部署是环境为3台服务器 ,里面安装了相关的hadoop集群,安装的spark1.6.3
总共分为如下安装方式
1,单机模式测试安装
2,Standalone集群模式
3,Standalone集群HA模式
4,Yarn集群模式
一,单机模式测试安装
1,解压安装包
[root@hadoop01 bigdata]# pwd
/home/tools/bigdata
[root@hadoop01 bigdata]# tar -zxvf spark-1.6.3-bin-hadoop2.4.tgz -C /home/bigdata/2,配置环境变量
vi /etc/profile
export SPARK_HOME=/home/bigdata/spark-1.6.3-bin-hadoop2.4
export PATH=$SPARK_HOME/bin:$PATH
source /etc/profile
3,测试
root@hadoop01 lib]# cd /home/bigdata/spark-1.6.3-bin-hadoop2.4/lib/
[root@hadoop01 lib]# spark-submit --class org.apache.spark.examples.SparkPi --master local[*] spark-examples-1.6.3-hadoop2.4.0.jar 100测试结果
18/07/07 15:36:52 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:36, took 3.541017 s
Pi is roughly 3.1416247141624716
18/07/07 15:36:52 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/metrics/json,null}二,Standalone集群模式
1,配置slaves
[root@hadoop01 conf]# cd /home/bigdata/spark-1.6.3-bin-hadoop2.4/conf/
[root@hadoop01 conf]# cp slaves.template slaves
[root@hadoop01 conf]# vi slaves
hadoop01
hadoop02
hadoop032,配置spark-env.sh
[root@hadoop01 conf]# cp spark-env.sh.template spark-env.sh
[root@hadoop01 conf]# vi spark-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_79
export SPARK_MASTER_IP=hadoop01
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=4
export SPARK_WORKER_INSTANCES=4
export SPARK_WORKER_MEMORY=2g3,分发到每个节点
[root@hadoop01 bigdata]# scp -r spark-1.6.3-bin-hadoop2.4/ hadoop02:/home/bigdata/
[root@hadoop01 bigdata]# scp -r spark-1.6.3-bin-hadoop2.4/ hadoop03:/home/bigdata/4,启动集群
[root@hadoop01 spark-1.6.3-bin-hadoop2.4]# ./sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/bigdata/spark-1.6.3-bin-hadoop2.4/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop01.out
hadoop01: starting org.apache.spark.deploy.worker.Worker, logging to /home/bigdata/spark-1.6.3-bin-hadoop2.4/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop01.out
hadoop02: starting org.apache.spark.deploy.worker.Worker, logging to /home/bigdata/spark-1.6.3-bin-hadoop2.4/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop02.out
hadoop03: starting org.apache.spark.deploy.worker.Worker, logging to /home/bigdata/spark-1.6.3-bin-hadoop2.4/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-hadoop03.out访问网页
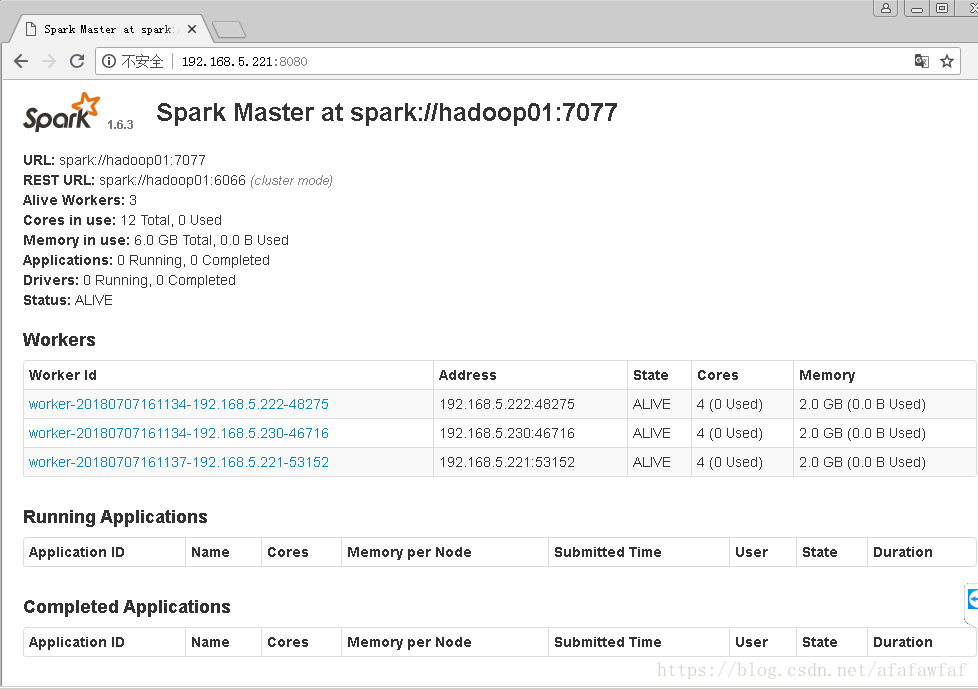
5,Client模式的测试(结果可以在XSHELL可见)
[root@hadoop01 lib]# cd /home/bigdata/spark-1.6.3-bin-hadoop2.4/lib/
[root@hadoop01 lib]# spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop01:7077 --executor-memory 2G --total-executor-cores 4 spark-examples-1.6.3-hadoop2.4.0.jar 100测试结果
18/07/07 16:17:27 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:36, took 23.539045 s
Pi is roughly 3.1406503140650313
18/07/07 16:17:27 INFO SparkUI: Stopped Spark web UI at http://192.168.5.221:4040[root@hadoop01 lib]# cd /home/bigdata/spark-1.6.3-bin-hadoop2.4/lib/
[root@hadoop01 lib]# spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop01:7077 --deploy-mode cluster --supervise --executor-memory 2G --total-executor-cores 4 spark-examples-1.6.3-hadoop2.4.0.jar 100查看结果

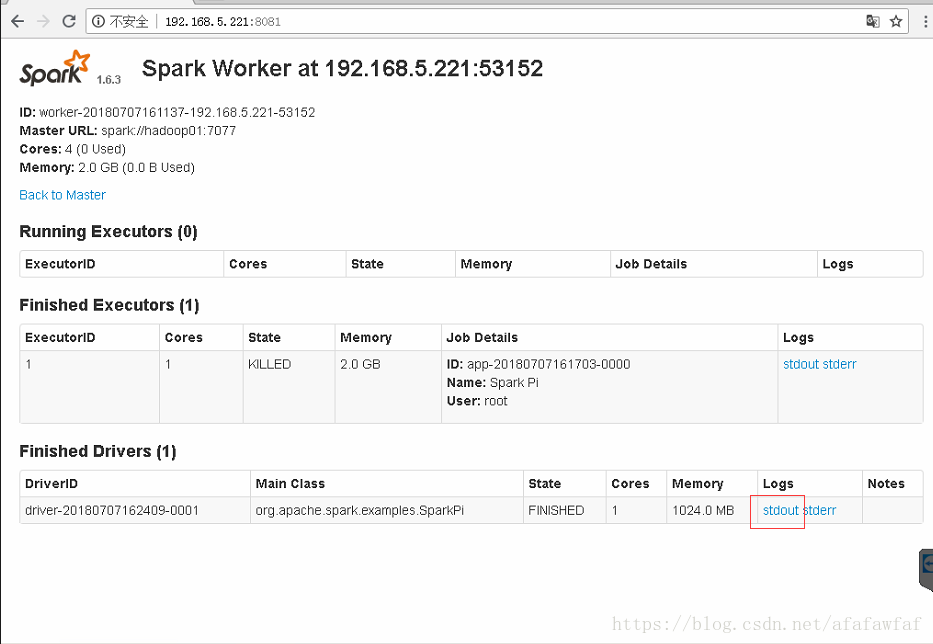
四,Standalone集群HA模式
1,参考网址
http://spark.apache.org/docs/1.6.3/spark-standalone.html#standby-masters-with-zookeeper2,配置spark-env.sh(添加如下内容)
[root@hadoop01 spark-1.6.3-bin-hadoop2.4]# cd /home/bigdata/spark-1.6.3-bin-hadoop2.4/conf/
[root@hadoop01 conf]# vi spark-env.sh
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01:2181,hadoop02:2181,hadoop03:2181"
[root@hadoop01 conf]# scp spark-env.sh hadoop02:/home/bigdata/spark-1.6.3-bin-hadoop2.4/conf/.
spark-env.sh 100% 4542 4.4KB/s 00:00
[root@hadoop01 conf]# scp spark-env.sh hadoop03:/home/bigdata/spark-1.6.3-bin-hadoop2.4/conf/.
spark-env.sh 100% 4542 4.4KB/s 00:00 3,修改第2个Master的spark-env.sh
[root@hadoop02 conf]# vi spark-env.sh
修改为hadoop02
export SPARK_MASTER_IP=hadoop024,启动和检测
[root@hadoop02 spark-1.6.3-bin-hadoop2.4]# ./sbin/start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /home/bigdata/spark-1.6.3-bin-hadoop2.4/logs/spark-root-org.apache.spark.deploy.master.Master-1-hadoop02.out查看网页ALIVE Master
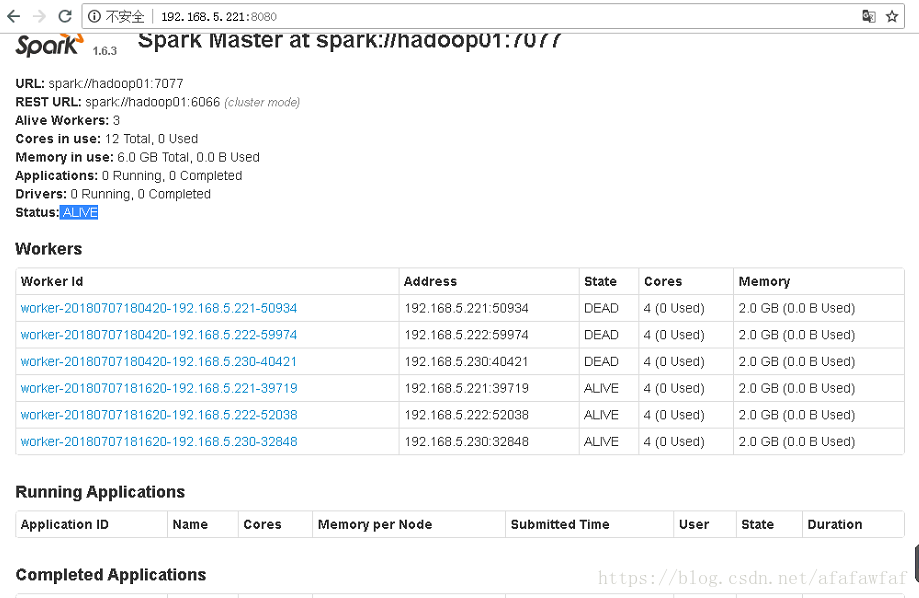
查看网页STANDBY Master
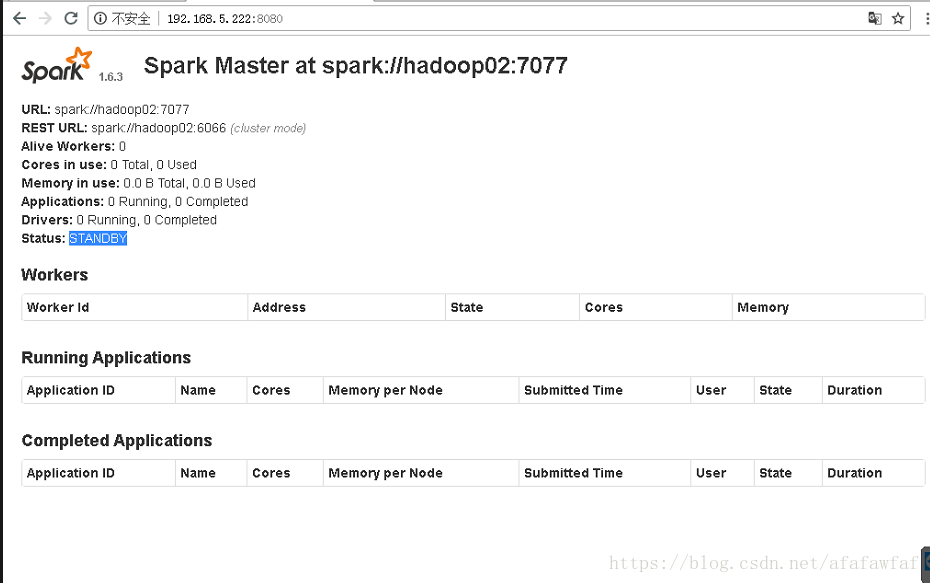
5,Yarn集群模式
注,先启动Hadoop集群
1,配置spark-env.sh(添加如下内容)
[root@hadoop01 conf]# pwd
/home/bigdata/spark-1.6.3-bin-hadoop2.4/conf
[root@hadoop01 conf]# vi spark-env.sh
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/home/bigdata/spark-1.6.3-bin-hadoop2.4
export SPARK_JAR=/home/bigdata/spark-1.6.3-bin-hadoop2.4/lib/spark-assembly-1.6.3-hadoop2.4.0.jar
export PATH=$SPARK_HOME/bin:$PATH[root@hadoop01 conf]# scp spark-env.sh hadoop02:/home/bigdata/spark-1.6.3-bin-hadoop2.4/conf/
spark-env.sh 100% 4824 4.7KB/s 00:00
[root@hadoop01 conf]# scp spark-env.sh hadoop03:/home/bigdata/spark-1.6.3-bin-hadoop2.4/conf/
spark-env.sh 2,Client模式测试
[root@hadoop01 lib]# spark-submit --class org.apache.spark.examples.SparkPi --master yarn-client --executor-memory 2G --num-executors 2 spark-examples-1.6.3-hadoop2.4.0.jar 10018/07/07 18:38:00 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:36, took 10.600323 s
Pi is roughly 3.1414043141404315
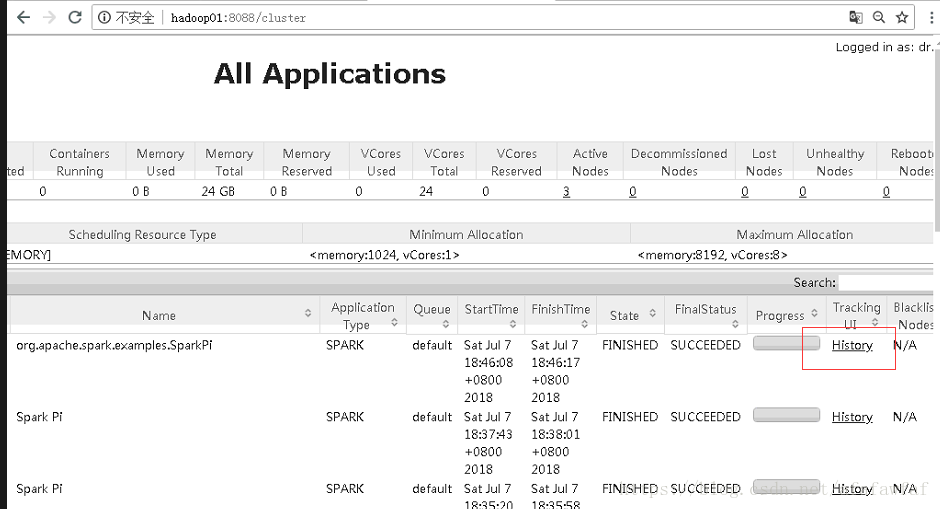
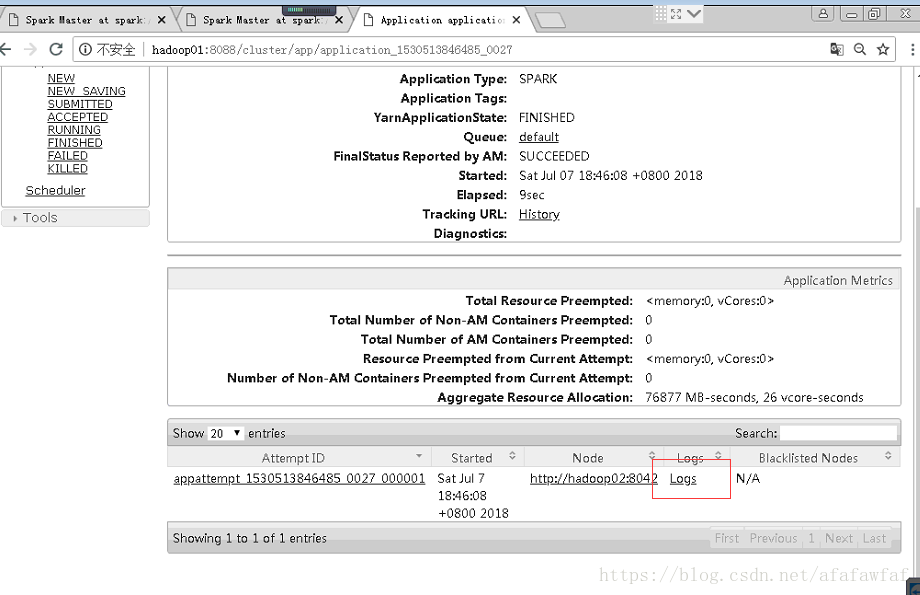
18/07/07 18:38:00 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/metrics/json,null}3,Cluster模式测试
[root@hadoop01 lib]# pwd
/home/bigdata/spark-1.6.3-bin-hadoop2.4/lib
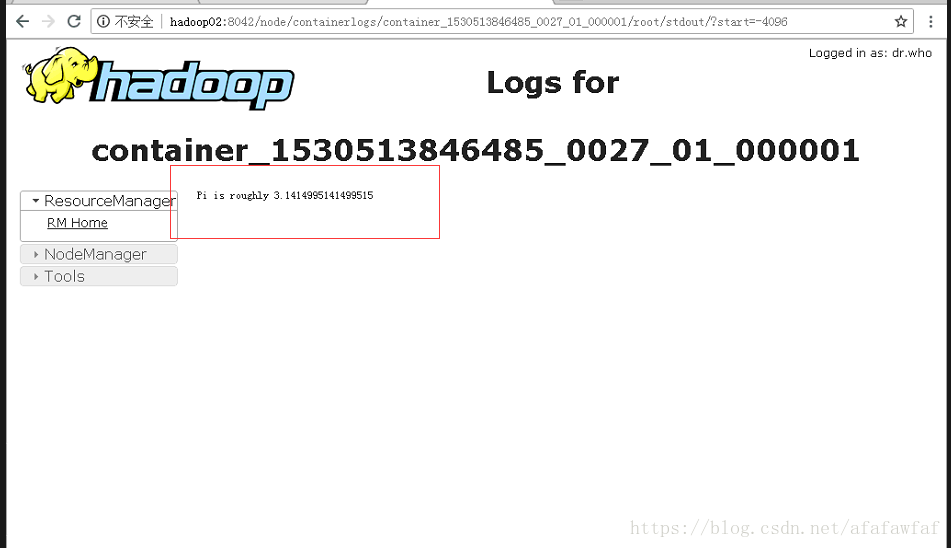
[root@hadoop01 lib]# spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster --executor-memory 2G --num-executors 2 spark-examples-1.6.3-hadoop2.4.0.jar 100查看结果