文章目录
一、安装spark
1、已解spark的压缩包
tar -zxvf spark-2.0.2-bin-hadoop2.7.tgz
2、进入~/spark/conf里配置spark-env.sh,改文件包含sark的各种运行环境

3、配置slaves文件,同样复制一份 .template
4、将配置好的spark分发给所有slave(这里也就是node01 node02)
scp -r /export/servers/spark-2.0.2-bin-hadoop2.7 root@node02:/export/servers/spark-2.0.2-bin-hadoop2.7
scp -r /export/servers/spark-2.0.2-bin-hadoop2.7 root@node03:/export/servers/spark-2.0.2-bin-hadoop2.7
5、配置spark环境变量
将spark添加到环境变量 添加以下内容/etc/profile

export SPARK_HOME=:/export/servers/spark-2.0.2-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
记得要 source /etc/profile以下,更新下环境变量
6、启动spark,停止spark
#在node01(主)节点上启动spark,(~/spark/bin)

start-all.sh
#在node01(主)节点上停止spark,(~/spark/bin)
stop-all.sh
7、看下work的状态
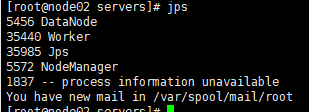
发现work已经起来了,ok啦
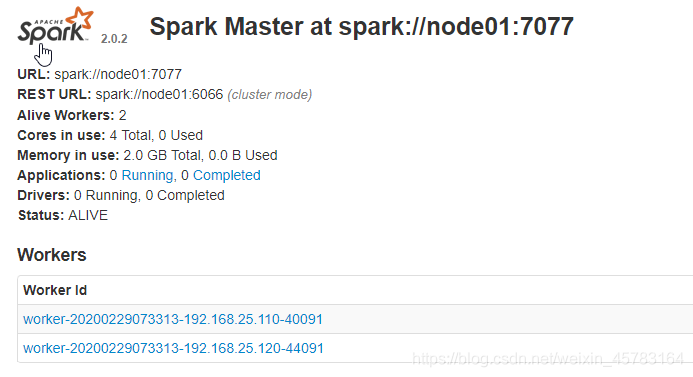
8、通过web访问spark
http://192.168.25.100:8080/
node01:8080
二、简单的测试一下,用shell写个wordcount
spark-shell进入
spark-shell
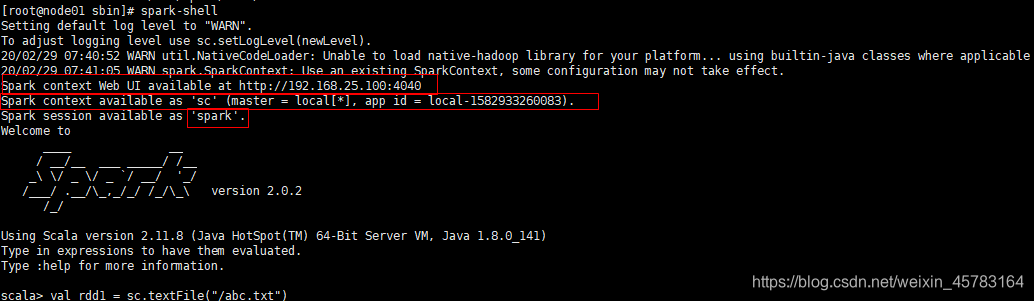

这里要提一下sparkcontext(sc)他自己会给你,你要知道sc是什么,这里直接可以拿来用
- 第一条
scala> val rdd1 = sc.textFile("/abc.txt")
主要功能是加载HDFS中 abc.txt 的数据文件进入Spark本地或是集群计算,这里我们使用的是SparkContext的textFile算子,加载后的数据将以每行记录组成元素,元素类型为String
- 第二条
scala> val rdd2 = rdd1.flatMap(line=>line.split(" "))
主要是对每一行进行操作。这里使用transformation中的flatMap算子,作用是可以将一个数据扁平化处理。这里也就是将输入文件的每一行数据,按空格(" ")进行拆分,得到单词数组,再将数组进行扁平化后形成单词字符串,在flatMapRDD中.
- 第三条
scala> val rdd3 = rdd2.map(word =>(word,1))
单词数组flatMapRDD中的数据进行标记,即每个行的格式由单个单词转变成的形式。
- 第四条
scala> val rdd4 = rdd3.reduceByKey(_+_)
不同RDD中相同key值拉到一起进行value的归并操作,shuffle
- 第五条
scala> rdd4.saveAsTextFile("/out")
将结果保存到 hdfs /out下
来看一下结果吧


晚安!
