1,启动spark shell
spark-shell \
--master spark://zhangjianfeng012:7077 \
--executor-memory 2G \ 内存开始设置500m,运行很慢
--total-executor-cores 1 参数说明:
--master spark://zhangjianfeng012:7077 指定Master的地址
--executor-memory 500m:指定每个worker可用内存为500m
--total-executor-cores 1: 指定整个集群使用的cup核数为1个
2、 在spark shell中编写WordCount程序
(1)编写一个hello.txt文件并上传到HDFS上的spark目录下
[mr@zhangjianfeng010 ~]$ vi hello.txt
[mr@zhangjianfeng010 ~]$ hadoop fs -mkdir -p /spark
[mr@zhangjianfeng010 ~]$ hadoop fs -put hello.txt /sparkhello.txt的内容如下
you,jump
i,jump
you,jump
i,jump
jump(2)在spark shell中用scala语言编写spark程序
scala> sc.textFile("/spark/hello.txt").flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/spark/out")说明:
sc是SparkContext对象,该对象是提交spark程序的入口
textFile("/spark/hello.txt")是hdfs中读取数据
flatMap(_.split(" "))先map再压平
map((_,1))将单词和1构成元组
reduceByKey(_+_)按照key进行reduce,并将value累加
saveAsTextFile("/spark/out")将结果写入到hdfs中
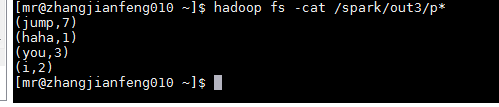
 执行结果查看
执行结果查看