元数据冷备份
冷备份的起因:
namenode负责HDFS集群的元数据管理,要保证快速检索,namenode必须将数据放到内存中,但一旦断电或者故障,元数据会全部丢失,因此还必须在磁盘上做持久化。HDFS集群做元数据持久化的方式是edits.log+FSImage。edits.log存储近期的操作,FSImage存储以前的操作,这样是为了尽可能地保障namenode的启动速度。
总而言之,原因为:
- 避免NameNode中的元数据丢失;
- 尽可能保障NameNode的启动速度。
前言:
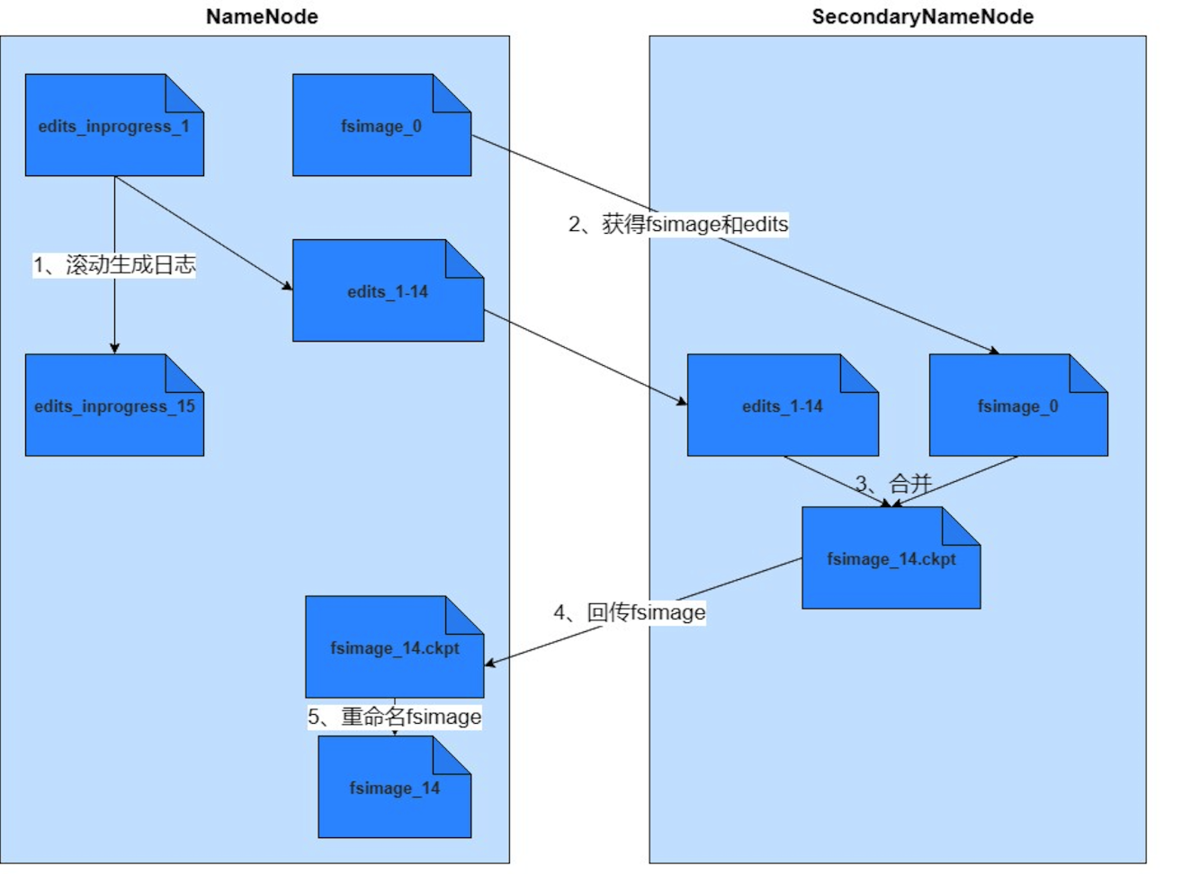
NameNode和SecondaryNameNode触发进行冷备份的条件:
- 时间达到你在配置文件中配置的时间(eg:6h);
- edits.log已经达到的配置文件中配置的指定大小(eg:64M)。
- SecondaryNameNode通过周期性(5min)通过getEditLog获取editLog的大小,当其达到合并的大小时通过RollEditLog进行合并;
- NameNode停止使用editLog文件,并生成一个新的临时文件edit.new;
- SecondaryNameNode通过NameNode内建的Http服务器,以get的方法获取editLog与fsimage文件(get方法中携带fsimage与editLog的路径);
- SecondaryNameNode将fsimage载入内存并逐一执行editlog中的操作;
- 执结束后,会向NameNode发送Http请求,通知NameNode合并结束,NameNode通过Http get方法获取新的fsimage.chk文件;
- NameNode更新fsimage文件中的记录检查点执行的时间,并改名为fsimage文件;
- editLog.new文件改名为edit。