3 容器
学习目标
1. 能够说出容器类型有什么用
2. 能够说出常用 Python 容器的名字
3. 能够说出切片语法的用途
4. 能够说出容器中的索引指的是什么
5. 能够说出如何定义一个字符串
6. 能够说出字符串容器的特性
7. 能够说出至少5个字符串方法名字和作用
8. 能够使用切片语法获得指定索引区间的子串
9. 能够说出如何使用 while 和 for 循环来遍历字符串
10. 能够说出如何定义一个列表
11. 能够说出列表容器和字符串容器的区别
12. 能够说出至少5个列表方法名字和作用
13. 能够使用切片语法获得列表指定索引区间的元素
14. 能够说出如何使用 while 和 for 循环来遍历列表中的元素
15. 能够说出如何定义一个列表
16. 能够说出元组和列表的区别
17. 能够说出如何使用 while 和 for 循环来遍历元组中的元素
18. 能够说出元组支持哪些操作
19. 能够说出如何定义一个字典
20. 能够说出字典和列表的区别
21. 能够说出如何使用 for 循环来遍历列表中的键、值和键值
22. 能够说出字典键和值的特点
容器分类?
学习容器类型就是在学习容器的特点、以及容器对元素的操作
为了便于学习, 我们根据不同容器的特性, 将常用容器分为序列式容器和非序列式容器
1. 序列式容器中的元素在存放时都是连续存放的, 也就是序列式容器中, 除了第一个元素的前面没有元素,
最后一个元素的后面没有元素, 其他所有的元素前后都有一个元素. 包括字符串、列表、元组
2. 非序列式容器在存储元素时不是连续存放的, 容器中的任何一个元素前后都可能没有元素. 包括字典、集合
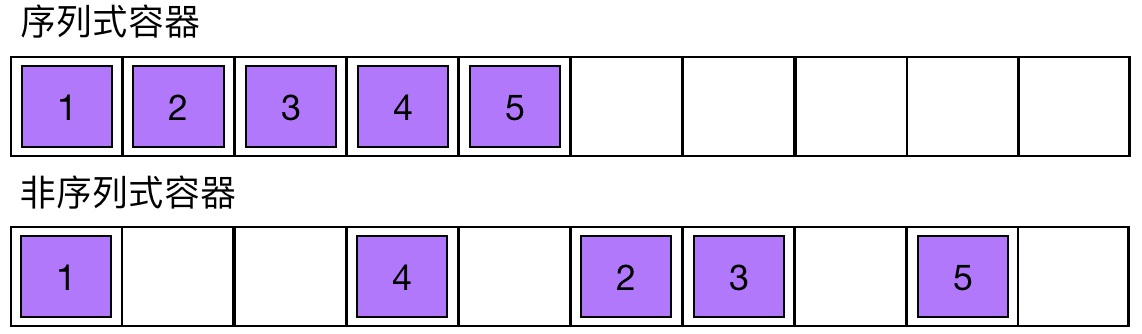
- 序列式容器支持根据索引(下标)访问元素, 而非序列式容器不支持索引(下标)的方式访问元素
- 序列式容器支持切片操作, 而非序列式容器不支持切片操作
什么是切片?
通过索引可以获取序列式容器中的某个元素, 切片语法主要用于获得一个指定索引区间的多个元素, 例如获取从索引值为 0 到索引值为 5 之间的所有元素
上面所说的 "方法", 就是我们所说所学的函数, 本质上 "方法"和"函数"指的是同一个东西
3.1 字符串
学习目标
1. 能够说出如何定义一个字符串
2. 能够说出字符串容器的特性
3. 能够说出如何对字符串中的子串进行替换
4. 能够说出如何对字符串中的字符串进行查找
5. 能够说出如何去除字符串两侧的空格
6. 能够说出如何判断字符串是否全部为字母
7. 能够说出字符串如何根据某个分隔符进行切分
8. 能够使用切片语法获得指定索引区间的子串
9. 能够说出如何使用 while 和 for 循环来遍历字符串
3.1.1 字符串语法格式
如何定义字符串?
1. 字符串使用一对单引号来定义
2. 字符串使用一对双引号来定义

3.1.2 字符串操作
1 字符串遍历
字符串属于序列式容器, 支持依据索引的操作
注意: 序列式容器的索引都是以 0 开始的, 并不是从 1 开始
my_string = '我叫做司马相如,我今年16岁了!' i = 0 while i < len(my_string): print(my_string[i], end=' ') i += 1
Python 是一门简单易用的语言, 对于容器的遍历, 提供了另外一种简单方式, for 循环
my_string = '我叫做司马相如,我今年16岁了!' for ch in my_string: print(ch, end=' ')
2 字符串替换
使用字符串的 replace 方法完成上面两步. 该方法默认会将字符串中所有指定字符或子串替换为新的字符串,
我们可以指定第三个参数, 替换多少次
poetry = '远看泰山黑乎乎, 上头细来下头粗. 茹把泰山倒过来, 下头细来上头粗. 茹' # 将所有的 '茹' 替换为 '如' right_poetry = poetry.replace('茹', '如') # 只替换第一次出现的 '茹' right_poetry = poetry.replace('茹', '如', 1)
3 字符串查找和切片
现在有一邮箱地址如下:
user_email = '[email protected]’
我们希望从邮箱地址字符串中获取用户名和邮箱后缀名, 那么这个问题如何解决?
1. 由分析可知, @符号之前为用户名, @符号之后的内容为邮箱后缀名
2. 首先获得 @ 符号的位置, 从开始位置截取到 @ 符号位置, 即可获得用户
3. 从 @ 符号位置开始截取到字符串最后, 即可获得邮箱后缀名
如何获得 @ 符号的位置?
可以使用字符串提供的 find 方法, 该方法可返回查找字符串第一次出现的位置, 查找字符串不存在则会返回-1
备注: find 方法默认从字符串开始位置(0位置)开始查找, 我们也可以指定从哪个位置范围开始查找, 设置 find 的
第二个参数表示从哪个位置开始查找, 第三个参数, 表示查找结束位置
poetry = '远看泰山黑乎乎, 上头细来下头粗. 茹把泰山倒过来, 下头细来上头粗.' # 从 10 位置开始查找 '上' position = poetry.find('上', 10, 100)
如何获得指定范围的字符串?
字符串属于序列式容器, 可以根据索引获得某一个字符, 也可以根据由两个索引标识的区间获得区间内的字符序列


poetry = '远看泰山黑乎乎, 上头细来下头粗. 茹把泰山倒过来, 下头细来上头粗.' # 从0位置开始到7位置之前, 不包含7位置字符 print(poetry[0: 7]) # 起始位置不写, 默认就是0 print(poetry[: 7]) # 从0位置开始到最后, 结束位置不写默认字符最后一个位置的下一个位置. print(poetry[9:]) # 步长, 每隔2个字符选取一个字符, 组成一个序列 print(poetry[0: 7: 2]) # 如果步长为负数, 那么起始位置参数和结束位置参数就会反过来. print(poetry[6:: -1]) # 位置也可以使用负数 print(poetry[-3: -1]) print(poetry[-3:]) print(poetry[::-1])
下面我们看看如何解决这个问题?
user_email = '[email protected]' # 查找 @ 位置 position = user_email.find('@') # 根据 postion 截取用户名和邮箱后缀 user_name = user_email[: position] mail_suffix = user_email[position + 1:]
另外一种解决该问题的思路
1. 先根据 @ 符号将邮箱分割成两部分
2. 分别获取每一部分, 即可得到用户名和邮箱后缀
user_email = '[email protected]' # 判断 user_email 是否有多个 @ at_count = user_email.count('@') if at_count > 1: print('邮箱地址不合法, 出现了多个@符号!') else: # 根据 @ 将字符串截取为多个部分 result = user_email.split('@') # 输出用户名和邮箱后缀 print(result[0], result[1])
4 字符串去除两侧空格、是否为字母
我们经常在各个网站进行会员注册, 一般注册的处理流程如下:
1. 获得用户输入的注册用户名
2. 用户在输入用户名时, 可能在用户名两个不小心输入多个空格. 我们需要去除用户名两侧的空格
3. 判断用户名是否全部为字母(用户名的组成由我们来规定, 这里我们规定必须是字母)
4. 处理完毕之后, 显示注册成功
# 获得用户注册用户名 register_username = input('请输入您的用户名:') # 去除用户名两侧的空格 register_username = register_username.strip() # 判断字符串是否全部为字母 if register_username.isalpha(): print('恭喜您:', register_username, '注册成功!') else: print('注册失败!')