webmagic学习资料:http://webmagic.io/docs/
原本爬虫的计划是去扒b站的,结果发现b站是js动态加载的,所以先对豆瓣进行尝试,练一下手.
整个项目核心是DoubanProcessor的这个类,继承了webmagic的PageProcessor
其他是自己实现数据库持久化的.
下面附上DoubanProcessor代码,具体思路在注释里,代码后附上练习中遇到的几个常见问题.
爬的页面是:https://www.douban.com/doulist/3907668/
先来看豆列单项:
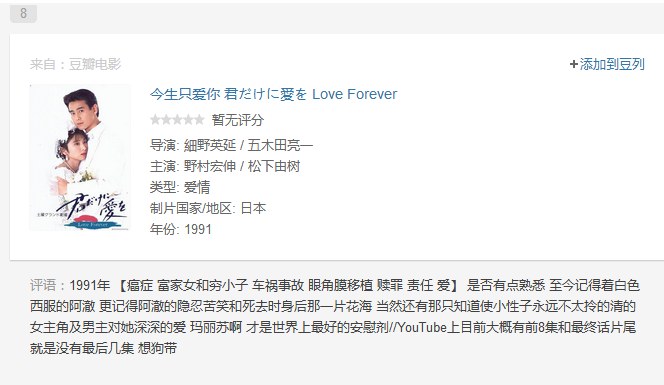
再来看豆列的html代码pattern:
1 <div class="post"> 2 <a href="https://movie.douban.com/subject/6080802/" target="_blank"> 3 <img width="100" src="https://img1.doubanio.com/view/subject/l/public/s4695449.jpg"/> 4 </a> 5 </div> 6 <div class="title"> 7 <a href="https://movie.douban.com/subject/6080802/" target="_blank"> 8 今生只爱你 君だけに愛を Love Forever 9 </a> 10 </div> 11 12 <div class="rating"> 13 <span class="allstar00"></span> 14 <span>暂无评分</span> 15 </div> 16 <div class="abstract"> 17 18 导演: 細野英延 / 五木田亮一 19 <br /> 20 主演: 野村宏伸 / 松下由树 21 <br /> 22 类型: 爱情 23 <br /> 24 制片国家/地区: 日本 25 <br /> 26 年份: 1991 27 </div>
以下我的DoubanProcessor实现:
1 public class DoubanProcessor implements PageProcessor{ 2 private Site site = Site.me().setUserAgent("Mozilla/5.0 (Windows NT 10.0; WOW64; rv:56.0) Gecko/20100101 Firefox/56.0").setRetryTimes(3).setSleepTime(1000); 3 4 @Override 5 public void process(Page page) { 6 List<String> titles = page.getHtml().xpath("//div[@class='title']/a/text()").all(); //这是匹配标题 7 List<String> movieUrls = page.getHtml().xpath("//div[@class='post']/a").links().all(); //这是匹配电影url 8 List<String> ratings = page.getHtml().xpath("//div[@class='rating']/span[@class='rating_nums']/text()").all(); //这是匹配评分 9 List<String> attrFields = page.getHtml().xpath("//div[@class='abstract']").all(); //这是匹配下方的abstract标签里的属性项 10 for (int i = 0; i < titles.size(); i++) { //循环存储到数据库 11 DoubanList doubanList=new DoubanList(); 12 doubanList.setTitle(titles.get(i)); 13 doubanList.setMovieUrl(movieUrls.get(i)); 14 doubanList.setRating(ratings.get(i)); 15 String[] movieAttrs = attrFields.get(i).split("<br>"); 16 if(movieAttrs.length>4) { 17 doubanList.setDirector(movieAttrs[0].substring(23).trim()); 18 doubanList.setActor(movieAttrs[1].trim()); 19 doubanList.setType(movieAttrs[2].trim()); 20 doubanList.setTime(movieAttrs[4].substring(0, 9).trim()); 21 }else { 22 doubanList.setDirector(attrFields.get(i)); 23 } 24 DoubanListDao.save(doubanList); 25 } 26 } 27 28 @Override 29 public Site getSite() { 30 return site; 31 } 32 33 public static void main(String[] args) { 34 Spider.create(new DoubanProcessor()) 35 .addUrl("https://www.douban.com/doulist/3907668/") //设置爬的url 36 .addPipeline(new ConsolePipeline()) //会output到控制台...在这里并不需要,因为持久化到数据库了 37 .thread(5) 38 .run(); 39 } 40 }
下面讲讲过程中遇到的问题:
1)403问题:我看了很多博文,发现其实全是互相抄袭.如果尝试的网站不同,你会发现你很容易遇到403问题.也就是返回status code为403,网站拒绝访问.其实原因是我们的工具请求没有携带相应的header,所以我在site里调用setUserAgent去设置了UA,至于UA的参数,是从自己的浏览器直接抓包复制过来的.于是问题解决了.
实际上,访问过快也可能造成403,在一些情况下还需要带cookie/多个IP爬等等.
2)匹配多个的问题:看很多文章的时候,基本都是直接page.getHtml().xpath()然后调用get() 或者toString(),实际上看代码发现,这里只能拿一个数据,而我需要匹配多个,因此要使用all();
Selectable接口注释:
1 /** 2 * multi string result 3 * 4 * @return multi string result 5 */ 6 public List<String> all();
解决了这些问题,其实还有一个问题.
豆瓣的电影格式,会存在没有导演,主演等信息的情况!!!....所以很坑....所以我添加了数组长度判断,防止越界,而且实在电影属性少的时候,就直接存到DB的director字段里.下面是数据库储存概括:

下次开始尝试爬B站!