1 2 6 0 9 6] [9 2 1 1 6 1 4 6 5 7 4 5 7 3 4 1 2 4 8 0 2 5 7 9 1 4 6 0 9 3]
- 使用predict进行预测
其他:回调Callback的使用
- Callback
- Tensorboard - 生成Tensorboard记录,方便查看
- EarlyStopping - 用于提前停止训练。本次loss与上次loss之差小于min_delta达到patience次,那就停止训练
- ModelChackpoint - 保存模型,save_best_only保存最佳的
- 代码示例
import os # windows下写.\callbacks,linux下写./callbacks,或者都写callbacks(不指定前面的斜杠/反斜杠) logdir = ".\callbacks" if not os.path.exists(logdir): os.mkdir(logdir) ouput_model_file = os.path.join(logdir, "fashion_mnist_model.h5") callbacks = [ tf.keras.callbacks.TensorBoard(logdir), tf.keras.callbacks.ModelCheckpoint(ouput_model_file, save_best_only=True), tf.keras.callbacks.EarlyStopping(min_delta=1e-3, patience=5) ] history = model.fit(X_train_scaled, y_train, epochs=20, validation_data=(X_valid_scaled, y_valid), callbacks = callbacks) - 查看Tensorboard的命令
tensorboard --logdir callbacks的目录
