1、webdriver.Chrome设置无界面模式
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(chrome_options=chrome_options)
driver.get("https://www.baidu.com")
2、webdriver.Chrome 打开开发者模式
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches',
['enable-automation'])
options.add_argument('lang=zh_CN.UTF-8')
options.add_argument(
'user-agent="Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36"')
browser = webdriver.Chrome(chrome_options=options)
browser.get('https://www.zhihu.com/signup?next=%2F')
3、js代码识别Selenium+Webdriver及其应对方案
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = Chrome(options=option)
4.xpath的一个小技巧
- 包含某个字符串的属性的标签如何提取? 如:提取出所有class属性包含 “i”的div标签
div_list = response.xpath("//div[contains(@class, 'i')]")
- 取出文本是“>”的a标签的href属性
next_url = response.xpath("//a[text()='>']/@href").extract_first()
- extract_first()
xpath提取到的时候返回null, 拿得到的时候返回第一个字符串
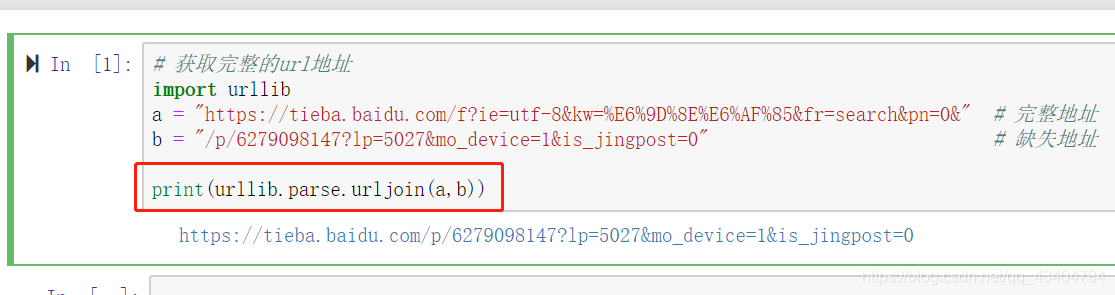
5.拼接完整的url地址