Python爬虫常见问题总结
问题一
背景:链接:https://blog.csdn.net/xxzj_zz2017/article/details/79739077
怎么都无法测试成功
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 8 08:46:45 2018
@author: zwz
"""
#参考网站:https://blog.csdn.net/xxzj_zz2017/article/details/79739077、
from splinter.browser import Browser
from bs4 import BeautifulSoup
import pandas as pd
import time
from PIL import Image
import time
import snownlp
import jieba
import jieba.analyse
import numpy as np
import re
import requests
from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator
b = Browser()
url0 = "https://book.douban.com/subject/bookid/comments/hot?p="#bookid换成你自己想要爬取的书籍的评论数据
list_1 = []
list_2 = []
for i in range(1,3):
url = "https://book.douban.com/subject/25862578/comments/hot?p="+str(i)
#b.visit(url)
soup = BeautifulSoup(b.driver.page_source, "html.parser")
comments = soup.find_all("p","comment-content")
for item in comments:
comment = item.string#评论内容
list_1.append(comment)
print(list_1)
pattern = re.compile('span class="user-stars allstar(.*?) rating"')
p = re.findall(pattern,b.driver.page_source)
list_2 += list(map(int,p))
time.sleep(4)
print("平均分:",sum(list_2)//len(list_2))
pd1 = pd.DataFrame(list_1)
pd1.to_csv("comments.csv",index = False)
pd2 = pd.DataFrame(list_2)
pd2.to_csv("result.csv",index=False)
print("yes")
comments = ""
for item in list_1:
item = item.strip(" ")
nlp = snownlp.SnowNLP(item)
comments += " ".join(jieba.analyse.extract_tags(item,6))#关键字提取
back_coloring = np.array(Image.open("jyzhd.jpg"))
word_cloud = WordCloud(font_path='simkai.ttf',background_color='white',max_words=2000,mask=back_coloring,margin=10)
word_cloud.generate(comments)
#从背景图片生成颜色值
image_colors = ImageColorGenerator(back_coloring)
plt.figure(figsize=(8,5),dpi=160)
plt.imshow(word_cloud.recolor(color_func=image_colors))
plt.axis("off")
plt.show()
word_cloud.to_file("comments.jpg")
运行出现的问题:
70)
解决了一小时,还是没解决,现放下问题,等待有缘人解决。
问题二
链接背景:https://mp.weixin.qq.com/s/E4EEgmQverifK5mc6W8onw
代码在这:百度云链接:https://pan.baidu.com/s/17zlP3AMNCQdvEQpU7Rx_tw 提取码:9z9q
问题程序:
# -*- coding: utf-8 -*-
"""
Created on Mon Sep 10 19:36:24 2018
@author: hzp0625
"""
from selenium import webdriver
import pandas as pd
from datetime import datetime
import numpy as np
import time
import os
os.chdir('D:\data_work')
def gethtml(url):
browser = webdriver.PhantomJS(executable_path="F:\Study_software\Anaconda\setup\Lib\site-packages\selenium\webdriver\phantomjs")
browser.get(url)
browser.implicitly_wait(10)
return(browser)
def getComment(url):
browser = gethtml(url)
i = 1
AllArticle = pd.DataFrame(columns = ['id','author','comment','stars1','stars2','stars3','stars4','stars5','unlike','like'])
print('连接成功,开始爬取数据')
while True:
xpath1 = '//*[@id="app"]/div[2]/div[2]/div/div[1]/div/div/div[4]/div/div/ul/li[{}]'.format(i)
try:
target = browser.find_element_by_xpath(xpath1)
except:
print('全部爬完')
break
author = target.find_element_by_xpath('div[1]/div[2]').text
comment = target.find_element_by_xpath('div[2]/div').text
stars1 = target.find_element_by_xpath('div[1]/div[3]/span/i[1]').get_attribute('class')
stars2 = target.find_element_by_xpath('div[1]/div[3]/span/i[2]').get_attribute('class')
stars3 = target.find_element_by_xpath('div[1]/div[3]/span/i[3]').get_attribute('class')
stars4 = target.find_element_by_xpath('div[1]/div[3]/span/i[4]').get_attribute('class')
stars5 = target.find_element_by_xpath('div[1]/div[3]/span/i[5]').get_attribute('class')
date = target.find_element_by_xpath('div[1]/div[4]').text
like = target.find_element_by_xpath('div[3]/div[1]').text
unlike = target.find_element_by_xpath('div[3]/div[2]').text
comments = pd.DataFrame([i,author,comment,stars1,stars2,stars3,stars4,stars5,like,unlike]).T
comments.columns = ['id','author','comment','stars1','stars2','stars3','stars4','stars5','unlike','like']
AllArticle = pd.concat([AllArticle,comments],axis = 0)
browser.execute_script("arguments[0].scrollIntoView();", target)
i = i + 1
if i%100 == 0:
print('已爬取{}条'.format(i))
AllArticle = AllArticle.reset_index(drop = True)
return AllArticle
url = 'https://www.bilibili.com/bangumi/media/md102392/?from=search&seid=8935536260089373525#short'
result = getComment(url)
#result.to_csv('工作细胞爬虫.csv',index = False)
问题截屏:
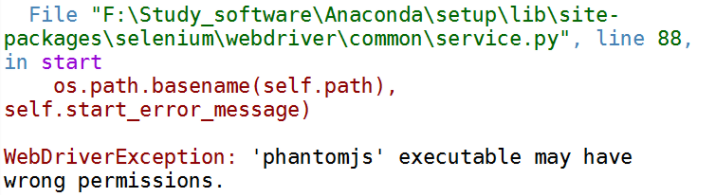
解决办法:
1.首先,先自己安装:pip install phantomjs (我是在anconda的基础上进行的,windows 64)
2.发现,无法全部安装成功,特别是这个phantomjs.exe
最后,通过查询网上,该网址:https://stackoverflow.com/questions/37903536/phantomjs-with-selenium-error-message-phantomjs-executable-needs-to-be-in-pa
有较好的解决办法,我是通过其中的它给出的网址,进行下载相应的phantomjs.exe。
我最后把上面的那句,更改为:
browser = webdriver.PhantomJS(executable_path="F:\Study_software\Anaconda\setup\Lib\site-packages\selenium\webdriver\phantomjs\phantomjs.exe")
就是把最后的指向是指向一个.exe文件,结果就可以了。
问题三:
我发现原来词云的生成效果是与图片的高清程度是有关的。
如果有需要,可以去看一下,我的文章:https://blog.csdn.net/weixin_38809485/article/details/83892939
分享一个下载高清图片的网站:https://unsplash.com/
区别:

