整体思路:
1)使用tensorflow2加载预训练bert模型,进行训练,然后将模型部署载tfseving中。
2)使用flask部署模型推理,模型推理时会requrest请求 1) 中tfserving部署的模型
3) 将2)的flask构建成一个docker镜像,运行镜像即启动了服务
4)模型更新:只需将最新模型放入tfserving的对应模型路径下
1 模型训练及tfserving部署
参考博客
https://blog.csdn.net/weixin_42529756/article/details/122420339?spm=1001.2014.3001.5501
2 模型推理及flask部署
模型整理文件如下:
- requirements.txt #由于使用原生的Python构建dockeer镜像,需要安装很多依赖包。
- flask_infer.py # 模型推理文件,如下所示
- bert-case-chinese # Google须训练bert模型,(只需要里面的配置文件即可,不需要模型,主要用来分词tokenizer)
注意: app.run(port=5000,host=“0.0.0.0”)
中的host不要使用默认的,不然远程会访问不了的。
flask_infer.py文件如下
from flask import Flask,request,jsonify
app=Flask(__name__)
from transformers import BertTokenizer
import pandas as pd
import json
import requests
import numpy as np
model_path = "./bert-case-chinese/"
max_length=50
df_label = pd.DataFrame({"label":["财经","房产","股票","教育","科技","社会","时政","体育","游戏","娱乐"],"y":list(range(10))})
new_label=df_label.to_dict()['label']
tokenizer = BertTokenizer.from_pretrained(model_path )
headers = {"content-type": "application/json"}
def predict(text):
input_dict = tokenizer(text, return_tensors='tf',max_length=max_length,padding ='max_length')
input_ids = input_dict["input_ids"].numpy().tolist()[0]
attention_mask = input_dict["attention_mask"].numpy().tolist()[0]
token_type_ids = input_dict["token_type_ids"].numpy().tolist()[0]
features = [{'input_ids': input_ids, 'attention_mask': attention_mask,'token_type_ids':token_type_ids}]
data = json.dumps({ "signature_name": "serving_default", "instances": features})
json_response = requests.post('http://192.168.10.100:8501/v1/models/model:predict', data=data, headers=headers)
predictions = json.loads(json_response.text)['predictions']
return predictions
app.config['JSON_AS_ASCII'] = False
@app.route('/hello')
def hello():
return "hello world "
@app.route('/predict',methods=['POST'])
def pred():
try:
data=request.get_json()['data']
print("data," ,data)
predictions=predict(data)
print("predictions : ",predictions)
label_to_index=np.argmax(predictions)
index_to_label=new_label[label_to_index]
response={"label":index_to_label,
"response_state":"success"}
except:
response={"reponse_state":"error"}
return jsonify(response)
if __name__=='__main__':
app.run(port=5000,host="0.0.0.0")
requirements.txt,内容如下
transformers==4.12.5
flask==2.0.1
numpy==1.19.5
pandas==1.1.2
tensorflow==2.4.1
3 docker镜像创建及运行
1)使用上面的文件构建Dockerfile镜像

2)Dockerfile 文件内容
FROM python:3.6
WORKDIR /opt
RUN mkdir -p /opt/serving/bertclf
COPY . /opt
RUN pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
ENTRYPOINT ["python"]
CMD ["flask_infer.py"]
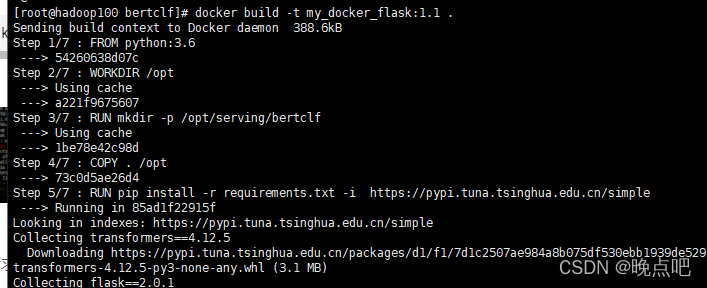
3)镜像构建
docker build -t my_docker_flask:1.1 .
扫描二维码关注公众号,回复:
14798123 查看本文章

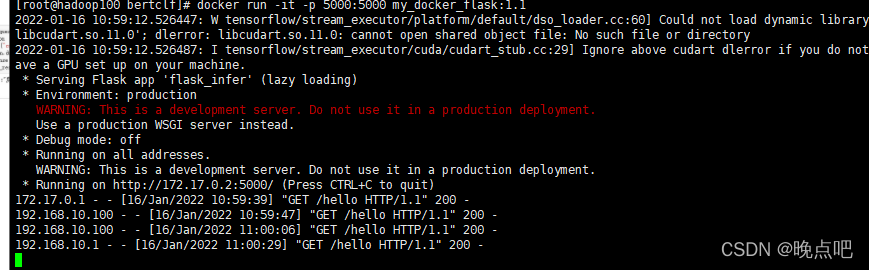
4) 容器运行
docker run -it -p 5000:5000 my_docker_flask:1.1
5)请求